Why is the universe comprehensible? Wigner referred to this as the “unreasonable effectiveness of mathematics in the natural sciences”, and even Einstein is famous for writing, in 1936, that “[t]he eternal mystery of the world is its comprehensibility… The fact that it is comprehensible is a miracle.” At a philosophical level however, this follows inexorably from the fact that reality is subject to certain inescapable features. To wit, the universe is comprehensible because it is logical; it cannot be otherwise (double entendre very much intended!).
At the level of physics however, this is not enough, for nowhere is it a priori guaranteed that a complete UV description of the world — namely, a full theory of quantum gravity — is not necessary to understand our low-energy lives. This does not prevent a sufficiently intelligent observer from comprehending the world in principle, of course (nor restore profundity to the equivalence class of misguided philosophy represented above), but it does pose a formidable problem in practice. The simple argument from separation of scales, in other words, cannot be so blithely accepted. Enter the renormalization group.
One of the first puzzles one encounters in QFT is the problem of UV and IR divergences. The latter arises due to the infinite number of degrees of freedom integrated over all space. For free field theory in 3+1 dimensions for example, the expectation value of the Hamiltonian has a divergence of the form

where  is the (infinite!) spatial volume and
is the (infinite!) spatial volume and 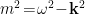 (and we have assumed the normalization
(and we have assumed the normalization ![{[a_k,a_{k'}^\dagger]=(2\pi)^32\omega\delta^3\left(\mathbf{k}-\mathbf{k}'\right)}](https://s0.wp.com/latex.php?latex=%7B%5Ba_k%2Ca_%7Bk%27%7D%5E%5Cdagger%5D%3D%282%5Cpi%29%5E32%5Comega%5Cdelta%5E3%5Cleft%28%5Cmathbf%7Bk%7D-%5Cmathbf%7Bk%7D%27%5Cright%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) ). This is clearly divergent: the energy of the ground state oscillators
). This is clearly divergent: the energy of the ground state oscillators  integrated over all space is infinite. But since only energy differences are measurable, we simply renormalize away this infinite factor by demanding that all operators be normal ordered. In flat space, one can think of this as simply subtracting off the infinite vacuum divergence (though in curved spacetime one cannot be so cavalier). Alternatively, one can put the system in a box of finite size
integrated over all space is infinite. But since only energy differences are measurable, we simply renormalize away this infinite factor by demanding that all operators be normal ordered. In flat space, one can think of this as simply subtracting off the infinite vacuum divergence (though in curved spacetime one cannot be so cavalier). Alternatively, one can put the system in a box of finite size  (i.e.,
(i.e., 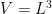 ), and consider the limit
), and consider the limit 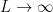 . In this case, acts as an IR cutoff on the modes—excitations whose energy is below the cutoff scale
. In this case, acts as an IR cutoff on the modes—excitations whose energy is below the cutoff scale 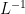 simply don’t fit.
simply don’t fit.
The UV divergences, in contrast, are not so easily tamed. Unlike the IR divergence, which we traced back to the zero-point energy of the vacuum, the UV divergences pose serious problems for the finiteness of the perturbative expansion. For even in a process in which all external momenta are small, momentum conservation at each vertex still allows arbitrarily high momenta to circulate in loops. Thus, even the first-order correction to the scalar propagator in, say,  theory would seem to depend on the details of arbitrarily high-energy physics.
theory would seem to depend on the details of arbitrarily high-energy physics.
Consistent management of these UV divergences is accomplished in field theory via the dual framework of regularization and renormalization. The latter gives rise to the renormalization group (RG), which serves as our quantum field-theoretic understanding of why it is possible to do physics — i.e., to understand the world — at all.
Regularization is the process of removing divergences by some systematic procedure—for example, the imposition of a cutoff as in the IR regularization above. Subsequently, renormalization is performed to adjust the parameters accordingly; the original, bare parameters are infinite, while the renormalized parameters correspond to what one actually measures at a particular (finite) energy scale. Of course, the final result should not depend on the details of the regularization scheme. Thus for example, if  is a position-space UV regulator, then a sensible regularization procedure requires that the theory has a well-defined limit as
is a position-space UV regulator, then a sensible regularization procedure requires that the theory has a well-defined limit as  . In most cases, terms like
. In most cases, terms like 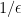 spoil this behaviour, in which case renormalization is used to relate the regularized expressions to observed values—essentially by accounting for self-interactions (crudely speaking, it “renormalizes” the couplings, in the colloquial sense of the word). The existence of such a well-defined limit, and the independence of the final result from the regulator, are highly non-trivial facts, and indeed may be thought of as a concrete manifestation of the miracle of comprehensibility perceived by Einstein above. These facts stem from universality (as in, the universality of dynamical systems), to which the RG flow endows a specific definition, as we shall see.
spoil this behaviour, in which case renormalization is used to relate the regularized expressions to observed values—essentially by accounting for self-interactions (crudely speaking, it “renormalizes” the couplings, in the colloquial sense of the word). The existence of such a well-defined limit, and the independence of the final result from the regulator, are highly non-trivial facts, and indeed may be thought of as a concrete manifestation of the miracle of comprehensibility perceived by Einstein above. These facts stem from universality (as in, the universality of dynamical systems), to which the RG flow endows a specific definition, as we shall see.
The explanation for universality, as well as the most elegant formulation of the combined regularization and renormalization procedure, is the Wilsonian RG. One begins with the generating functional,
![\displaystyle Z[J]=\int\mathcal{D}\phi e^{-S_E[\phi]+\int\mathrm{d}^dxJ(x)\phi(x)}~, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5BJ%5D%3D%5Cint%5Cmathcal%7BD%7D%5Cphi+e%5E%7B-S_E%5B%5Cphi%5D%2B%5Cint%5Cmathrm%7Bd%7D%5EdxJ%28x%29%5Cphi%28x%29%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  is the Euclidean action, and imposes a momentum-space cutoff
is the Euclidean action, and imposes a momentum-space cutoff  such that
such that
![\displaystyle Z[J]=\int\mathcal{D}\phi_{|k|<\Lambda} e^{-S_E^{\mathrm{eff}}[\phi;\Lambda]+\int\mathrm{d}^dxJ(x)\phi(x)}~, \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5BJ%5D%3D%5Cint%5Cmathcal%7BD%7D%5Cphi_%7B%7Ck%7C%3C%5CLambda%7D+e%5E%7B-S_E%5E%7B%5Cmathrm%7Beff%7D%7D%5B%5Cphi%3B%5CLambda%5D%2B%5Cint%5Cmathrm%7Bd%7D%5EdxJ%28x%29%5Cphi%28x%29%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
where

and the Wilsonian effective action is
![\displaystyle e^{-S_E^{\mathrm{eff}}[\phi;\Lambda]}=\int\mathcal{D}\phi_{|k|>\Lambda}e^{-S_E[\phi]}~. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+e%5E%7B-S_E%5E%7B%5Cmathrm%7Beff%7D%7D%5B%5Cphi%3B%5CLambda%5D%7D%3D%5Cint%5Cmathcal%7BD%7D%5Cphi_%7B%7Ck%7C%3E%5CLambda%7De%5E%7B-S_E%5B%5Cphi%5D%7D%7E.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
The path integral now includes only modes with  , while all the modes above this scale have been integrated out in the effective action. This is the manner in which the twin goals of regularization and renormalization are achieved. The cutoff removes the UV divergence from the path integral, but since physical quantities cannot depend on , the couplings are rescaled in the effective action in such a way as to cancel out any explicit dependence. In other words, integrating out the UV modes imposes a -dependence on the couplings, which is quantified by the beta function:
, while all the modes above this scale have been integrated out in the effective action. This is the manner in which the twin goals of regularization and renormalization are achieved. The cutoff removes the UV divergence from the path integral, but since physical quantities cannot depend on , the couplings are rescaled in the effective action in such a way as to cancel out any explicit dependence. In other words, integrating out the UV modes imposes a -dependence on the couplings, which is quantified by the beta function:

As an aside, note that unlike in canonical approaches such as cutoff or dimensional regularization, where the cutoff is merely a computational tool, in the Wilsonian approach the cutoff corresponds to a physical scale. In condensed matter systems for example, it corresponds to the lattice spacing, which provides a natural UV regulator. In high-energy systems, it corresponds to the energy scale at which the effective action breaks down.
The dependence of the couplings on the energy scale given by the beta function is known as the running of the couplings. To understand this, consider what happens as we lower the cutoff from to  , with
, with  . Clearly, Fourier modes
. Clearly, Fourier modes 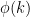 between
between 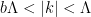 will be integrated out in the effective action
will be integrated out in the effective action ![{S_E^\mathrm{eff}[\phi;b\Lambda]}](https://s0.wp.com/latex.php?latex=%7BS_E%5E%5Cmathrm%7Beff%7D%5B%5Cphi%3Bb%5CLambda%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , while the path integral measure now runs over
, while the path integral measure now runs over  . Note that we also set
. Note that we also set  for
for  . At this level, one can see that the process of integrating out high-energy degrees of freedom is associative: a subsequent reduction to
. At this level, one can see that the process of integrating out high-energy degrees of freedom is associative: a subsequent reduction to  with
with  from our current point is equivalent to directly integrating out all modes above . Furthermore, while modes above the cutoff scale are no longer explicitly present in the effective action, their physics is encoded in the renormalization of the parameters. The beta function above is essentially a description of how these parameters depend on the coupling as we lower the cutoff scale, progressively integrating out more and more high-energy modes in the process.
from our current point is equivalent to directly integrating out all modes above . Furthermore, while modes above the cutoff scale are no longer explicitly present in the effective action, their physics is encoded in the renormalization of the parameters. The beta function above is essentially a description of how these parameters depend on the coupling as we lower the cutoff scale, progressively integrating out more and more high-energy modes in the process.
Note that since we integrate out degrees of freedom in the course of flowing from the UV to the IR, Wilsonian renormalization is in fact a form of coarse graining, and entails an irreversible loss of information. In this sense, the renormalization group is really only a half a group: once one flows to the IR, one can’t flow back. The key is that this loss of information is undetectable to any low-energy observer: the renormalization prescription is designed so that correlation functions below the cutoff are preserved. Hence the name effective field theory to describe the resulting theory, which is effectively valid up to the cutoff, but not beyond.
Actually computing the beta function requires a calculation in perturbation theory, in particular the isolation of the aforementioned loop divergences. To take the well-known example of theory, the Feynman rules lead to the following one-loop correction to the 2-pt function:

where 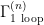 is the generator of one-particle irreducible (1PI)
is the generator of one-particle irreducible (1PI)  -point correlation functions (note that this is unfortunately sometimes also called the “effective action”, not to be confused with
-point correlation functions (note that this is unfortunately sometimes also called the “effective action”, not to be confused with 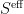 ), written here in Euclidean signature. Now, according to the RG prescription above, modes above the cutoff are integrated out, so for
), written here in Euclidean signature. Now, according to the RG prescription above, modes above the cutoff are integrated out, so for 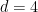 we would adjust the integration measure as
we would adjust the integration measure as

where the 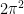 comes from the volume of the
comes from the volume of the 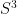 . However, while this particular integral can be readily evaluated within this restricted momentum range (see, for example, David Skinner’s Advanced QFT notes, chapter 6, “Perturbative Renormalization”), most expressions are much less tractable. (Consider, by way of analogy, that the simplicity of Gaussian integrals depends crucially on the infinite domain of integration). For this reason, in practice one usually resorts to other calculational methods, most commonly dimensional regularization. Let us see how this works for the case at hand.
. However, while this particular integral can be readily evaluated within this restricted momentum range (see, for example, David Skinner’s Advanced QFT notes, chapter 6, “Perturbative Renormalization”), most expressions are much less tractable. (Consider, by way of analogy, that the simplicity of Gaussian integrals depends crucially on the infinite domain of integration). For this reason, in practice one usually resorts to other calculational methods, most commonly dimensional regularization. Let us see how this works for the case at hand.
The integral above can be performed for general  to yield
to yield

which is clearly divergent for . Dimensional regularization deals with this by instead working in dimension  , and then considering the limit . By expanding in this limit, one can isolate the singular and non-singular contributions as
, and then considering the limit . By expanding in this limit, one can isolate the singular and non-singular contributions as

where  is the Euler-Mascheroni constant. Neglecting the finite parts, we therefore have
is the Euler-Mascheroni constant. Neglecting the finite parts, we therefore have
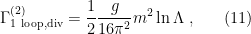
where, for future purposes, we’ve replaced the simple pole in with  (this is not an obvious replacement, but follows by comparing the result here with what one would have obtained in the cutoff prescription).
(this is not an obvious replacement, but follows by comparing the result here with what one would have obtained in the cutoff prescription).
The reason we only identify the beta function with the divergent piece is because, as stated above, we want to identify a function that describes the running of the couplings as we dial the energy scale. Furthermore, we want a description that does not depend on the details of our regularization scheme. With this in mind, observe that there are three kinds of terms in (10). The convergent (constant) terms have no dependence on the cutoff, and therefore won’t tell us anything about the running of the couplings. Terms that diverge as  to some positive power
to some positive power  , meanwhile, essentially give the relationship between the bare couplings and the renormalized values at a particular scale, but don’t tell us anything about the flow between scales. The log divergence is therefore the only interesting term in this regard: it isn’t associated with any particular scale (said differently, it receives contributions from all scales), and is insensitive to any scheme-dependent behaviour (such as exhibited in the constant terms). Before we proceed, it is worth noting that while dimensional regularization does provide a useful tool for regulating individual loop integrals over the full range
, meanwhile, essentially give the relationship between the bare couplings and the renormalized values at a particular scale, but don’t tell us anything about the flow between scales. The log divergence is therefore the only interesting term in this regard: it isn’t associated with any particular scale (said differently, it receives contributions from all scales), and is insensitive to any scheme-dependent behaviour (such as exhibited in the constant terms). Before we proceed, it is worth noting that while dimensional regularization does provide a useful tool for regulating individual loop integrals over the full range  , it does not guarantee finiteness of the path integral as in the Wilsonian approach (where the UV regime is simply absent). Additionally, while the Wilsonian cutoff has a physical interpretation as the energy scale, the non-integer status of the dimensions has no such ontic value. Nevertheless, it is of great practical convenience, particularly in gauge theories.
, it does not guarantee finiteness of the path integral as in the Wilsonian approach (where the UV regime is simply absent). Additionally, while the Wilsonian cutoff has a physical interpretation as the energy scale, the non-integer status of the dimensions has no such ontic value. Nevertheless, it is of great practical convenience, particularly in gauge theories.
Now, to continue our search for the beta function, let us repeat the above for the 1-loop contribution to the 4-point function,

which occurs at order 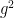 . The integral in this case is more involved, but can be managed with the use of Feynman’s trick,
. The integral in this case is more involved, but can be managed with the use of Feynman’s trick,

which is explained in, e.g., Jim Cline’s Advanced QFT notes. After a fair amount of work, dimensional regularization eventually yields
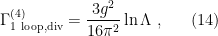
for the singular contribution.
Having regularized the divergences in (11) and (14), we must now renormalize the Lagrangian appropriately. The simplest means of doing so is the minimal subtraction scheme, wherein we only compensate for divergences arising at the one-loop level. The idea is to define a bare Lagrangian
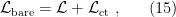
where 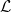 is the original Lagrangian, and
is the original Lagrangian, and  is the Lagrangian consisting of counterterms to compensate for divergences. In the present example of theory,
is the Lagrangian consisting of counterterms to compensate for divergences. In the present example of theory,

where the subscript zero denotes that the fields and couplings are bare quantities. These do not depend on , but include the contributions from divergences and are therefore infinite. This is in contrast to the renormalized quantities (without subscript) implicit on the r.h.s. of (15). We shall determine the precise relationship between the bare and renormalized parameters below; it relies on the fact that finite values for the latter are obtained through the introduction of the Lagrangian of counterterms,

where the coefficients  ,
,  , and
, and  , are fixed by our considerations above by observing that, at tree level, yields additional contributions to the vertex functions of the form
, are fixed by our considerations above by observing that, at tree level, yields additional contributions to the vertex functions of the form
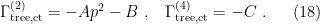
Therefore, if we wish to cancel the divergences (11) and (14), we must define

so that, to one-loop level, the total contribution  no longer has a divergence as
no longer has a divergence as  . (In the language of dimensional regularization, we’ve removed the simple pole at
. (In the language of dimensional regularization, we’ve removed the simple pole at 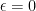 ).
).
Of course, had we gone beyond the minimal subtraction scheme to consider higher loops, additional counterterms would be required (for example, becomes non-trivial at 2-loops). But it turns out that the same basic idea can be performed systematically to all orders in perturbation theory. This is the subject of multiplicative renormalization, which consists in showing that all infinities can be reabsorbed in a finite number of coupling constants (including masses). Finite results are then obtained in the infinite cutoff limit, (equivalently in the dimensional approach), which corresponds to including the full UV regime of the original theory. Theories in which this program can be carried out successfully are called renormalizable. (In fact, renormalizability implies that all counterterms are of the same form as those in the original Lagrangian, which we already assumed in (17)). In contrast, theories requiring an infinite number of counterterms are non-renormalizable—gravity being the most notorious example.
To relate the bare quantities (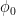 ,
,  ,
,  ) to the renormalized quantities (
) to the renormalized quantities ( ,
,  ,
,  ) requires one more piece of information, namely the behaviour of the kinetic term as we change the energy scale. Recalling the Wilsonian approach above, this term is no different than the others in that it receives quantum corrections as we integrate out UV modes. We thus define the field renormalization factor
) requires one more piece of information, namely the behaviour of the kinetic term as we change the energy scale. Recalling the Wilsonian approach above, this term is no different than the others in that it receives quantum corrections as we integrate out UV modes. We thus define the field renormalization factor  (not to be confused with the partition function
(not to be confused with the partition function  ), which depends on such that
), which depends on such that 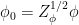 . (In fact, in the Wilsonian approach, this is sometimes labeled
. (In fact, in the Wilsonian approach, this is sometimes labeled  , to reflect the fact that at a new scale
, to reflect the fact that at a new scale 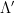 , renormalizing the field requires a different factor
, renormalizing the field requires a different factor  . But here we only care about the final result; again, the RG is associative). Now, comparing
. But here we only care about the final result; again, the RG is associative). Now, comparing  and , we have
and , we have
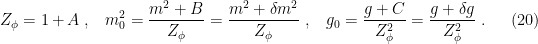
At this level, these expressions already describe how the couplings vary, but this is made more concrete in the renormalization group equation (a.k.a. the Callan-Symanzik equation), which we now derive.
First, observe that the field renormalization factor implies that the bare and renormalized -point correlators are related by an overall scaling,

which simply follows from the fact that there are -fields in the correlation function, i.e.,

Since 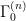 is independent of , it should remain unchanged under RG, hence
is independent of , it should remain unchanged under RG, hence

And therefore, by the chain rule,
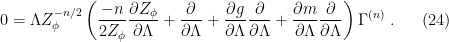
Multiplying through by  , we obtain the aforementioned RG equation,
, we obtain the aforementioned RG equation,

where we have defined

The first of these is the promised beta function, while  and are the anomalous dimension of the mass and field, respectively. The name stems from the fact that the renormalized correlation function behaves as if the field scaled with mass dimension
and are the anomalous dimension of the mass and field, respectively. The name stems from the fact that the renormalized correlation function behaves as if the field scaled with mass dimension  rather than
rather than  ; similarly for . Both of these can be viewed as beta functions for the mass and kinetic terms. The former, after all, is fundamentally no different. Indeed, it is a basic exercise to show that if one treats the mass as an interaction term and sums the resulting Feynman diagrams that contribute to the 2-point function to all orders in , one recovers the usual (massive) propagator.
; similarly for . Both of these can be viewed as beta functions for the mass and kinetic terms. The former, after all, is fundamentally no different. Indeed, it is a basic exercise to show that if one treats the mass as an interaction term and sums the resulting Feynman diagrams that contribute to the 2-point function to all orders in , one recovers the usual (massive) propagator.
As stated above, the beta function describes the running of the coupling as we flow from the UV to the IR. Operators that are suppressed as we flow into the IR are called irrelevant. Conversely, operators that becomes increasingly important are called relevant. At the border of these two regimes are operators which are unaffected by the energy scale, which are called marginal. (The terminology can be remembered by asking which operators are relevant, in the colloquial sense, for everyday life (i.e., low-energy physics)). Modulo one significant caveat that we’ll mention shortly, this behaviour can be read-off directly from the Lagrangian. Since the action must be dimensionless, and the measure  has mass dimension
has mass dimension  (and
(and ![{[\partial_\mu]=1}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cpartial_%5Cmu%5D%3D1%7D&bg=ffffff&fg=000000&s=0&c=20201002) ) the parameters in the Lagrangian must have
) the parameters in the Lagrangian must have
![\displaystyle [\phi]=\frac{d-2}{2}~,\;\;\;[m]=1~,\;\;\;[g]=d-4~. \ \ \ \ \ (27)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Cphi%5D%3D%5Cfrac%7Bd-2%7D%7B2%7D%7E%2C%5C%3B%5C%3B%5C%3B%5Bm%5D%3D1%7E%2C%5C%3B%5C%3B%5C%3B%5Bg%5D%3Dd-4%7E.+%5C+%5C+%5C+%5C+%5C+%2827%29&bg=ffffff&fg=000000&s=0&c=20201002)
However, the perturbative expansion relies on setting, e.g.,  , which makes no sense if is dimensionful. More generally, for a given coupling
, which makes no sense if is dimensionful. More generally, for a given coupling  with
with ![{[g_n]=d-n}](https://s0.wp.com/latex.php?latex=%7B%5Bg_n%5D%3Dd-n%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,  implies that the correct dimensionless parameter is
implies that the correct dimensionless parameter is  , and thus controls an interaction that becomes increasingly important at low energies
, and thus controls an interaction that becomes increasingly important at low energies 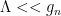 . In this case the hypothetical term
. In this case the hypothetical term  is relevant. Conversely,
is relevant. Conversely,  implies that we perform an expansion in
implies that we perform an expansion in 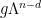 , in which case the interaction becomes less and less important as becomes small; hence, irrelevant. The marginal case is
, in which case the interaction becomes less and less important as becomes small; hence, irrelevant. The marginal case is 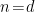 , in which case we really can expand in , since it’s already dimensionless.
, in which case we really can expand in , since it’s already dimensionless.
The aforementioned caveat is that quantum corrections can modify the RG behaviour of the coupling. In the example above, the classical mass dimension of the field in theory is modified by the anomalous dimension . In particular, one must watch out for marginal operators that become either marginally relevant or marginally irrelevant under RG. Such operators actually play an important role in phenomenology. More generally, the fact that operators can mix under RG flow is important in, for example, the possible emergence of gauge fields.
The existence of an infinite-dimensional space of theories whose coordinates is the set of all possible couplings in the effective action implies the existence of an infinite number of irrelevant operators. In contrast, since each additional field or derivative increases the dimension of an operator, there are only finitely many relevant operators (and typically very few). We define the critical surface to be the infinite-dimensional space in the UV where all relevant operators vanish (which has finite codimension, for the reason just stated). As we flow to the IR — which we might accomplish by perturbing away from the critical surface by the introduction of some relevant operator(s) — we follow a trajectory through the space of theories until we reach a critical or fixed point, where all beta functions vanish. If the beta function has a zero at 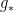 , and is positive for
, and is positive for 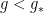 , then
, then  as . In this case, is a UV fixed point. Alternatively, if
as . In this case, is a UV fixed point. Alternatively, if  for , then
for , then  as ; since we dialed the energy in the same direction, it’s still a UV fixed point, but the vanishing of the coupling implies that the theory becomes asymptotically free, a feature that characterizes certain non-abelian gauge theories, notably QCD. An IR fixed point, in obvious contrast, is obtained from a similar analysis with
as ; since we dialed the energy in the same direction, it’s still a UV fixed point, but the vanishing of the coupling implies that the theory becomes asymptotically free, a feature that characterizes certain non-abelian gauge theories, notably QCD. An IR fixed point, in obvious contrast, is obtained from a similar analysis with  (though asymptotic freedom uniquely refers to the UV case).
(though asymptotic freedom uniquely refers to the UV case).
Another case that deserves mention is the possibility that the beta function diverges at some finite . This is an obvious pathology, since it implies that the coupling constant — i.e., the interaction strength — becomes infinite. But in fact, this is precisely what happens in our beloved theory, and is a common feature of theories which are not asymptotically free, such as QED. One possible solution to this is that the fully renormalized coupling actually goes to zero as we take the cutoff scale to infinity. The proposed mechanism by which this quantum triviality comes about is via vacuum fluctuations (essentially, corrections from the self-energy of the field), which completely screen the interaction in the absence of a cutoff. (This is sometimes referred to as charge screening, in analogy with electrodynamics). The alternative is to suppose that the perturbative expansion simply breaks down at strong coupling, since the pathology appears at one- or two-loop level, in which case non-perturbative methods must be used to address the issue, such as in lattice gauge theory. We don’t normally concern ourselves with triviality in theory, because the energy scale at which it occurs is inaccessibly high. However, field theories involving only a scalar Higgs boson in four dimensions also suffer from quantum triviality, but at a scale that may be accessible to the LHC; the possible inconsistency of such theories is an open area of research.
There is of course a great deal more to be said about the RG; see for example Skinner’s explanation for how it vastly simplifies the Feynman diagram expansion, or Polchinski’s interpretation of RG as a form of heat flow. There’s also the interesting fact that the RG flow entails a shift in the vacuum energy (Skinner, page 39), which suggests both complications for renormalization in curved spacetime as well as a tantalizing hint towards the emergence of the radial direction in AdS/CFT—namely, holography as RG flow, a fascinating research direction in its own right.


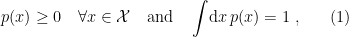
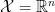

![{\xi=[\xi^i]=[\xi^1,\ldots,\xi^n]}](https://s0.wp.com/latex.php?latex=%7B%5Cxi%3D%5B%5Cxi%5Ei%5D%3D%5B%5Cxi%5E1%2C%5Cldots%2C%5Cxi%5En%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle S=\{p_\xi=p(x;\xi)\,|\,\xi=[\xi^i]\in\Xi\}~, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%3D%5C%7Bp_%5Cxi%3Dp%28x%3B%5Cxi%29%5C%2C%7C%5C%2C%5Cxi%3D%5B%5Cxi%5Ei%5D%5Cin%5CXi%5C%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)





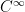

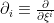




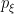
![\displaystyle p(x;\xi)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left[-\frac{\left(x-\mu\right)^2}{2\sigma^2}\right]~. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%3B%5Cxi%29%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%5Cexp%5Cleft%5B-%5Cfrac%7B%5Cleft%28x-%5Cmu%5Cright%29%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathcal{X}=\mathbb{R}~,\;\;n=2,\;\;\xi=[\mu,\sigma],\;\;\Xi=\{[\mu,\sigma]\,|\,\mu\in\mathbb{R},\;\sigma\in\mathbb{R}^+\}~. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BX%7D%3D%5Cmathbb%7BR%7D%7E%2C%5C%3B%5C%3Bn%3D2%2C%5C%3B%5C%3B%5Cxi%3D%5B%5Cmu%2C%5Csigma%5D%2C%5C%3B%5C%3B%5CXi%3D%5C%7B%5B%5Cmu%2C%5Csigma%5D%5C%2C%7C%5C%2C%5Cmu%5Cin%5Cmathbb%7BR%7D%2C%5C%3B%5Csigma%5Cin%5Cmathbb%7BR%7D%5E%2B%5C%7D%7E.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{G(\xi)=[g_{ij}(\xi)]}](https://s0.wp.com/latex.php?latex=%7BG%28%5Cxi%29%3D%5Bg_%7Bij%7D%28%5Cxi%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle g_{ij}(\xi)\equiv E_\xi[\partial_i\ell_\xi\partial_j\ell_\xi] =\int\!\mathrm{d} x\,\partial_i\ell(x;\xi)\partial_j\ell(x;\xi)p(x;\xi)~, \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7Bij%7D%28%5Cxi%29%5Cequiv+E_%5Cxi%5B%5Cpartial_i%5Cell_%5Cxi%5Cpartial_j%5Cell_%5Cxi%5D+%3D%5Cint%5C%21%5Cmathrm%7Bd%7D+x%5C%2C%5Cpartial_i%5Cell%28x%3B%5Cxi%29%5Cpartial_j%5Cell%28x%3B%5Cxi%29p%28x%3B%5Cxi%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)


![\displaystyle E_\xi[f]\equiv\int\!\mathrm{d} x\,f(x)p(x;\xi)~. \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%5Cxi%5Bf%5D%5Cequiv%5Cint%5C%21%5Cmathrm%7Bd%7D+x%5C%2Cf%28x%29p%28x%3B%5Cxi%29%7E.+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=0&c=20201002)
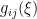


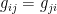


![\displaystyle E_\xi[\partial_i\ell_\xi]=0~. \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%5Cxi%5B%5Cpartial_i%5Cell_%5Cxi%5D%3D0%7E.+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle g_{ij}(\xi)=-E_\xi[\partial_i\partial_j\ell_\xi]~. \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7Bij%7D%28%5Cxi%29%3D-E_%5Cxi%5B%5Cpartial_i%5Cpartial_j%5Cell_%5Cxi%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)


![{[\xi^i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cxi%5Ei%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)





![\displaystyle \langle X,Y\rangle_\xi=E_\xi[(X\ell)(Y\ell)]\quad\forall X,Y\in T_\xi S~. \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+X%2CY%5Crangle_%5Cxi%3DE_%5Cxi%5B%28X%5Cell%29%28Y%5Cell%29%5D%5Cquad%5Cforall+X%2CY%5Cin+T_%5Cxi+S%7E.+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
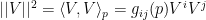
![{\gamma:[a,b]\rightarrow S}](https://s0.wp.com/latex.php?latex=%7B%5Cgamma%3A%5Ba%2Cb%5D%5Crightarrow+S%7D&bg=ffffff&fg=000000&s=0&c=20201002)
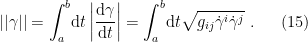


![\displaystyle \left(\Gamma_{ij,k}^{(\alpha)}\right)_\xi\equiv E_\xi\left[\left(\partial_i\partial_j\ell_\xi+\frac{1-\alpha}{2}\partial_i\ell_\xi\partial_j\ell_\xi\right)\left(\partial_k\ell_\xi\right)\right]~, \ \ \ \ \ (16)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%28%5CGamma_%7Bij%2Ck%7D%5E%7B%28%5Calpha%29%7D%5Cright%29_%5Cxi%5Cequiv+E_%5Cxi%5Cleft%5B%5Cleft%28%5Cpartial_i%5Cpartial_j%5Cell_%5Cxi%2B%5Cfrac%7B1-%5Calpha%7D%7B2%7D%5Cpartial_i%5Cell_%5Cxi%5Cpartial_j%5Cell_%5Cxi%5Cright%29%5Cleft%28%5Cpartial_k%5Cell_%5Cxi%5Cright%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2816%29&bg=ffffff&fg=000000&s=0&c=20201002)



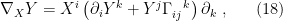

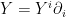



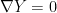


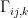




![\displaystyle \begin{aligned} \partial_kg_{ij}&=\partial_kE_\xi[\partial_i\ell_\xi\partial_j\ell_\xi]\\ &=E_\xi[\left(\partial_k\partial_i\ell_\xi\right)\left(\partial_j\ell_\xi\right)]+E_\xi[\left(\partial_i\ell_\xi\right)\left(\partial_k\partial_j\ell_\xi\right)]+E_\xi[\left(\partial_i\ell_\xi\right)\left(\partial_j\ell_\xi\right)\left(\partial_k\ell_\xi\right)]\\ &=\Gamma_{ki,j}^{(0)}+\Gamma_{kj,i}^{(0)}~, \end{aligned} \ \ \ \ \ (22)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cpartial_kg_%7Bij%7D%26%3D%5Cpartial_kE_%5Cxi%5B%5Cpartial_i%5Cell_%5Cxi%5Cpartial_j%5Cell_%5Cxi%5D%5C%5C+%26%3DE_%5Cxi%5B%5Cleft%28%5Cpartial_k%5Cpartial_i%5Cell_%5Cxi%5Cright%29%5Cleft%28%5Cpartial_j%5Cell_%5Cxi%5Cright%29%5D%2BE_%5Cxi%5B%5Cleft%28%5Cpartial_i%5Cell_%5Cxi%5Cright%29%5Cleft%28%5Cpartial_k%5Cpartial_j%5Cell_%5Cxi%5Cright%29%5D%2BE_%5Cxi%5B%5Cleft%28%5Cpartial_i%5Cell_%5Cxi%5Cright%29%5Cleft%28%5Cpartial_j%5Cell_%5Cxi%5Cright%29%5Cleft%28%5Cpartial_k%5Cell_%5Cxi%5Cright%29%5D%5C%5C+%26%3D%5CGamma_%7Bki%2Cj%7D%5E%7B%280%29%7D%2B%5CGamma_%7Bkj%2Ci%7D%5E%7B%280%29%7D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2822%29&bg=ffffff&fg=000000&s=0&c=20201002)



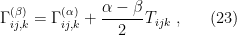

![\displaystyle \left(T_{ijk}\right)_\xi\equiv E_\xi[\partial_i\ell_\xi\partial_j\ell_\xi\partial_k\ell_\xi]~. \ \ \ \ \ (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%28T_%7Bijk%7D%5Cright%29_%5Cxi%5Cequiv+E_%5Cxi%5B%5Cpartial_i%5Cell_%5Cxi%5Cpartial_j%5Cell_%5Cxi%5Cpartial_k%5Cell_%5Cxi%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2824%29&bg=ffffff&fg=000000&s=0&c=20201002)

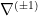
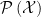


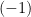




![\displaystyle p(x;\theta)=\exp\left[C(x)+\theta^iF_i(x)-\psi(\theta)\right]~, \ \ \ \ \ (26)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%3B%5Ctheta%29%3D%5Cexp%5Cleft%5BC%28x%29%2B%5Ctheta%5EiF_i%28x%29-%5Cpsi%28%5Ctheta%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2826%29&bg=ffffff&fg=000000&s=0&c=20201002)

![{[\theta^i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctheta%5Ei%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \psi(\theta)=\log\int\!\mathrm{d} x\,\exp\left[C(x)+\theta^iF_i(x)\right]~. \ \ \ \ \ (27)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpsi%28%5Ctheta%29%3D%5Clog%5Cint%5C%21%5Cmathrm%7Bd%7D+x%5C%2C%5Cexp%5Cleft%5BC%28x%29%2B%5Ctheta%5EiF_i%28x%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2827%29&bg=ffffff&fg=000000&s=0&c=20201002)


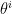

![\displaystyle \left(\Gamma_{ij,k}^{(1)}\right)_\theta=E_\theta[\left(\partial_i\partial_j\ell_\theta\right)\left(\partial_k\ell_\theta\right)] =-\partial_i\partial_j\psi(\theta)E_\theta[\partial_k\ell_\theta]=0~. \ \ \ \ \ (30)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%28%5CGamma_%7Bij%2Ck%7D%5E%7B%281%29%7D%5Cright%29_%5Ctheta%3DE_%5Ctheta%5B%5Cleft%28%5Cpartial_i%5Cpartial_j%5Cell_%5Ctheta%5Cright%29%5Cleft%28%5Cpartial_k%5Cell_%5Ctheta%5Cright%29%5D+%3D-%5Cpartial_i%5Cpartial_j%5Cpsi%28%5Ctheta%29E_%5Ctheta%5B%5Cpartial_k%5Cell_%5Ctheta%5D%3D0%7E.+%5C+%5C+%5C+%5C+%5C+%2830%29&bg=ffffff&fg=000000&s=0&c=20201002)

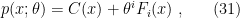
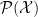


![\displaystyle p(x;\theta)=\theta^ip_i(x)+\left(1-\sum_{i=1}^n\theta^i\right)p_0(x) =p_0(x)+\sum_{i=1}^n\theta^i\left[p_i(x)-p_0(x)\right]~, \ \ \ \ \ (32)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%3B%5Ctheta%29%3D%5Ctheta%5Eip_i%28x%29%2B%5Cleft%281-%5Csum_%7Bi%3D1%7D%5En%5Ctheta%5Ei%5Cright%29p_0%28x%29+%3Dp_0%28x%29%2B%5Csum_%7Bi%3D1%7D%5En%5Ctheta%5Ei%5Cleft%5Bp_i%28x%29-p_0%28x%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2832%29&bg=ffffff&fg=000000&s=0&c=20201002)




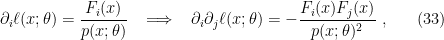

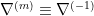











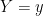





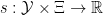
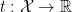

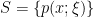
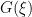




![{\Delta G(\xi)=[\Delta g_{ij}(\xi)]}](https://s0.wp.com/latex.php?latex=%7B%5CDelta+G%28%5Cxi%29%3D%5B%5CDelta+g_%7Bij%7D%28%5Cxi%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
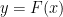
![\displaystyle \Delta g_{ij}(\xi)=E_\xi[\partial_i\ln r(X;\xi)\partial_j\ln r(X;\xi)]~, \ \ \ \ \ (39)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CDelta+g_%7Bij%7D%28%5Cxi%29%3DE_%5Cxi%5B%5Cpartial_i%5Cln+r%28X%3B%5Cxi%29%5Cpartial_j%5Cln+r%28X%3B%5Cxi%29%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2839%29&bg=ffffff&fg=000000&s=0&c=20201002)




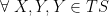



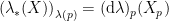
 -dimensional phase space
-dimensional phase space  , whose components parametrize the position and momentum of the system via the canonical variables
, whose components parametrize the position and momentum of the system via the canonical variables
![\displaystyle [x(\mathbf{a}),p(\mathbf{b})]=i(\mathbf{a}\cdot\mathbf{b})\mathbf{1}~,\qquad [x(\mathbf{a}),x(\mathbf{a}')]=[p(\mathbf{b}),p(\mathbf{b}')]=0~, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bx%28%5Cmathbf%7Ba%7D%29%2Cp%28%5Cmathbf%7Bb%7D%29%5D%3Di%28%5Cmathbf%7Ba%7D%5Ccdot%5Cmathbf%7Bb%7D%29%5Cmathbf%7B1%7D%7E%2C%5Cqquad+%5Bx%28%5Cmathbf%7Ba%7D%29%2Cx%28%5Cmathbf%7Ba%7D%27%29%5D%3D%5Bp%28%5Cmathbf%7Bb%7D%29%2Cp%28%5Cmathbf%7Bb%7D%27%29%5D%3D0%7E%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
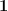 is the
is the 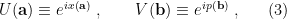


![\displaystyle W(\mathbf{a},\mathbf{b})W(\mathbf{a}',\mathbf{b}')=e^{-i\sigma[(\mathbf{a},\mathbf{b}),(\mathbf{a}',\mathbf{b}')]/2}W(\mathbf{a}+\mathbf{a}',\mathbf{b}+\mathbf{b}')~, \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+W%28%5Cmathbf%7Ba%7D%2C%5Cmathbf%7Bb%7D%29W%28%5Cmathbf%7Ba%7D%27%2C%5Cmathbf%7Bb%7D%27%29%3De%5E%7B-i%5Csigma%5B%28%5Cmathbf%7Ba%7D%2C%5Cmathbf%7Bb%7D%29%2C%28%5Cmathbf%7Ba%7D%27%2C%5Cmathbf%7Bb%7D%27%29%5D%2F2%7DW%28%5Cmathbf%7Ba%7D%2B%5Cmathbf%7Ba%7D%27%2C%5Cmathbf%7Bb%7D%2B%5Cmathbf%7Bb%7D%27%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{\sigma[(\mathbf{a},\mathbf{b}),(\mathbf{a}',\mathbf{b}')]\equiv\mathbf{a}'\cdot\mathbf{b}-\mathbf{a}\cdot\mathbf{b}'}](https://s0.wp.com/latex.php?latex=%7B%5Csigma%5B%28%5Cmathbf%7Ba%7D%2C%5Cmathbf%7Bb%7D%29%2C%28%5Cmathbf%7Ba%7D%27%2C%5Cmathbf%7Bb%7D%27%29%5D%5Cequiv%5Cmathbf%7Ba%7D%27%5Ccdot%5Cmathbf%7Bb%7D-%5Cmathbf%7Ba%7D%5Ccdot%5Cmathbf%7Bb%7D%27%7D&bg=ffffff&fg=000000&s=0&c=20201002) is none other than the familiar symplectic form on S. For completeness, one further defines
is none other than the familiar symplectic form on S. For completeness, one further defines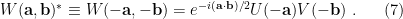
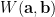 on a Hilbert space
on a Hilbert space 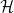 (more on what this means below) gives rise to a representation of the Weyl form of the canonical commutation relations, and vice-versa.
(more on what this means below) gives rise to a representation of the Weyl form of the canonical commutation relations, and vice-versa. of unitary operators acting in some Hilbert space
of unitary operators acting in some Hilbert space  satisfies the Weyl relations iff
satisfies the Weyl relations iff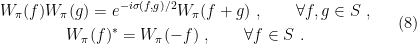
 denotes the representation. The idea behind a representation is to make an abstract algebra more concrete by representing the elements thereof as matrices; i.e., a representation reduces an abstract algebra to a linear algebra, which is often more practical to work with. For example, the Pauli matrices provide a convenient representation of the Lie group
denotes the representation. The idea behind a representation is to make an abstract algebra more concrete by representing the elements thereof as matrices; i.e., a representation reduces an abstract algebra to a linear algebra, which is often more practical to work with. For example, the Pauli matrices provide a convenient representation of the Lie group  . In the present context, the representation determines the Hilbert space, i.e., the particle–and, arguably, physical–content of the theory itself. We will return to this important point momentarily, but first we must introduce a bit more machinery.
. In the present context, the representation determines the Hilbert space, i.e., the particle–and, arguably, physical–content of the theory itself. We will return to this important point momentarily, but first we must introduce a bit more machinery. be the set of bounded operators (specifically, linear combinations of Weyl operators) acting on
be the set of bounded operators (specifically, linear combinations of Weyl operators) acting on 
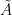 to
to  (not to be confused with non-scripty
(not to be confused with non-scripty 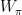 !) denote the set of all bounded operators on
!) denote the set of all bounded operators on 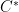 -algebra generated by the Weyl operators
-algebra generated by the Weyl operators 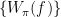 . It is important to note that this is only a subalgebra of the algebra of all bounded operators on
. It is important to note that this is only a subalgebra of the algebra of all bounded operators on  , which is uniformly closed under adjoints
, which is uniformly closed under adjoints  .
. , which act on
, which act on 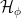 , respectively, and denote the associated
, respectively, and denote the associated  . A bijective mapping
. A bijective mapping 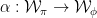 is called a
is called a  -isomorphism iff
-isomorphism iff 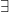 a
a 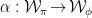 such that
such that  .
. . (Implicitly, we mean the Weyl algebra over
. (Implicitly, we mean the Weyl algebra over  , denoted
, denoted ![{\mathcal{W}[S,\sigma]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BW%7D%5BS%2C%5Csigma%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , but we may suppress the arguments henceforth without confusion). Thus the problem of defining the Hilbert space amounts to choosing a representation
, but we may suppress the arguments henceforth without confusion). Thus the problem of defining the Hilbert space amounts to choosing a representation  of the Weyl algebra, i.e., the map
of the Weyl algebra, i.e., the map  . We will frequently denote this representation by
. We will frequently denote this representation by 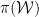 .
.
 , the von Neumann algebra generated by
, the von Neumann algebra generated by 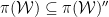 , since the latter is the weak closure of the former.
, since the latter is the weak closure of the former. of
of  such that
such that  . A representation
. A representation  is factorial iff the associated von Neumann algebra is a factor, meaning it has trivial center—that is, the only operators in
is factorial iff the associated von Neumann algebra is a factor, meaning it has trivial center—that is, the only operators in 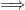 quasi-equivalent
quasi-equivalent  that maps
that maps 
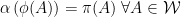 (cf. Theorem 2). Unitary equivalence is then simply the special case in which
(cf. Theorem 2). Unitary equivalence is then simply the special case in which 
 ; i.e.,
; i.e., 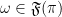 iff there exists a density operator
iff there exists a density operator  acting on
acting on 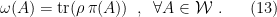
 , and disjoint iff
, and disjoint iff  . That is, two representations are disjoint iff they have no normal states in common (in which case, all normal states in one are orthogonal to those in the other).
. That is, two representations are disjoint iff they have no normal states in common (in which case, all normal states in one are orthogonal to those in the other). approximated by states in
approximated by states in 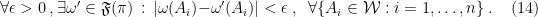
 (note that this implies the converse), then
(note that this implies the converse), then  is weakly continuous, which by Stone’s theorem (not to be confused with the above) guarantees the existence of unbounded self-adjoint operators
is weakly continuous, which by Stone’s theorem (not to be confused with the above) guarantees the existence of unbounded self-adjoint operators  on
on 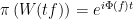 , which are in turn affiliated with
, which are in turn affiliated with 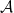 can be weak
can be weak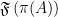 .
.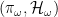 and a vector
and a vector  such that
such that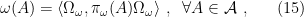
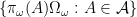 is dense in
is dense in  . Furthermore,
. Furthermore,  is irreducible iff
is irreducible iff  is referred to as the GNS representation of
is referred to as the GNS representation of  is a cyclic vector for this representation. (Note that
is a cyclic vector for this representation. (Note that  , there always exists
, there always exists 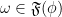 ; i.e., every state is normal in some representation.
; i.e., every state is normal in some representation.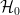 the vacuum sector of Hilbert space, which consists of all states that can be created from the vacuum
the vacuum sector of Hilbert space, which consists of all states that can be created from the vacuum  by local field operators. Note that
by local field operators. Note that 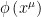 is smeared against some smooth function
is smeared against some smooth function  with finite spacetime support to create the smeared operator
with finite spacetime support to create the smeared operator 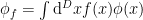 , where
, where  is the spacetime dimension and
is the spacetime dimension and  . The smearing ensures that the states have finite norm and are thus well-defined members of Hilbert space. Hence states of the form
. The smearing ensures that the states have finite norm and are thus well-defined members of Hilbert space. Hence states of the form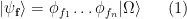
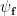 . This defines the vacuum sector of the theory.
. This defines the vacuum sector of the theory. . Quantum mechanically, this is the “time-slice axiom” of QFT [1], and encodes the physical expectation that there exists a dynamical law that enables one to compute fields at arbitrary time given the set of fields at some time slice (e.g., if
. Quantum mechanically, this is the “time-slice axiom” of QFT [1], and encodes the physical expectation that there exists a dynamical law that enables one to compute fields at arbitrary time given the set of fields at some time slice (e.g., if  , one could take the functions
, one could take the functions 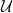 of
of 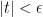 for some small positive
for some small positive  ). (As a side-comment for holography, note that there are no Cauchy slices in AdS, since data can always sneak in from infinity! This follows from the fact that the boundary is timelike rather than null or spacelike. Hence while any spacelike slice does cover the whole space, there nevertheless exist null geodesics from timelike infinite that do not intersect any point thereupon. However, the Cauchy problem can still be made well-posed within the Einstein static universe, which only covers half the spacetime).
). (As a side-comment for holography, note that there are no Cauchy slices in AdS, since data can always sneak in from infinity! This follows from the fact that the boundary is timelike rather than null or spacelike. Hence while any spacelike slice does cover the whole space, there nevertheless exist null geodesics from timelike infinite that do not intersect any point thereupon. However, the Cauchy problem can still be made well-posed within the Einstein static universe, which only covers half the spacetime). in
in 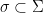 , and the support of the functions
, and the support of the functions  of
of  in spacetime, the states
in spacetime, the states 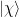 orthogonal to all
orthogonal to all 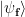 with all
with all 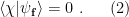
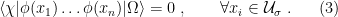
 , and hence it must be rigorously interpreted as a distribution as in (2). We will not bother to restate Witten’s elegant proof here; it can be found in section 2.2 of [2]. The basic idea is to show that if (3) holds for all
, and hence it must be rigorously interpreted as a distribution as in (2). We will not bother to restate Witten’s elegant proof here; it can be found in section 2.2 of [2]. The basic idea is to show that if (3) holds for all 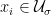 , then it actually holds for all
, then it actually holds for all  . But this implies that
. But this implies that  must vanish, by the definition of the vacuum sector (i.e., the states
must vanish, by the definition of the vacuum sector (i.e., the states  , and is bounded from below by 0 (for holomorphicity arguments). (In fact this first assumption can be weakened: one needs only an energy-momentum operator
, and is bounded from below by 0 (for holomorphicity arguments). (In fact this first assumption can be weakened: one needs only an energy-momentum operator 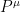 such that
such that  is a bounded operator on Hilbert space, where
is a bounded operator on Hilbert space, where  is a general
is a general 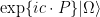 varies holomorphically with the components
varies holomorphically with the components  ). One then uses the fact that any point in
). One then uses the fact that any point in 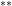 spacetimes
spacetimes  is two-fold: in curved spacetimes, there is no natural analog of the vacuum state, and no natural translation generators
is two-fold: in curved spacetimes, there is no natural analog of the vacuum state, and no natural translation generators  Note the restriction to globally hyperbolic spacetimes is intended to ensure we can still define a Cauchy surface. As mentioned above, this doesn’t technically hold in AdS, but the spirit of this requirement — namely, ensuring causality, and avoiding pathologies like closed timelike curves and naked singularities — survives intact, so we’ll follow the masses and consider AdS to be an honorary member of this family.
Note the restriction to globally hyperbolic spacetimes is intended to ensure we can still define a Cauchy surface. As mentioned above, this doesn’t technically hold in AdS, but the spirit of this requirement — namely, ensuring causality, and avoiding pathologies like closed timelike curves and naked singularities — survives intact, so we’ll follow the masses and consider AdS to be an honorary member of this family.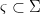 to be the region of spacetime, spacelike separated from
to be the region of spacetime, spacelike separated from 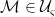 to have expectation value 0 in states which do not contain the Moon in region
to have expectation value 0 in states which do not contain the Moon in region  , and 1 in states that do. Hence
, and 1 in states that do. Hence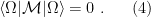
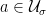 such that
such that  approximates the state in which
approximates the state in which  contains the Moon arbitrarily well,
contains the Moon arbitrarily well,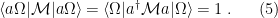
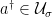 , and
, and 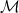 is supported in the spacelike separated region
is supported in the spacelike separated region 
 were unitary, then the fact that
were unitary, then the fact that 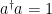 would imply a contradiction between (4) and (6). But RS does not guarantee the existence of a unitary operator in
would imply a contradiction between (4) and (6). But RS does not guarantee the existence of a unitary operator in  . Note that this example highlights an important relationship between causality and unitarity; we shall comment on this again below.
. Note that this example highlights an important relationship between causality and unitarity; we shall comment on this again below.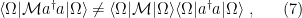
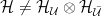 .
.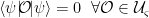 . But this contradicts the theorem, since we can create any state in
. But this contradicts the theorem, since we can create any state in 
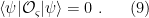
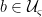 such that the state
such that the state 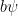 approximates the state with non-vanishing expectation value arbitrarily well, that is:
approximates the state with non-vanishing expectation value arbitrarily well, that is: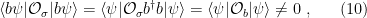
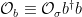 does not belong to
does not belong to  , then
, then ![{F[\phi]=F[\phi']}](https://s0.wp.com/latex.php?latex=%7BF%5B%5Cphi%5D%3DF%5B%5Cphi%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) means that
means that 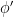 ).
). to
to 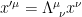 , we define
, we define 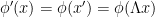 . In other words, we think of
. In other words, we think of  , respectively equipped with coordinate charts
, respectively equipped with coordinate charts  . Let
. Let  , and
, and  . Now consider a diffeomorphism
. Now consider a diffeomorphism  . Then the original field
. Then the original field 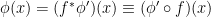 . In general of course,
. In general of course, 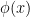 and
and  may map to different points in
may map to different points in 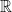 . But if we demand
. But if we demand 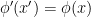 , one can see from this picture that this imposes that the new field configuration (on the new manifold) nonetheless maps to the same point in
, one can see from this picture that this imposes that the new field configuration (on the new manifold) nonetheless maps to the same point in  is an active (Lorentz) transformation. The former amounts to a mere coordinate redefinition, while the latter specifies an entirely new field configuration; this answer [1] on Stack Exchange contains a helpful illustration of the difference (see also [2]).
is an active (Lorentz) transformation. The former amounts to a mere coordinate redefinition, while the latter specifies an entirely new field configuration; this answer [1] on Stack Exchange contains a helpful illustration of the difference (see also [2]).
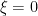 ). Obviously, a coordinate change will preserve solutions to this equation: they’ll simply be mapped from one coordinate system to another. It is therefore generally covariant. But it is not diffeomorphism invariant, since a diffeomorphism changes the metric
). Obviously, a coordinate change will preserve solutions to this equation: they’ll simply be mapped from one coordinate system to another. It is therefore generally covariant. But it is not diffeomorphism invariant, since a diffeomorphism changes the metric 
![\displaystyle S_{M}[A]=-\frac{1}{4}\int\mathrm{d}^4x\sqrt{-g}F_{\mu\nu}F^{\mu\nu}~, \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S_%7BM%7D%5BA%5D%3D-%5Cfrac%7B1%7D%7B4%7D%5Cint%5Cmathrm%7Bd%7D%5E4x%5Csqrt%7B-g%7DF_%7B%5Cmu%5Cnu%7DF%5E%7B%5Cmu%5Cnu%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle S_{EH}[g]=\frac{1}{16\pi G}\int\mathrm{d}^4x\sqrt{-g}R^{\mu\nu}g_{\mu\nu}~. \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S_%7BEH%7D%5Bg%5D%3D%5Cfrac%7B1%7D%7B16%5Cpi+G%7D%5Cint%5Cmathrm%7Bd%7D%5E4x%5Csqrt%7B-g%7DR%5E%7B%5Cmu%5Cnu%7Dg_%7B%5Cmu%5Cnu%7D%7E.+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
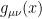 , and are manifestly covariant (i.e., all metric indices are contracted). But in the former, the metric appears as a fixed background, and only the electromagnetic potential
, and are manifestly covariant (i.e., all metric indices are contracted). But in the former, the metric appears as a fixed background, and only the electromagnetic potential 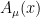 appears as an argument of the functional
appears as an argument of the functional ![{S_M[A]}](https://s0.wp.com/latex.php?latex=%7BS_M%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . In contrast, in the Einstein-Hilbert action
. In contrast, in the Einstein-Hilbert action ![{S_{EH}[g]}](https://s0.wp.com/latex.php?latex=%7BS_%7BEH%7D%5Bg%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , the metric is a dynamical variable, and thus the background is a solution to the equations rather than something given externally at the outset. Thus diffeomorphism invariance simply means that the manifold on which the theory is formulated is irrelevant (modulo isomorphisms) to the underlying physics (or, to take the passive view, that we can choose any coordinate patch we like), while background independence is the stronger statement that the manifold itself is not fixed a priori. And this is what makes general relativity special.
, the metric is a dynamical variable, and thus the background is a solution to the equations rather than something given externally at the outset. Thus diffeomorphism invariance simply means that the manifold on which the theory is formulated is irrelevant (modulo isomorphisms) to the underlying physics (or, to take the passive view, that we can choose any coordinate patch we like), while background independence is the stronger statement that the manifold itself is not fixed a priori. And this is what makes general relativity special. will certainly map geodesics
will certainly map geodesics  for the new metric
for the new metric 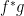 . What the author means is that, except in the special case where the diffeomorphism is an isometry (i.e.,
. What the author means is that, except in the special case where the diffeomorphism is an isometry (i.e.,  ; note isometry
; note isometry 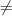 isomorphism!),
isomorphism!),  . The quantum coherence between these pointer states is encoded in the off-diagonal elements of the reduced density matrix of the subsystem, and thus, loosely speaking, the disappearance of these off-diagonal elements characterizes the decoherence process.
. The quantum coherence between these pointer states is encoded in the off-diagonal elements of the reduced density matrix of the subsystem, and thus, loosely speaking, the disappearance of these off-diagonal elements characterizes the decoherence process.
 ,
, 

 from a quantum to classical state. This is the process we wish to study.
from a quantum to classical state. This is the process we wish to study.![\displaystyle \mathcal{L}[\phi,\chi]=\mathcal{L}_\mathrm{sys}[\phi]+\mathcal{L}_\mathrm{env}[\chi]+\mathcal{L}_\mathrm{int}[\phi,\chi]~, \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D%5B%5Cphi%2C%5Cchi%5D%3D%5Cmathcal%7BL%7D_%5Cmathrm%7Bsys%7D%5B%5Cphi%5D%2B%5Cmathcal%7BL%7D_%5Cmathrm%7Benv%7D%5B%5Cchi%5D%2B%5Cmathcal%7BL%7D_%5Cmathrm%7Bint%7D%5B%5Cphi%2C%5Cchi%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
 . The authors of [1] consider a strictly linear coupling of the form
. The authors of [1] consider a strictly linear coupling of the form ![\displaystyle \mathcal{L}_\mathrm{int}[\phi,\chi]=g\phi f[\chi]~, \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D_%5Cmathrm%7Bint%7D%5B%5Cphi%2C%5Cchi%5D%3Dg%5Cphi+f%5B%5Cchi%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{f[\chi]}](https://s0.wp.com/latex.php?latex=%7Bf%5B%5Cchi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is an arbitrary functional of the fields
is an arbitrary functional of the fields  Euclidean,
Euclidean, ![{[\phi]=(d\!-\!1)/2}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cphi%5D%3D%28d%5C%21-%5C%211%29%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002) , so
, so ![{[g]}](https://s0.wp.com/latex.php?latex=%7B%5Bg%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) will depend on the precise form of
will depend on the precise form of ![\displaystyle \mathcal{L}_\mathrm{sys}[\phi]=-\frac{1}{2}\left(\partial_\mu\phi\right)^2-\frac{1}{2}\Omega^2\phi^2~. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D_%5Cmathrm%7Bsys%7D%5B%5Cphi%5D%3D-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cpartial_%5Cmu%5Cphi%5Cright%29%5E2-%5Cfrac%7B1%7D%7B2%7D%5COmega%5E2%5Cphi%5E2%7E.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
 then require that this integral is computed along a closed path, namely the Keldysh contour (basically, this amounts to a Lorentzian timefold in an otherwise Euclidean contour, thereby allowing one to insert unitary operators). For concreteness and convenience, [1] considers the thermostatic case
then require that this integral is computed along a closed path, namely the Keldysh contour (basically, this amounts to a Lorentzian timefold in an otherwise Euclidean contour, thereby allowing one to insert unitary operators). For concreteness and convenience, [1] considers the thermostatic case  , so that Euclidean time runs from
, so that Euclidean time runs from 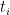 to
to  . Hence the contour first moves along the Lorentzian timefold from
. Hence the contour first moves along the Lorentzian timefold from  and back, and then continues in Euclidean to
and back, and then continues in Euclidean to 
 . By inserting two resolutions of the identity, and using the evolution equation (2) with (3), this becomes
. By inserting two resolutions of the identity, and using the evolution equation (2) with (3), this becomes 
![\displaystyle \begin{aligned} \langle\bar\phi_+\bar\chi|e^{-iH(t_f-t_i)}|\tilde\phi_+\tilde\chi_+\rangle &=\int_{\tilde\phi_+,\tilde\chi_+}^{\bar\phi_+,\bar\chi_+}\mathcal{D}\phi_+\mathcal{D}\chi_+\,e^{i\int_{t_i}^{t_f}\mathrm{d} t\mathcal{L}[\phi_+,\chi_+]}\,,\\ \langle\tilde\phi_-\tilde\chi_-|e^{iH(t_f-t_i)}|\bar\phi_-\bar\chi\rangle &=\int_{\tilde\phi_-,\tilde\chi_-}^{\bar\phi_-,\bar\chi_-}\mathcal{D}\phi_-\mathcal{D}\chi_-\,e^{-i\int_{t_i}^{t_f}\mathrm{d} t\mathcal{L}[\phi_-,\chi_-]}~. \end{aligned} \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clangle%5Cbar%5Cphi_%2B%5Cbar%5Cchi%7Ce%5E%7B-iH%28t_f-t_i%29%7D%7C%5Ctilde%5Cphi_%2B%5Ctilde%5Cchi_%2B%5Crangle+%26%3D%5Cint_%7B%5Ctilde%5Cphi_%2B%2C%5Ctilde%5Cchi_%2B%7D%5E%7B%5Cbar%5Cphi_%2B%2C%5Cbar%5Cchi_%2B%7D%5Cmathcal%7BD%7D%5Cphi_%2B%5Cmathcal%7BD%7D%5Cchi_%2B%5C%2Ce%5E%7Bi%5Cint_%7Bt_i%7D%5E%7Bt_f%7D%5Cmathrm%7Bd%7D+t%5Cmathcal%7BL%7D%5B%5Cphi_%2B%2C%5Cchi_%2B%5D%7D%5C%2C%2C%5C%5C+%5Clangle%5Ctilde%5Cphi_-%5Ctilde%5Cchi_-%7Ce%5E%7BiH%28t_f-t_i%29%7D%7C%5Cbar%5Cphi_-%5Cbar%5Cchi%5Crangle+%26%3D%5Cint_%7B%5Ctilde%5Cphi_-%2C%5Ctilde%5Cchi_-%7D%5E%7B%5Cbar%5Cphi_-%2C%5Cbar%5Cchi_-%7D%5Cmathcal%7BD%7D%5Cphi_-%5Cmathcal%7BD%7D%5Cchi_-%5C%2Ce%5E%7B-i%5Cint_%7Bt_i%7D%5E%7Bt_f%7D%5Cmathrm%7Bd%7D+t%5Cmathcal%7BL%7D%5B%5Cphi_-%2C%5Cchi_-%5D%7D%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=0&c=20201002)
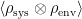 factorizes, we have
factorizes, we have ![\displaystyle \begin{aligned} \langle\bar\phi_+|&\rho_\mathrm{sys}(t_f)|\bar\phi_-\rangle =\int\mathrm{d}\bar\chi\mathrm{d}\tilde\chi_+\mathrm{d}\tilde\chi_-\mathrm{d}\tilde\phi_+\mathrm{d}\tilde\phi_- \int_{\tilde\phi_+,\tilde\chi_+}^{\bar\phi_+,\bar\chi_+}\mathcal{D}\phi_+\mathcal{D}\chi_+ \int_{\tilde\phi_-,\tilde\chi_-}^{\bar\phi_-,\bar\chi_-}\mathcal{D}\phi_-\mathcal{D}\chi_-\\ &\times e^{i\int_{t_i}^{t_f}\mathrm{d} t\left(\mathcal{L}[\phi_+,\chi_+]-\mathcal{L}[\phi_-,\chi_-]\right)} \langle\tilde\chi_+|\rho_\mathrm{env}(t_i)|\tilde\chi_-\rangle\langle\tilde\phi_+|\rho_\mathrm{sys}(t_i)|\tilde\phi_-\rangle~. \end{aligned} \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clangle%5Cbar%5Cphi_%2B%7C%26%5Crho_%5Cmathrm%7Bsys%7D%28t_f%29%7C%5Cbar%5Cphi_-%5Crangle+%3D%5Cint%5Cmathrm%7Bd%7D%5Cbar%5Cchi%5Cmathrm%7Bd%7D%5Ctilde%5Cchi_%2B%5Cmathrm%7Bd%7D%5Ctilde%5Cchi_-%5Cmathrm%7Bd%7D%5Ctilde%5Cphi_%2B%5Cmathrm%7Bd%7D%5Ctilde%5Cphi_-+%5Cint_%7B%5Ctilde%5Cphi_%2B%2C%5Ctilde%5Cchi_%2B%7D%5E%7B%5Cbar%5Cphi_%2B%2C%5Cbar%5Cchi_%2B%7D%5Cmathcal%7BD%7D%5Cphi_%2B%5Cmathcal%7BD%7D%5Cchi_%2B+%5Cint_%7B%5Ctilde%5Cphi_-%2C%5Ctilde%5Cchi_-%7D%5E%7B%5Cbar%5Cphi_-%2C%5Cbar%5Cchi_-%7D%5Cmathcal%7BD%7D%5Cphi_-%5Cmathcal%7BD%7D%5Cchi_-%5C%5C+%26%5Ctimes+e%5E%7Bi%5Cint_%7Bt_i%7D%5E%7Bt_f%7D%5Cmathrm%7Bd%7D+t%5Cleft%28%5Cmathcal%7BL%7D%5B%5Cphi_%2B%2C%5Cchi_%2B%5D-%5Cmathcal%7BL%7D%5B%5Cphi_-%2C%5Cchi_-%5D%5Cright%29%7D+%5Clangle%5Ctilde%5Cchi_%2B%7C%5Crho_%5Cmathrm%7Benv%7D%28t_i%29%7C%5Ctilde%5Cchi_-%5Crangle%5Clangle%5Ctilde%5Cphi_%2B%7C%5Crho_%5Cmathrm%7Bsys%7D%28t_i%29%7C%5Ctilde%5Cphi_-%5Crangle%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \mathcal{F}[\phi_+,\phi_-]\equiv &\int\mathrm{d}\bar\chi\mathrm{d}\tilde\chi_+\mathrm{d}\tilde\chi_-\int_{\tilde\chi_+,\tilde\chi_-}^{\bar\chi_+,\bar\chi_-}\mathcal{D}\chi_-\mathcal{D}\chi_-\\ &\times e^{i\int_{t_i}^{t_f}\mathrm{d} t\left(\mathcal{L}_\mathrm{env}[\chi_+]-\mathcal{L}_\mathrm{env}[\chi_-]+\mathcal{L}_\mathrm{int}[\phi_+,\chi_+]-\mathcal{L}_\mathrm{int}[\phi_-,\chi_-]\right)} \langle\tilde\chi_+|\rho_\mathrm{env}(t_i)|\tilde\chi_-\rangle~, \end{aligned} \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathcal%7BF%7D%5B%5Cphi_%2B%2C%5Cphi_-%5D%5Cequiv+%26%5Cint%5Cmathrm%7Bd%7D%5Cbar%5Cchi%5Cmathrm%7Bd%7D%5Ctilde%5Cchi_%2B%5Cmathrm%7Bd%7D%5Ctilde%5Cchi_-%5Cint_%7B%5Ctilde%5Cchi_%2B%2C%5Ctilde%5Cchi_-%7D%5E%7B%5Cbar%5Cchi_%2B%2C%5Cbar%5Cchi_-%7D%5Cmathcal%7BD%7D%5Cchi_-%5Cmathcal%7BD%7D%5Cchi_-%5C%5C+%26%5Ctimes+e%5E%7Bi%5Cint_%7Bt_i%7D%5E%7Bt_f%7D%5Cmathrm%7Bd%7D+t%5Cleft%28%5Cmathcal%7BL%7D_%5Cmathrm%7Benv%7D%5B%5Cchi_%2B%5D-%5Cmathcal%7BL%7D_%5Cmathrm%7Benv%7D%5B%5Cchi_-%5D%2B%5Cmathcal%7BL%7D_%5Cmathrm%7Bint%7D%5B%5Cphi_%2B%2C%5Cchi_%2B%5D-%5Cmathcal%7BL%7D_%5Cmathrm%7Bint%7D%5B%5Cphi_-%2C%5Cchi_-%5D%5Cright%29%7D+%5Clangle%5Ctilde%5Cchi_%2B%7C%5Crho_%5Cmathrm%7Benv%7D%28t_i%29%7C%5Ctilde%5Cchi_-%5Crangle%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle J[\bar\phi_+,\bar\phi_-;t_f|\tilde \phi_+,\tilde\phi_-;t_i]\equiv\int_{\tilde\phi_+,\tilde\phi_-}^{\bar\phi_+,\bar\phi_-}\mathcal{D}\phi_+\mathcal{D}\phi_- \,e^{i\int_{t_i}^{t_f}\mathrm{d} t\left(\mathcal{L}_\mathrm{sys}[\phi_+]-\mathcal{L}_\mathrm{sys}[\phi_-]\right)}\mathcal{F}[\phi_+,\phi_-]~, \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%5B%5Cbar%5Cphi_%2B%2C%5Cbar%5Cphi_-%3Bt_f%7C%5Ctilde+%5Cphi_%2B%2C%5Ctilde%5Cphi_-%3Bt_i%5D%5Cequiv%5Cint_%7B%5Ctilde%5Cphi_%2B%2C%5Ctilde%5Cphi_-%7D%5E%7B%5Cbar%5Cphi_%2B%2C%5Cbar%5Cphi_-%7D%5Cmathcal%7BD%7D%5Cphi_%2B%5Cmathcal%7BD%7D%5Cphi_-+%5C%2Ce%5E%7Bi%5Cint_%7Bt_i%7D%5E%7Bt_f%7D%5Cmathrm%7Bd%7D+t%5Cleft%28%5Cmathcal%7BL%7D_%5Cmathrm%7Bsys%7D%5B%5Cphi_%2B%5D-%5Cmathcal%7BL%7D_%5Cmathrm%7Bsys%7D%5B%5Cphi_-%5D%5Cright%29%7D%5Cmathcal%7BF%7D%5B%5Cphi_%2B%2C%5Cphi_-%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \langle\bar\phi_+|\rho_\mathrm{sys}(t_f)|\bar\phi_-\rangle= \int\mathrm{d}\tilde\phi_+\mathrm{d}\tilde\phi_- J[\bar\phi_+,\bar\phi_-;t_f|\tilde \phi_+,\tilde\phi_-;t_i] \langle\tilde\phi_+|\rho_\mathrm{sys}(t_i)|\tilde\phi_-\rangle~. \ \ \ \ \ (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle%5Cbar%5Cphi_%2B%7C%5Crho_%5Cmathrm%7Bsys%7D%28t_f%29%7C%5Cbar%5Cphi_-%5Crangle%3D+%5Cint%5Cmathrm%7Bd%7D%5Ctilde%5Cphi_%2B%5Cmathrm%7Bd%7D%5Ctilde%5Cphi_-+J%5B%5Cbar%5Cphi_%2B%2C%5Cbar%5Cphi_-%3Bt_f%7C%5Ctilde+%5Cphi_%2B%2C%5Ctilde%5Cphi_-%3Bt_i%5D+%5Clangle%5Ctilde%5Cphi_%2B%7C%5Crho_%5Cmathrm%7Bsys%7D%28t_i%29%7C%5Ctilde%5Cphi_-%5Crangle%7E.+%5C+%5C+%5C+%5C+%5C+%2813%29&bg=ffffff&fg=000000&s=0&c=20201002)
 :
: ![\displaystyle \mathcal{F}[\phi_+,\phi_-]=\langle\mathcal{T}_\mathcal{K}e^{i\int_\mathcal{K}\mathcal{L}_\mathrm{int}[\phi,\chi]}\rangle_\mathrm{env} =\langle\mathcal{T}_\mathcal{K}e^{ig\int_\mathcal{K}\phi f[\chi]}\rangle_\mathrm{env}~, \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BF%7D%5B%5Cphi_%2B%2C%5Cphi_-%5D%3D%5Clangle%5Cmathcal%7BT%7D_%5Cmathcal%7BK%7De%5E%7Bi%5Cint_%5Cmathcal%7BK%7D%5Cmathcal%7BL%7D_%5Cmathrm%7Bint%7D%5B%5Cphi%2C%5Cchi%5D%7D%5Crangle_%5Cmathrm%7Benv%7D+%3D%5Clangle%5Cmathcal%7BT%7D_%5Cmathcal%7BK%7De%5E%7Big%5Cint_%5Cmathcal%7BK%7D%5Cphi+f%5B%5Cchi%5D%7D%5Crangle_%5Cmathrm%7Benv%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
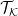 is the path-ordering symbol with respect to the Keldysh contour, and
is the path-ordering symbol with respect to the Keldysh contour, and ![\displaystyle \langle\ldots\rangle_\mathrm{env}\equiv\mathrm{tr}_\mathrm{env}\left[\rho_\mathrm{env}(t_i)\ldots\right]~. \ \ \ \ \ (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle%5Cldots%5Crangle_%5Cmathrm%7Benv%7D%5Cequiv%5Cmathrm%7Btr%7D_%5Cmathrm%7Benv%7D%5Cleft%5B%5Crho_%5Cmathrm%7Benv%7D%28t_i%29%5Cldots%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0&c=20201002)

 . In this case however, we have to take into account the Keldysh contour that runs forward to
. In this case however, we have to take into account the Keldysh contour that runs forward to  and
and  , respectively, what we really want is something like
, respectively, what we really want is something like  . The trace then instructs us to integrate over all possible paths that interpolate between the two, subject to the boundary condition that
. The trace then instructs us to integrate over all possible paths that interpolate between the two, subject to the boundary condition that  at
at 
![\displaystyle G_{ss'}(x_1,x_2)\equiv-i\langle\mathcal{T}_\mathcal{K}\mathcal{O}_s(x_1)\mathcal{O}_{s'}(x_2)\rangle_\mathrm{env} =-i\frac{\delta^2\ln\mathcal{F}[\phi_+,\phi_-]}{\delta\phi_s(x_1)\phi_{s'}(x_2)}\bigg|_{\phi=0}~, \ \ \ \ \ (18)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G_%7Bss%27%7D%28x_1%2Cx_2%29%5Cequiv-i%5Clangle%5Cmathcal%7BT%7D_%5Cmathcal%7BK%7D%5Cmathcal%7BO%7D_s%28x_1%29%5Cmathcal%7BO%7D_%7Bs%27%7D%28x_2%29%5Crangle_%5Cmathrm%7Benv%7D+%3D-i%5Cfrac%7B%5Cdelta%5E2%5Cln%5Cmathcal%7BF%7D%5B%5Cphi_%2B%2C%5Cphi_-%5D%7D%7B%5Cdelta%5Cphi_s%28x_1%29%5Cphi_%7Bs%27%7D%28x_2%29%7D%5Cbigg%7C_%7B%5Cphi%3D0%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2818%29&bg=ffffff&fg=000000&s=0&c=20201002)
 .
.![{Z[J]}](https://s0.wp.com/latex.php?latex=%7BZ%5BJ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (where we’re temporarily reverting to standard QFT notation in which
(where we’re temporarily reverting to standard QFT notation in which  denotes the source), which generates both connected and disconnected Feynman diagrams via
denotes the source), which generates both connected and disconnected Feynman diagrams via![\displaystyle \langle\mathcal{O}(x_1)\ldots\mathcal{O}(x_n)\rangle=\frac{1}{i^n}\frac{\delta^nZ[J]}{\delta J(x_1)\ldots\delta J(x_n)}\bigg|_{J=0}~, \ \ \ \ \ (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle%5Cmathcal%7BO%7D%28x_1%29%5Cldots%5Cmathcal%7BO%7D%28x_n%29%5Crangle%3D%5Cfrac%7B1%7D%7Bi%5En%7D%5Cfrac%7B%5Cdelta%5EnZ%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cldots%5Cdelta+J%28x_n%29%7D%5Cbigg%7C_%7BJ%3D0%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2819%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{W[J]}](https://s0.wp.com/latex.php?latex=%7BW%5BJ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for the connected
for the connected ![\displaystyle Z[J]=e^{-W[J]}\;\;\implies\;\;W[J]=-\ln Z[J]~. \ \ \ \ \ (20)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5BJ%5D%3De%5E%7B-W%5BJ%5D%7D%5C%3B%5C%3B%5Cimplies%5C%3B%5C%3BW%5BJ%5D%3D-%5Cln+Z%5BJ%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=0&c=20201002)
 rather than
rather than ![\displaystyle \langle\mathcal{O}(x_1)\ldots\mathcal{O}(x_n)\rangle_c=\frac{1}{i^n}\frac{\delta^nW[J]}{\delta J(x_1)\ldots\delta J(x_n)}\bigg|_{J=0}~. \ \ \ \ \ (21)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle%5Cmathcal%7BO%7D%28x_1%29%5Cldots%5Cmathcal%7BO%7D%28x_n%29%5Crangle_c%3D%5Cfrac%7B1%7D%7Bi%5En%7D%5Cfrac%7B%5Cdelta%5EnW%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cldots%5Cdelta+J%28x_n%29%7D%5Cbigg%7C_%7BJ%3D0%7D%7E.+%5C+%5C+%5C+%5C+%5C+%2821%29&bg=ffffff&fg=000000&s=0&c=20201002)
 and multiply by
and multiply by 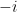 to fix conventions:
to fix conventions:![\displaystyle G(x_1,x_2)=-i\langle\mathcal{O}(x_1)\mathcal{O}(x_2)\rangle_c=-i\frac{1}{i^2}\frac{\delta^2W[J]}{\delta J(x_1)\delta J(x_2)}\bigg|_{J=0} =-i\frac{\delta^2\ln Z[J]}{\delta J(x_1)\delta J(x_2)}\bigg|_{J=0}~, \ \ \ \ \ (22)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G%28x_1%2Cx_2%29%3D-i%5Clangle%5Cmathcal%7BO%7D%28x_1%29%5Cmathcal%7BO%7D%28x_2%29%5Crangle_c%3D-i%5Cfrac%7B1%7D%7Bi%5E2%7D%5Cfrac%7B%5Cdelta%5E2W%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cdelta+J%28x_2%29%7D%5Cbigg%7C_%7BJ%3D0%7D+%3D-i%5Cfrac%7B%5Cdelta%5E2%5Cln+Z%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cdelta+J%28x_2%29%7D%5Cbigg%7C_%7BJ%3D0%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2822%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathcal{F}[\phi]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BF%7D%5B%5Cphi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . I believe this is what the authors mean when they say that the influence functional may be regarded as an effective action for the system (having integrated out the environment degrees of freedom), though strictly speaking this is misleading: first, because obviously partition functions are not actions, and second, because the effective action is given by
. I believe this is what the authors mean when they say that the influence functional may be regarded as an effective action for the system (having integrated out the environment degrees of freedom), though strictly speaking this is misleading: first, because obviously partition functions are not actions, and second, because the effective action is given by  rather than
rather than  ), this is feasible if we approximate the influence functional to quadratic order. This is more clearly explained in [2] (beware however that this reference uses the term “influence functional” to mean
), this is feasible if we approximate the influence functional to quadratic order. This is more clearly explained in [2] (beware however that this reference uses the term “influence functional” to mean 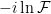 ; they also appear to use a different sign convention. I suspect reference [1] is atypical in both regards, and that the notation in [2] is actually more standard). The basic idea is that for small coupling, we may evaluate the path integral perturbatively, and exponentiate the result to obtain the effective action. We first expand (14) (suppressing the time-ordering symbol for compactness):
; they also appear to use a different sign convention. I suspect reference [1] is atypical in both regards, and that the notation in [2] is actually more standard). The basic idea is that for small coupling, we may evaluate the path integral perturbatively, and exponentiate the result to obtain the effective action. We first expand (14) (suppressing the time-ordering symbol for compactness):![\displaystyle \begin{aligned} \langle e^{ig\int_\mathcal{K}\phi f[\chi]}\rangle_\mathrm{env} &=\,1\,+\,ig\int_\mathcal{K}\!\mathrm{d}^4 x\,\phi(x)\langle f[\chi(x)]\rangle_\mathrm{env}\\ &+\,\frac{(ig)^2}{2}\int_\mathcal{K}\!\mathrm{d}^4x_1\!\mathrm{d}^4 x_2\,\phi(x_1)\phi(x_2)\langle f[\chi(x_1)]f[\chi(x_2)]\rangle_\mathrm{env} \,+\,\ldots~. \end{aligned} \ \ \ \ \ (23)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clangle+e%5E%7Big%5Cint_%5Cmathcal%7BK%7D%5Cphi+f%5B%5Cchi%5D%7D%5Crangle_%5Cmathrm%7Benv%7D+%26%3D%5C%2C1%5C%2C%2B%5C%2Cig%5Cint_%5Cmathcal%7BK%7D%5C%21%5Cmathrm%7Bd%7D%5E4+x%5C%2C%5Cphi%28x%29%5Clangle+f%5B%5Cchi%28x%29%5D%5Crangle_%5Cmathrm%7Benv%7D%5C%5C+%26%2B%5C%2C%5Cfrac%7B%28ig%29%5E2%7D%7B2%7D%5Cint_%5Cmathcal%7BK%7D%5C%21%5Cmathrm%7Bd%7D%5E4x_1%5C%21%5Cmathrm%7Bd%7D%5E4+x_2%5C%2C%5Cphi%28x_1%29%5Cphi%28x_2%29%5Clangle+f%5B%5Cchi%28x_1%29%5Df%5B%5Cchi%28x_2%29%5D%5Crangle_%5Cmathrm%7Benv%7D+%5C%2C%2B%5C%2C%5Cldots%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2823%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{\langle f[\chi]\rangle=0}](https://s0.wp.com/latex.php?latex=%7B%5Clangle+f%5B%5Cchi%5D%5Crangle%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) ), the effective action contains only the quadratic contribution (up to this order), and we may therefore write
), the effective action contains only the quadratic contribution (up to this order), and we may therefore write![\displaystyle \begin{aligned} -i\ln\mathcal{F}[\phi_+,\phi_-]&\approx-\frac{g^2}{2}\int\mathrm{d}^{d+1}x\mathrm{d}^{d+1}x'\sum_{s,s'}\mathrm{sgn}(ss')\phi_s(x)G_{ss'}(x-x')\phi_{s'}(x')\\ &=-g^2\int\mathrm{d}^{d+1}x\mathrm{d}^{d+1}x'\left[\Delta(x)G_R(x-x')\Sigma(x')-\frac{i}{2}\Delta(x)G_\mathrm{sym}(x-x')\Delta(x')\right]~, \end{aligned} \ \ \ \ \ (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+-i%5Cln%5Cmathcal%7BF%7D%5B%5Cphi_%2B%2C%5Cphi_-%5D%26%5Capprox-%5Cfrac%7Bg%5E2%7D%7B2%7D%5Cint%5Cmathrm%7Bd%7D%5E%7Bd%2B1%7Dx%5Cmathrm%7Bd%7D%5E%7Bd%2B1%7Dx%27%5Csum_%7Bs%2Cs%27%7D%5Cmathrm%7Bsgn%7D%28ss%27%29%5Cphi_s%28x%29G_%7Bss%27%7D%28x-x%27%29%5Cphi_%7Bs%27%7D%28x%27%29%5C%5C+%26%3D-g%5E2%5Cint%5Cmathrm%7Bd%7D%5E%7Bd%2B1%7Dx%5Cmathrm%7Bd%7D%5E%7Bd%2B1%7Dx%27%5Cleft%5B%5CDelta%28x%29G_R%28x-x%27%29%5CSigma%28x%27%29-%5Cfrac%7Bi%7D%7B2%7D%5CDelta%28x%29G_%5Cmathrm%7Bsym%7D%28x-x%27%29%5CDelta%28x%27%29%5Cright%5D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2824%29&bg=ffffff&fg=000000&s=0&c=20201002)

 in terms of the standard advanced, retarded, and symmetric Green’s functions,
in terms of the standard advanced, retarded, and symmetric Green’s functions,![\displaystyle \begin{aligned} G_A(x_1,x_2)&=i\Theta(t_2-t_1)\langle[\mathcal{O}(x_1),\mathcal{O}(x_2)]\rangle_\mathrm{env}~,\\ G_R(x_1,x_2)&=i\Theta(t_1-t_2)\langle[\mathcal{O}(x_2),\mathcal{O}(x_1)]\rangle_\mathrm{env}~,\\ G_\mathrm{sym}(x_1,x_2)&=\frac{1}{2}\langle\{\mathcal{O}(x_1),\mathcal{O}(x_2)]\}\rangle_\mathrm{env}~, \end{aligned} \ \ \ \ \ (26)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+G_A%28x_1%2Cx_2%29%26%3Di%5CTheta%28t_2-t_1%29%5Clangle%5B%5Cmathcal%7BO%7D%28x_1%29%2C%5Cmathcal%7BO%7D%28x_2%29%5D%5Crangle_%5Cmathrm%7Benv%7D%7E%2C%5C%5C+G_R%28x_1%2Cx_2%29%26%3Di%5CTheta%28t_1-t_2%29%5Clangle%5B%5Cmathcal%7BO%7D%28x_2%29%2C%5Cmathcal%7BO%7D%28x_1%29%5D%5Crangle_%5Cmathrm%7Benv%7D%7E%2C%5C%5C+G_%5Cmathrm%7Bsym%7D%28x_1%2Cx_2%29%26%3D%5Cfrac%7B1%7D%7B2%7D%5Clangle%5C%7B%5Cmathcal%7BO%7D%28x_1%29%2C%5Cmathcal%7BO%7D%28x_2%29%5D%5C%7D%5Crangle_%5Cmathrm%7Benv%7D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2826%29&bg=ffffff&fg=000000&s=0&c=20201002)

 and
and  .
.
![\displaystyle G_\mathrm{sym}(\omega)=-[1+2n(\omega)]\mathrm{Im}G_R(\omega)~, \qquad\mathrm{where}\qquad n(w)=\frac{1}{e^{\beta\omega}-1}~. \ \ \ \ \ (29)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G_%5Cmathrm%7Bsym%7D%28%5Comega%29%3D-%5B1%2B2n%28%5Comega%29%5D%5Cmathrm%7BIm%7DG_R%28%5Comega%29%7E%2C+%5Cqquad%5Cmathrm%7Bwhere%7D%5Cqquad+n%28w%29%3D%5Cfrac%7B1%7D%7Be%5E%7B%5Cbeta%5Comega%7D-1%7D%7E.+%5C+%5C+%5C+%5C+%5C+%2829%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is simply the thermal distribution function. The utility of this relation is that it allows us to express (18) entirely in terms of
is simply the thermal distribution function. The utility of this relation is that it allows us to express (18) entirely in terms of  , and therefore knowledge of the environment’s retarded Green’s function completely determines the dynamics of
, and therefore knowledge of the environment’s retarded Green’s function completely determines the dynamics of  ,
,  can be thought of as a light field that encodes the random fluctuations around the heavy center-of-mass field
can be thought of as a light field that encodes the random fluctuations around the heavy center-of-mass field  , which is the Fourier transform of the density matrix
, which is the Fourier transform of the density matrix  with respect to the fast field
with respect to the fast field 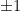 and
and  , respectively. In particular, as shown in a beautiful paper by Boulware and Deser in 1975 [1], “a quantum particle description of local (non-cosmological) gravitational phenomena necessarily leads to a classical limit which is just a metric theory of gravity. [If] only helicity
, respectively. In particular, as shown in a beautiful paper by Boulware and Deser in 1975 [1], “a quantum particle description of local (non-cosmological) gravitational phenomena necessarily leads to a classical limit which is just a metric theory of gravity. [If] only helicity  , the experimental
, the experimental 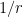 gravitational potential implies that the graviton must be massless, at least to within experimental accuracy.
gravitational potential implies that the graviton must be massless, at least to within experimental accuracy. electrons, for example, are not force carriers in this paradigm; that role belongs to the integer bosons). We can also rule out spin
electrons, for example, are not force carriers in this paradigm; that role belongs to the integer bosons). We can also rule out spin  ,
,  . Thus the dimension of the space of spin states is the same as that of a vector in three-dimensional space, and in fact can be shown to form a representation of SU(2), the corresponding group of rotations).
. Thus the dimension of the space of spin states is the same as that of a vector in three-dimensional space, and in fact can be shown to form a representation of SU(2), the corresponding group of rotations). dimensions with the standard decomposition into creation and annihilation operators,
dimensions with the standard decomposition into creation and annihilation operators,
![\displaystyle \left[a_k,a_{k'}^\dagger\right]=2\omega(2\pi)^3\delta^3\left(\mathbf{k}-\mathbf{k}'\right)~, \;\;\; \left[a_k,a_{k'}\right]= \left[a_k^\dagger,a_{k'}^\dagger\right]= 0~, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5Ba_k%2Ca_%7Bk%27%7D%5E%5Cdagger%5Cright%5D%3D2%5Comega%282%5Cpi%29%5E3%5Cdelta%5E3%5Cleft%28%5Cmathbf%7Bk%7D-%5Cmathbf%7Bk%7D%27%5Cright%29%7E%2C+%5C%3B%5C%3B%5C%3B+%5Cleft%5Ba_k%2Ca_%7Bk%27%7D%5Cright%5D%3D+%5Cleft%5Ba_k%5E%5Cdagger%2Ca_%7Bk%27%7D%5E%5Cdagger%5Cright%5D%3D+0%7E%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , imply exact commutativity of spacelike separated fields:
, imply exact commutativity of spacelike separated fields:![\displaystyle \begin{aligned} \left[\phi(x),\phi(y)\right]&=\int\frac{\mathrm{d}^3k\mathrm{d}^3k'}{(2\pi)^64\omega\omega'} \left( a_ka_{k'}^\dagger e^{-ikx+ik'y}+a_k^\dagger a_{k'} e^{ikx-ik'y} -a_{k'}a_{k}^\dagger e^{-ik'y+ikx}-a_{k'}^\dagger a_{k} e^{ik'y-ikx}\right)\\ &=\int\frac{\mathrm{d}^3k\mathrm{d}^3k'}{(2\pi)^64\omega\omega'}\left(\left[a_k,a_{k'}^\dagger\right]e^{-ikx+ik'y}-\left[a_{k'},a_k^\dagger\right]e^{ikx-ik'y}\right)\\ &=\int\frac{\mathrm{d}^3k}{(2\pi)^32\omega}\left( e^{-ik(x-y)}-e^{ik(x-y)}\right)=0~, \end{aligned} \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cleft%5B%5Cphi%28x%29%2C%5Cphi%28y%29%5Cright%5D%26%3D%5Cint%5Cfrac%7B%5Cmathrm%7Bd%7D%5E3k%5Cmathrm%7Bd%7D%5E3k%27%7D%7B%282%5Cpi%29%5E64%5Comega%5Comega%27%7D+%5Cleft%28+a_ka_%7Bk%27%7D%5E%5Cdagger+e%5E%7B-ikx%2Bik%27y%7D%2Ba_k%5E%5Cdagger+a_%7Bk%27%7D+e%5E%7Bikx-ik%27y%7D+-a_%7Bk%27%7Da_%7Bk%7D%5E%5Cdagger+e%5E%7B-ik%27y%2Bikx%7D-a_%7Bk%27%7D%5E%5Cdagger+a_%7Bk%7D+e%5E%7Bik%27y-ikx%7D%5Cright%29%5C%5C+%26%3D%5Cint%5Cfrac%7B%5Cmathrm%7Bd%7D%5E3k%5Cmathrm%7Bd%7D%5E3k%27%7D%7B%282%5Cpi%29%5E64%5Comega%5Comega%27%7D%5Cleft%28%5Cleft%5Ba_k%2Ca_%7Bk%27%7D%5E%5Cdagger%5Cright%5De%5E%7B-ikx%2Bik%27y%7D-%5Cleft%5Ba_%7Bk%27%7D%2Ca_k%5E%5Cdagger%5Cright%5De%5E%7Bikx-ik%27y%7D%5Cright%29%5C%5C+%26%3D%5Cint%5Cfrac%7B%5Cmathrm%7Bd%7D%5E3k%7D%7B%282%5Cpi%29%5E32%5Comega%7D%5Cleft%28+e%5E%7B-ik%28x-y%29%7D-e%5E%7Bik%28x-y%29%7D%5Cright%29%3D0%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
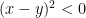 , there exists a continuous Lorentz transformation that interchanges the order of events; in particular, this allows us to take
, there exists a continuous Lorentz transformation that interchanges the order of events; in particular, this allows us to take 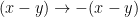 in one of the two terms, whereupon the commutator vanishes. A similar argument can be made for commutators of the form
in one of the two terms, whereupon the commutator vanishes. A similar argument can be made for commutators of the form ![{\left[\phi^\dagger(x),\phi(y)\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%5B%5Cphi%5E%5Cdagger%28x%29%2C%5Cphi%28y%29%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.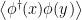 does not vanish, even for
does not vanish, even for  , defined via
, defined via
 is the number operator that counts the number of particles in a state within a given spatial region
is the number operator that counts the number of particles in a state within a given spatial region ![\displaystyle \left[\mathcal{N}(\mathbf{x},t),\mathcal{N}(\mathbf{y},t)\right]\neq0~, \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cmathcal%7BN%7D%28%5Cmathbf%7Bx%7D%2Ct%29%2C%5Cmathcal%7BN%7D%28%5Cmathbf%7By%7D%2Ct%29%5Cright%5D%5Cneq0%7E%2C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
 ,
, 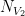 , (where
, (where  and
and  ) will exhibit an interference that falls off exponentially with the minimum spacelike separation between
) will exhibit an interference that falls off exponentially with the minimum spacelike separation between 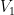 and
and  . In other words, a one-particle state can be localized with respect to the number density operator only with an energy density that falls off exponentially at a rate determined by the Compton wavelength, i.e.,
. In other words, a one-particle state can be localized with respect to the number density operator only with an energy density that falls off exponentially at a rate determined by the Compton wavelength, i.e.,  . This is why it is meaningless to speak of “particles” below their Compton wavelength. Incidentally, lest one worry, the above is a uniquely quantum phenomenon: one recovers
. This is why it is meaningless to speak of “particles” below their Compton wavelength. Incidentally, lest one worry, the above is a uniquely quantum phenomenon: one recovers ![{\left[N_{V_1},N_{V_2}\right]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%5BN_%7BV_1%7D%2CN_%7BV_2%7D%5Cright%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) in the non-relativistic limit,
in the non-relativistic limit,  . (In fact, the discussion is even more subtle: technically speaking,
. (In fact, the discussion is even more subtle: technically speaking, 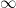 , the total scattering amplitude approaches the product of the independent scattering amplitudes of the particles in each region. Ultimately, this is what we observe in the laboratory, and as such one could consider this an operational definition of locality. But it is microcausality that ensures the analyticity of the S-matrix (via the singularity structure, which inhibits future interactions from influencing the past) on which the covariant formulation of clustering rests.
, the total scattering amplitude approaches the product of the independent scattering amplitudes of the particles in each region. Ultimately, this is what we observe in the laboratory, and as such one could consider this an operational definition of locality. But it is microcausality that ensures the analyticity of the S-matrix (via the singularity structure, which inhibits future interactions from influencing the past) on which the covariant formulation of clustering rests. , which is consistent with simply counting the obvious (particulate) degrees of freedom in the examples above. Black hole entropy, in stark contrast,
, which is consistent with simply counting the obvious (particulate) degrees of freedom in the examples above. Black hole entropy, in stark contrast,  . Bekenstein’s original motivation for this proposal hinged largely on Hawking’s 1971 result that the surface area of a black hole cannot decrease in any classical process (the so-called “area theorem”). This lead Bekenstein to propose an analogy between black holes and statistical thermodynamics, which has since been enshrined in the laws of
. Bekenstein’s original motivation for this proposal hinged largely on Hawking’s 1971 result that the surface area of a black hole cannot decrease in any classical process (the so-called “area theorem”). This lead Bekenstein to propose an analogy between black holes and statistical thermodynamics, which has since been enshrined in the laws of  , on the horizon is constant. This implies that surface gravity is analogous to temperature.
, on the horizon is constant. This implies that surface gravity is analogous to temperature.
 .
.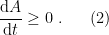

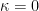 .
.

 , in the latter formula lest the reader be disturbed by the mismatch in dimensions between
, in the latter formula lest the reader be disturbed by the mismatch in dimensions between 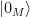 corresponds to the Kruskal or Hartle-Hawking vacuum
corresponds to the Kruskal or Hartle-Hawking vacuum 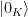 , while the final Schwarzschild vacuum
, while the final Schwarzschild vacuum  is analogous to Rindler space
is analogous to Rindler space 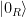 . While the Kruskal modes are defined on the entire manifold, a Rindler observer, who has access to only the exterior spacetime, will perceive a thermal vacuum corresponding to tracing out the degrees of freedom behind the horizon. This is the mechanism that underlies the Unruh effect).
. While the Kruskal modes are defined on the entire manifold, a Rindler observer, who has access to only the exterior spacetime, will perceive a thermal vacuum corresponding to tracing out the degrees of freedom behind the horizon. This is the mechanism that underlies the Unruh effect).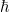 in the path integral technically places us beyond the domain of the latter). The basic idea is to compute the path integral for the black hole by Wick rotating to Euclidean signature, in which the geometry pinches off smoothly at the horizon. This corresponds to the fixed point of the
in the path integral technically places us beyond the domain of the latter). The basic idea is to compute the path integral for the black hole by Wick rotating to Euclidean signature, in which the geometry pinches off smoothly at the horizon. This corresponds to the fixed point of the  symmetry, which we obtain by periodically identifying Euclidean time to avoid a conical deficit. The contribution from the fixed point dominates the path integral
symmetry, which we obtain by periodically identifying Euclidean time to avoid a conical deficit. The contribution from the fixed point dominates the path integral 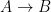 . We can make this more precise by considering the Rindler decomposition of the vacuum,
. We can make this more precise by considering the Rindler decomposition of the vacuum,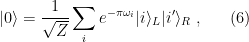
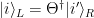 , where
, where  is
is 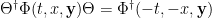 ). Now consider decomposing a free scalar field into modes of definite boost energy
). Now consider decomposing a free scalar field into modes of definite boost energy  ) in the right (left) Rindler wedge. Then the vacuum state can be equivalently written as a product state over all modes:
) in the right (left) Rindler wedge. Then the vacuum state can be equivalently written as a product state over all modes:
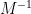 , the size of the black hole, and thus the particle interpretation breaks down long before one reaches the horizon. It is therefore meaningless to speak of the radiation as being localized in this manner. (Just to be clear, this of course does not imply that an infalling observer won’t see particles as usual in her own reference frame, as per the equivalence principle. It is merely the blueshifting of Hawking modes back from infinity that is ill-defined; the associated divergence is simply the statement that, from the perspective of an external observer, time appears to stop at the horizon.) The related question of where, precisely, the Hawking radiation originates has not been settled, though the evidence suggests that the adjective “precisely” may lose out to nonlocality as well.
, the size of the black hole, and thus the particle interpretation breaks down long before one reaches the horizon. It is therefore meaningless to speak of the radiation as being localized in this manner. (Just to be clear, this of course does not imply that an infalling observer won’t see particles as usual in her own reference frame, as per the equivalence principle. It is merely the blueshifting of Hawking modes back from infinity that is ill-defined; the associated divergence is simply the statement that, from the perspective of an external observer, time appears to stop at the horizon.) The related question of where, precisely, the Hawking radiation originates has not been settled, though the evidence suggests that the adjective “precisely” may lose out to nonlocality as well. correction, which would destroy the very semiclassical physics they were intended to save. But the possibility of encoding information in such a manner has not been ruled out. In fact, arguments from holography — more specifically the AdS/CFT correspondence — indicate that unitarity is indeed preserved, and consequently the belief that the information is somehow encoded in the Hawking radiation is currently the most popular position.
correction, which would destroy the very semiclassical physics they were intended to save. But the possibility of encoding information in such a manner has not been ruled out. In fact, arguments from holography — more specifically the AdS/CFT correspondence — indicate that unitarity is indeed preserved, and consequently the belief that the information is somehow encoded in the Hawking radiation is currently the most popular position. to contain an (in principle) infinite number of internal states! This hardly seems a reasonable resolution, and remnants are generally disfavored for these and other reasons. That said, it is worth commenting that once the black hole approaches the Planck scale, semi-classical gravity breaks down, and a full theory of quantum gravity is needed to specify what happens in the final moments of a black hole’s life.
to contain an (in principle) infinite number of internal states! This hardly seems a reasonable resolution, and remnants are generally disfavored for these and other reasons. That said, it is worth commenting that once the black hole approaches the Planck scale, semi-classical gravity breaks down, and a full theory of quantum gravity is needed to specify what happens in the final moments of a black hole’s life. .
. be maximally entangled, as discussed above (more generally, the exterior mode is purified by its interior partner), while purity of the final radiation — i.e., unitarity — requires that
be maximally entangled, as discussed above (more generally, the exterior mode is purified by its interior partner), while purity of the final radiation — i.e., unitarity — requires that  . But this violates the monogamy of quantum entanglement, and thus it appears that at least one of the assumptions must be modified. AMPS chose the equivalence principle as the least egregious sacrifice. This would imply that an infalling observer indeed encounters the hot membrane perceived by her external collaborator—and is completely incinerated; hence the name “firewall”.
. But this violates the monogamy of quantum entanglement, and thus it appears that at least one of the assumptions must be modified. AMPS chose the equivalence principle as the least egregious sacrifice. This would imply that an infalling observer indeed encounters the hot membrane perceived by her external collaborator—and is completely incinerated; hence the name “firewall”.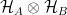 is not necessarily orthogonal if we restrict to subsystem
is not necessarily orthogonal if we restrict to subsystem 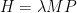 , where
, where 
 . (Note that we are implicitly assuming that either
. (Note that we are implicitly assuming that either ![{\left[M,H_0\right]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%5BM%2CH_0%5Cright%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  is the original, unperturbed Hamiltonian, or that the measurement occurs so quickly that free evolution of the system can be neglected throughout. We’re also suppressing hats/bold-print on the operators, since this is clear from context).
is the original, unperturbed Hamiltonian, or that the measurement occurs so quickly that free evolution of the system can be neglected throughout. We’re also suppressing hats/bold-print on the operators, since this is clear from context).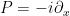 is the generator of translations for the pointer, it shifts the position-space wavepacket thereof by some amount
is the generator of translations for the pointer, it shifts the position-space wavepacket thereof by some amount  :
:  . Thus, if the system is initially in a superposition of
. Thus, if the system is initially in a superposition of  , then after time
, then after time  it will evolve to
it will evolve to
 (namely,
(namely,  , which can be guaranteed by making the pointer sufficiently massive since
, which can be guaranteed by making the pointer sufficiently massive since  ), observing that the position of the pointer has shifted by
), observing that the position of the pointer has shifted by  is tantamount to measuring the eigenstate
is tantamount to measuring the eigenstate 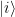 , which occurs with probability
, which occurs with probability 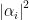 . In this manner, the initial state of the quantum system, call it
. In this manner, the initial state of the quantum system, call it  , is projected to
, is projected to  . This is von Neumann’s model of orthogonal measurement, which involves so-called projection valued measurements, or PVMs.
. This is von Neumann’s model of orthogonal measurement, which involves so-called projection valued measurements, or PVMs.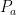 such that
such that  . Carrying out the measurement procedure above takes the initial (pure) state
. Carrying out the measurement procedure above takes the initial (pure) state  to
to

 , it has the properties
, it has the properties 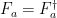 ,
,  , and
, and 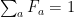 , where
, where  . The idea is that a POVM element
. The idea is that a POVM element  is assigned to every possible measurement result such that
is assigned to every possible measurement result such that  (hence the requirement that these sum to 1).
(hence the requirement that these sum to 1). such that
such that  . Introducing these operators allows one to express the state immediately after measurement in the usual manner:
. Introducing these operators allows one to express the state immediately after measurement in the usual manner: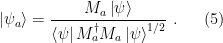
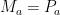 identically. The difference here is that in the case of a POVM, repeated measurement will not necessarily yield the same result. This is because unlike the
identically. The difference here is that in the case of a POVM, repeated measurement will not necessarily yield the same result. This is because unlike the  , which is used in decomposing an observable
, which is used in decomposing an observable  , corresponds to the special case of a POVM with
, corresponds to the special case of a POVM with  .
. , containing an initial state
, containing an initial state 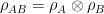 and a PVM given by
and a PVM given by  , so we define a new set of operators
, so we define a new set of operators 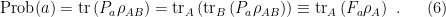
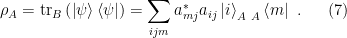
 is a dummy index, this requires two indices when written in matrix notation,
is a dummy index, this requires two indices when written in matrix notation,  . This implies that four indices will label the tensor product
. This implies that four indices will label the tensor product 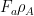 therefore carries two free indices (since
therefore carries two free indices (since  ), and similarly
), and similarly  carries four, all of which will be summed over when taking the appropriate traces. Hence the above expression, in component form, is
carries four, all of which will be summed over when taking the appropriate traces. Hence the above expression, in component form, is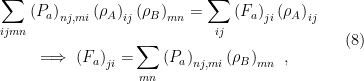
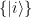 ,
,  and
and  ,
, 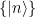 are orthonormal bases for
are orthonormal bases for  , respectively. With this expression for
, respectively. With this expression for  . As we have emphasized however, they are not necessarily orthogonal, which is again the crucial difference between POVMs and PVMs. Indeed, the number of
. As we have emphasized however, they are not necessarily orthogonal, which is again the crucial difference between POVMs and PVMs. Indeed, the number of  . Since evolution of the total bipartite system is unitary, it is described by the action of a unitary operator
. Since evolution of the total bipartite system is unitary, it is described by the action of a unitary operator  ,
,
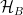 , and
, and 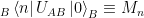 is an operator acting on
is an operator acting on 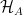 . Note that it follows from the unitarity of
. Note that it follows from the unitarity of 
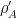 succinctly as
succinctly as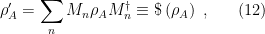
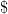 is a linear map that takes density matrices to density matrices (linear operators to linear operators). Such a map, when the above property of
is a linear map that takes density matrices to density matrices (linear operators to linear operators). Such a map, when the above property of  is satisfied, is called a superoperator, which we’ve written here in the so-called operator sum or Kraus representation. The operator sum representation of a given superoperator
is satisfied, is called a superoperator, which we’ve written here in the so-called operator sum or Kraus representation. The operator sum representation of a given superoperator 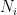 . However, any two operator sum representations of the same superoperator are related by a unitary change of basis, e.g.,
. However, any two operator sum representations of the same superoperator are related by a unitary change of basis, e.g.,  (in other words, the
(in other words, the  considered above).
considered above). inherits the usual properties from
inherits the usual properties from 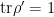 if
if 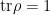 ). But these are not quite sufficient to ensure that our bipartite system evolves unitarily. The basic reason is that we are limiting our attention to subsystem
). But these are not quite sufficient to ensure that our bipartite system evolves unitarily. The basic reason is that we are limiting our attention to subsystem  instead satisfy complete positivity: given any extension of
instead satisfy complete positivity: given any extension of  is positive for all such extensions. For an example of the necessity of this requirement, see Preskill p97-98 for an exposition of the transposition operator,
is positive for all such extensions. For an example of the necessity of this requirement, see Preskill p97-98 for an exposition of the transposition operator,  , which is a positive operator that is not completely positive.
, which is a positive operator that is not completely positive.
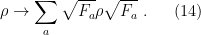


 with probability
with probability

 describes the evolution from
describes the evolution from  to
to  , and
, and 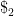 describes the evolution from
describes the evolution from 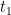 to
to  , then
, then  is a superoperator describing the evolution from
is a superoperator describing the evolution from 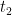 . But the inverse of a superopertor is only a superopertor if it is unitary. This is in stark contrast to unitary evolution, which is perfectly invertible: we can run the equations backwards as well as forwards. Not so for superoperators: inverting
. But the inverse of a superopertor is only a superopertor if it is unitary. This is in stark contrast to unitary evolution, which is perfectly invertible: we can run the equations backwards as well as forwards. Not so for superoperators: inverting 