
There’s a fundamental problem in gauge theory known as Hilbert space factorization. This has its roots in the issue of how local quantities (e.g., operators) are defined in quantum field theory, and has consequences for everything from entanglement and holographic reconstruction to quantum gravity at large.
In quantum mechanics, one is free to split the Hilbert space 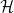
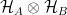
Upon quantizing, the fields are elevated to operators on Fock space, which is the Hilbert space completion of the direct sum of the (anti)symmetric tensors in the tensor product of single-particle Hilbert spaces:

where 
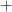

That is, at least, before one introduces gauge fields. The associated gauge constraints (e.g., Gauss’s law) obstruct the factorization of the global Hilbert space. The basic problem is that the elementary excitations for scalar fields are associated with points in space, and in this sense the field operators can be localized to either 



To circumvent this, the trick employed in certain lattice models is to enlarge the Hilbert space of physical states to include open strings along the boundary between 

Note that cutting the boundary results in additional degrees of freedom that emerge as a result of the factorization. One further expects that these d.o.f. should contribute to the entanglement entropy between
Of course, violating Gauss’s law is hardly a price we want to pay for a factorizable Hilbert space. Harlow’s idea that the gauge field is emergent is thus particularly elegant in this regard. In his 2015 paper, he considers the case of a 
Harlow considers in particular the case of AdS-Schwarzschild, specifically the eternal black hole dual to the thermofield double state (TFD). The two boundaries are connected through the bulk by a Wilson line that threads the bifurcation surface. However, it is not clear how to represent this bulk operator in the boundary. The problem is again that cutting the Wilson line (as in any naïve attempt to associate the part in the left- and right-bulk to the corresponding CFT) results in operators which are no longer gauge-independent, and thus violate Gauss’s law. This is precisely the same factorization issue encountered above, but it becomes even more puzzling in the context of AdS/CFT for the following reason: by construction, the global CFT in the TFD — and hence the microscopic Hilbert space of the theory — does factorize into a tensor product, seemingly in defiance of this wormhole-threading Wilson line.
To solve this problem in the 

This construction has several interesting consequences. Perhaps the most general of which is that it reduces the problem of factorization to a problem in the UV. One could argue that this was foreshadowed by results from lattice gauge theory. As explained above, there is no gauge-invariant way to cut the gauge excitations (the loop operators, i.e.,
Another implication is that the bulk must contain charged fields which transform in the fundamental representation of
As an aside, Harlow connects this construction to the weak gravity conjecture by observing that the charges cannot be so heavy as to form black holes. Indeed, a weakly-coupled gauge theory in the bulk requires the charges to be parametrically lighter than the Planck scale. This seems to demand the existence of a fundamentally-charged particle of mass 

Harlow’s analysis demonstrates that in the case of 
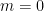
That said, the underlying lesson above still holds: the Hilbert space of the CFT dual to the wormhole does have a tensor product structure, which must be respected by the physics in the bulk. Extrapolating this same reasoning to the gravitational case (ignoring certain technical differences), this ultimately implies that the bulk spacetime must emerge in a manner consistent with this factorization. This is perhaps the most concrete sense in which the problem of Hilbert space factorization is intimately connected with emergent spacetime.
This echos my own conclusions based on holographic shadows, insofar as the wormhole’s deep interior (which I shall define momentarily) is precisely analagous to the one-sided shadow regions described in the above-linked paper, in that it lies beyond the reach of any known bulk probe. The connection between the two can be seen by starting from the TFD, and sending in shocks to create a wormhole (note that in the discussion of Harlow’s work above, the “wormhole” consisted entirely of the bifurcation surface, and had no interior in the sense that we describe here). Upon sending in the second (suitably arranged) shockwave, we obtain a region which is causally disconnected from both boundaries. I refer to this as the wormhole’s deep interior. It shares the basic feature of both holographic shadows and precursors, in that the information about the spacetime therein must be encoded in a highly non-local (indeed, apparently non-causal) manner in the boundary. But relative to both shadows and precursors, addressing the question of reconstruction in the context of multi-shock wormholes has two advantages:
- Conceptually, it makes the problem as sharp as possible. In the case of both shadows and precursors, one might suppose that the information in the CFT is encoded non-locally, such that if one had perfect knowledge of the entire boundary — and perhaps some sophisticated quantum secret sharing scheme — one could in principle reconstruct regions arbitrarily deep in bulk, since these are still causally connected to the boundary. In contrast, the wormhole’s deep interior is disconnected from the boundary for all time, which forces us to consider more subtle or esoteric alternatives.
- By starting with a completely well-behaved geometry and perturbing it with thermal-scale operators, one might hope to track the breakdown of locality to some deeper feature, such as the connection to complexity proposed by Susskind and collaborators, rather than simply attributing it to the initial state of the system (e.g., the particular matter distribution that forms the shadow, the choice of precursor encoding).
However, the causal disconnection of the deep interior is a double-edged sword: despite these conceptual advantages, it is even less clear how one might relate the interior to elements in the CFT. One might imagine starting in the TFD with a Wilson loop that threads the bifurcation surface, but it’s not obvious that it would survive the highly boosted shockwaves that create the wormhole, and even less clear how to use it to construct the gravitational degrees of freedom of interest anyway. Nonetheless, insofar as the Wilson line serves as a diagnostic of connectivity in the bulk, some recent work has focused on attempting to isolate the associated gravitational degrees of freedom as those that “sew the wormhole together”. (On this note, the statement above that the deep interior is disconnected from the boundary for all time comes with the caveat that information about the connection (whatever this means) wasn’t destroyed or otherwise hidden by the shockwave). Another approach would be to understand the boundary dual of entwinement surfaces, and attempt to use them to probe within the wormhole—but while these penetrate holographic shadows, it’s not clear that the wormhole will swallow them. Yet a third method would be to connect with the holographic complexity proposals of Susskind and collaborators, but despite initial progress in defining complexity in field theories, we’re far from a useful CFT prescription.
Understanding the wormhole’s deep interior in the CFT is tantamount to isolating the degrees of freedom that sew the spacetime together. Thus one expects that their description in the CFT will tell us how this spacetime — i.e., gravity — emerges from elements in the boundary. This is the question to which we alluded above, when we claimed that Hilbert space factorization is intimately connected to emergent spacetime. But, while the
Now, as alluded near the beginning of this post, one runs into trouble even before introducing gauge fields: Hilbert space factorization for free field theories is a lie. Indeed, it is generally believed (by the measure-zero subset of philosophically-inclined physicists who study the issue) that the description of observables as self-adjoint operators on Hilbert space is rigorously untenable. Rather, observables are identified as elements of an abstract 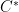
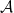
The importance of the factorization problem in this (greater) context can be seen, for example, in the Firewall paradox. In particular, most papers on the subject assume (implicitly, dare I say blithely), that the Hilbert space factorizes into an interior and exterior. I’ve expounded upon this issue elsewhere, so I won’t dwell upon it here. Suffice to say it touches on the question of ontology vs. epistemology which I’ve mentioned before, but the fact that Hilbert space factorization is an independently subtle issue makes it even more difficult to determine to which category a particular model of evaporation belongs.
Having said all that, my basic concern regarding Hilbert space factorization in quantum gravity can actually be summarized quite simply. In the emergent spacetime paradigm — as embodied by the It from Qubit collaboration — entanglement is thought to play a fundamental role in the emergence of gravity. And yet step zero of defining entanglement entropy, 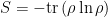
It is worth pointing out that the factorization problem may not have a resolution within quantum field theory, perhaps due to these or other foundational issues. Indeed, Harlow states that it can’t be resolved in perturbative string theory, where “the gauge fields and gravity emerge together from a non-local theory.” Such a solution must exist if the arguments from AdS/CFT above hold true, but it is not clear how to describe the emergence of gauge fields in string theory in such a way as to allow it.
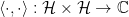 . In Dirac’s bra-ket notation, vectors (states) in
. In Dirac’s bra-ket notation, vectors (states) in  , and dual vectors (operators, which act as linear functionals on the states) are denoted
, and dual vectors (operators, which act as linear functionals on the states) are denoted  . The properties of the inner product
. The properties of the inner product 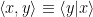 may then be written as follows:
may then be written as follows: , with equality iff
, with equality iff  .
. .
. .
.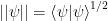 , which defines the distance between states in
, which defines the distance between states in  , since this merely amounts to choosing a representative of the equivalence class of vectors that differ by a nonzero complex scalar. In this sense, both
, since this merely amounts to choosing a representative of the equivalence class of vectors that differ by a nonzero complex scalar. In this sense, both  represent the same state; only relative phase changes between states in a superposition are physically meaningful.
represent the same state; only relative phase changes between states in a superposition are physically meaningful.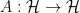 . Such an operator has a spectral representation, meaning that its eigenstates form a complete orthonormal basis in
. Such an operator has a spectral representation, meaning that its eigenstates form a complete orthonormal basis in 
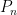 is the orthogonal projection onto the space of eigenvectors with eigenvalue
is the orthogonal projection onto the space of eigenvectors with eigenvalue 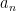 (such orthogonal projections can be proven to exist for complete inner product spaces, e.g.,
(such orthogonal projections can be proven to exist for complete inner product spaces, e.g.,  . Of course, given the unit normalization above, the projection operators satisfy
. Of course, given the unit normalization above, the projection operators satisfy 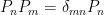 and
and  . (Note that the spectral theorem is more subtle for unbounded operators in infinite-dimensional spaces, but that will not concern us here).
. (Note that the spectral theorem is more subtle for unbounded operators in infinite-dimensional spaces, but that will not concern us here).
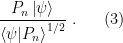
 is the generator of time translations, and its expectation value gives the energy of the state. The latter is a measurable quantity, which implies that in order to be a well-defined physical observable, the Hamiltonian operator must be self-adjoint,
is the generator of time translations, and its expectation value gives the energy of the state. The latter is a measurable quantity, which implies that in order to be a well-defined physical observable, the Hamiltonian operator must be self-adjoint, 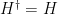 . By Stone’s theorem, the exponential of a self-adjoint operator is unitary; thus if
. By Stone’s theorem, the exponential of a self-adjoint operator is unitary; thus if  , then
, then  is a bounded linear operator on
is a bounded linear operator on  . Mathematically, this is why time evolution in quantum mechanics is unitary. Physically, this is simply the statement that time evolution preserves the inner product; i.e., that probabilities continue to sum to 1 (since, under time-evolution by a Hermitian operator
. Mathematically, this is why time evolution in quantum mechanics is unitary. Physically, this is simply the statement that time evolution preserves the inner product; i.e., that probabilities continue to sum to 1 (since, under time-evolution by a Hermitian operator 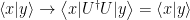 ). Note that here we’re implicitly assuming that
). Note that here we’re implicitly assuming that  , it’s just less elegant.
, it’s just less elegant.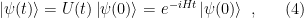
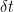 and expand both the left- and right-hand sides to first order, we have
and expand both the left- and right-hand sides to first order, we have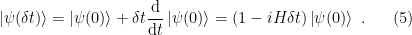

 allows us to predict the state at any future time. But as described above, measurement is probabilistic: despite our infinite ability to predict future states, we cannot make definite predictions about measurement outcomes. One of the deepest (and most controversial) aspects of quantum mechanics is how deterministic evolution can nonetheless lead to probabilistic outcomes. Preskill quite aptly refers to this juxtaposition as a “disconcerting dualism”, and we shall return to it below.
allows us to predict the state at any future time. But as described above, measurement is probabilistic: despite our infinite ability to predict future states, we cannot make definite predictions about measurement outcomes. One of the deepest (and most controversial) aspects of quantum mechanics is how deterministic evolution can nonetheless lead to probabilistic outcomes. Preskill quite aptly refers to this juxtaposition as a “disconcerting dualism”, and we shall return to it below. . Given an orthonormal basis
. Given an orthonormal basis  for
for  and
and 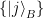 for
for  , an arbitrary pure state of
, an arbitrary pure state of 
 . We’ve referred to this as a pure state in contrast to a mixed state; the former correspond to rays in the total Hilbert space, while the latter do not. This is the first crucial correction alluded to above.
. We’ve referred to this as a pure state in contrast to a mixed state; the former correspond to rays in the total Hilbert space, while the latter do not. This is the first crucial correction alluded to above. . Its expectation value is
. Its expectation value is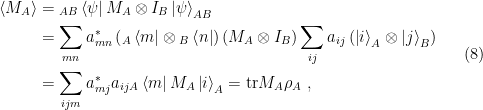

 is an operator-valued function given by summing over the basis elements of
is an operator-valued function given by summing over the basis elements of 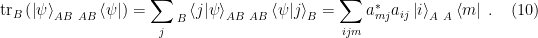
 above then follows by the cyclic property of the trace.
above then follows by the cyclic property of the trace. .
.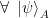 ,
, 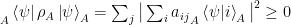 .
. (since
(since 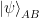 is normalized).
is normalized).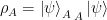 , which is the projection operator onto the state (that is, onto the one-dimensional space spanned by
, which is the projection operator onto the state (that is, onto the one-dimensional space spanned by  ). The density matrix for a pure state is therefore idempotent,
). The density matrix for a pure state is therefore idempotent,  . In contrast, for a general (mixed) state in the diagonal basis
. In contrast, for a general (mixed) state in the diagonal basis  ,
, 
 and
and  . It follows that a pure state has only a single non-zero eigenvalue, which must be 1, while a mixed state contains two or more terms in the sum (and
. It follows that a pure state has only a single non-zero eigenvalue, which must be 1, while a mixed state contains two or more terms in the sum (and  ).
). is an incoherent superposition of eigenstates
is an incoherent superposition of eigenstates  acting on the subsystem described by
acting on the subsystem described by  is
is
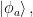 each of which occurs with probability
each of which occurs with probability  . But we’re not quite ready to address the associated interpretive questions just yet.
. But we’re not quite ready to address the associated interpretive questions just yet.
 -axis. Measuring the spin along the x-axis will result in
-axis. Measuring the spin along the x-axis will result in  or
or  with probability
with probability 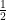 each; e.g., from (2):
each; e.g., from (2):

 ), we can obtain the state along an arbitrary axis
), we can obtain the state along an arbitrary axis  by applying a suitable unitary transformation to
by applying a suitable unitary transformation to 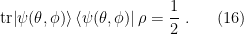
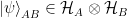 may be expanded as
may be expanded as 
 . A priori,
. A priori,  need not be orthonormal. However, since
need not be orthonormal. However, since 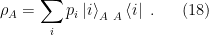


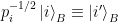 , we find that we can express the bipartite state (17) as
, we find that we can express the bipartite state (17) as 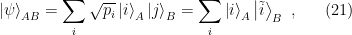
 using the same orthonormal basis for
using the same orthonormal basis for  have the same nonzero eigenvalues, e.g.,
have the same nonzero eigenvalues, e.g.,
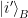 gets paired with which
gets paired with which  ).
).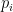 . Otherwise, the state is entangled. If all the Schmidt coefficients are equal (and non-zero), then the state is maximally entangled. On account of this classification, it is common to associated a Schmidt number to the state
. Otherwise, the state is entangled. If all the Schmidt coefficients are equal (and non-zero), then the state is maximally entangled. On account of this classification, it is common to associated a Schmidt number to the state 
 , which further implies that
, which further implies that  and
and  are each pure. In contrast, an entangled state, with Schmidt number greater than 1, has no such direct product expression, in which case
are each pure. In contrast, an entangled state, with Schmidt number greater than 1, has no such direct product expression, in which case 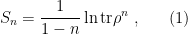
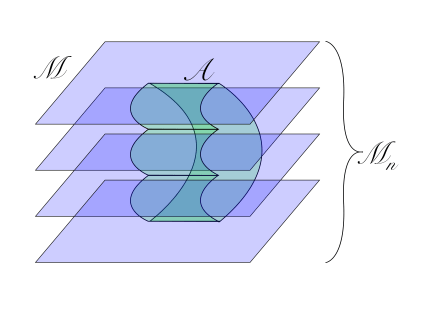
 copies of the original manifold
copies of the original manifold 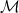 , and glue them together cyclically along the cuts formed by the region
, and glue them together cyclically along the cuts formed by the region  , and the
, and the 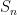 . The entanglement entropy associated to the region
. The entanglement entropy associated to the region 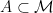 is then recovered in the limit as
is then recovered in the limit as 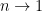 :
:
 .
.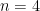 . Each blue sheet represents a copy of the original boundary manifold
. Each blue sheet represents a copy of the original boundary manifold 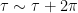 at each of the two boundary points of
at each of the two boundary points of 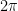 takes us to the second copy,
takes us to the second copy, 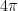 to the third,
to the third, 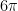 to the fourth, and finally
to the fourth, and finally 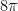 back to the first; that is,
back to the first; that is, 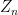 symmetry that takes
symmetry that takes  .
.

 is the Euclidean action on
is the Euclidean action on  is the thermal partition function at inverse temperature
is the thermal partition function at inverse temperature  , with time-evolution operator
, with time-evolution operator 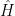 . Taking
. Taking 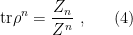
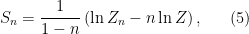
 . We then move into the bulk through the differentiate dictionary, which equates the bulk (that is, the on-shell bulk action at large
. We then move into the bulk through the differentiate dictionary, which equates the bulk (that is, the on-shell bulk action at large  ) and boundary partition functions. Expanding the partition function on
) and boundary partition functions. Expanding the partition function on ![\displaystyle Z_n\equiv Z[\mathcal{M}_n]=e^{-S[B_n]+\ldots} \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z_n%5Cequiv+Z%5B%5Cmathcal%7BM%7D_n%5D%3De%5E%7B-S%5BB_n%5D%2B%5Cldots%7D+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
 corrections; we’ll drop these henceforth.
corrections; we’ll drop these henceforth. , and hence the
, and hence the 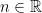 . But for non-integer
. But for non-integer  are simply
are simply  , from which we can extend
, from which we can extend 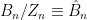 , which is regular everywhere except at the fixed points of the
, which is regular everywhere except at the fixed points of the 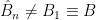 . This can be seen in the illustration below. The left-most image is the original geometry, with a “bump” for illustration. In the middle image, we’ve cut the boundary
. This can be seen in the illustration below. The left-most image is the original geometry, with a “bump” for illustration. In the middle image, we’ve cut the boundary  copies, and glued them together to form the
copies, and glued them together to form the  with
with 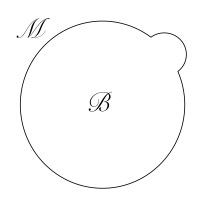
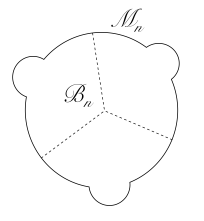
 ; we shall denote this surface
; we shall denote this surface  . As mentioned above, the fixed points on the boundary orbifold are simply
. As mentioned above, the fixed points on the boundary orbifold are simply 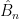 is the boundary orbifold
is the boundary orbifold 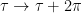 , where
, where  is the angular coordinate around
is the angular coordinate around ![\displaystyle S\left[B_n\right]=nS[\hat{B}_n]~, \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%5Cleft%5BB_n%5Cright%5D%3DnS%5B%5Chat%7BB%7D_n%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{S\left[B_n\right]}](https://s0.wp.com/latex.php?latex=%7BS%5Cleft%5BB_n%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , is simply
, is simply ![{S[\hat{B}_n]}](https://s0.wp.com/latex.php?latex=%7BS%5B%5Chat%7BB%7D_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This expression is useful because, in conjunction with the above expression for the partition function (dropping the higher order terms), we may write the Rényi entropy as
. This expression is useful because, in conjunction with the above expression for the partition function (dropping the higher order terms), we may write the Rényi entropy as![\displaystyle S_n=\frac{n}{n-1}\left( S[\hat{B}_n]-S[B]\right) \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S_n%3D%5Cfrac%7Bn%7D%7Bn-1%7D%5Cleft%28+S%5B%5Chat%7BB%7D_n%5D-S%5BB%5D%5Cright%29+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
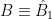 is simply the original bulk dual of
is simply the original bulk dual of 
 are indices in the
are indices in the  plane orthogonal to
plane orthogonal to  are indices along
are indices along  is the extrinsic curvature tensor of
is the extrinsic curvature tensor of  there). This is called the squashed cone because the first term resembles the line element in polar coordinates (the “cone”; recall the familiar
there). This is called the squashed cone because the first term resembles the line element in polar coordinates (the “cone”; recall the familiar  running over
running over  is
is  as follows: rewriting the metric in terms of the proper distance
as follows: rewriting the metric in terms of the proper distance  , we have
, we have

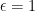 , the deficit angle is
, the deficit angle is
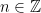 , and therefore (to leading order) we must have
, and therefore (to leading order) we must have  .
. , the
, the  -component of the Einstein equation is
-component of the Einstein equation is
 is the trace of the extrinsic curvature. The first term is clearly divergent as
is the trace of the extrinsic curvature. The first term is clearly divergent as  (and hence less divergent in this limit).
(and hence less divergent in this limit). divergence on the r.h.s. must vanish. This implies that we must have
divergence on the r.h.s. must vanish. This implies that we must have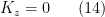
![\displaystyle \begin{aligned} \lim_{n\rightarrow1}S_n&=\lim_{n\rightarrow1}\frac{n}{n-1}\left( S[\hat{B}_n]-S[B]\right)\\ &=\left[S[\hat{B}_n]-S[B]+n\left(\partial_nS[\hat{B}_n]-\partial_nS[B]\right)\right]\bigg|_{n=1}\\ &=\partial_nS[\hat{B}_n]\bigg|_{n=1}=S~, \end{aligned} \ \ \ \ \ (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clim_%7Bn%5Crightarrow1%7DS_n%26%3D%5Clim_%7Bn%5Crightarrow1%7D%5Cfrac%7Bn%7D%7Bn-1%7D%5Cleft%28+S%5B%5Chat%7BB%7D_n%5D-S%5BB%5D%5Cright%29%5C%5C+%26%3D%5Cleft%5BS%5B%5Chat%7BB%7D_n%5D-S%5BB%5D%2Bn%5Cleft%28%5Cpartial_nS%5B%5Chat%7BB%7D_n%5D-%5Cpartial_nS%5BB%5D%5Cright%29%5Cright%5D%5Cbigg%7C_%7Bn%3D1%7D%5C%5C+%26%3D%5Cpartial_nS%5B%5Chat%7BB%7D_n%5D%5Cbigg%7C_%7Bn%3D1%7D%3DS%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0&c=20201002)
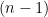 . (In going to the second line, l’Hospital’s rule is justified since
. (In going to the second line, l’Hospital’s rule is justified since  ). This will introduce boundary terms, which — as in the aforementioned Gibbons-Hawking result — turn out to be all-important.
). This will introduce boundary terms, which — as in the aforementioned Gibbons-Hawking result — turn out to be all-important. there is no conical defect, and therefore the only contribution must be from boundary terms in the action. Since
there is no conical defect, and therefore the only contribution must be from boundary terms in the action. Since 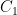 is non-singular, it gives no contribution, and hence we should excise a small region around
is non-singular, it gives no contribution, and hence we should excise a small region around 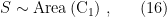
![{S[B_n]=nS[\hat B_n]}](https://s0.wp.com/latex.php?latex=%7BS%5BB_n%5D%3DnS%5B%5Chat+B_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The l.h.s. is the bulk dual of the entire
. The l.h.s. is the bulk dual of the entire  .
.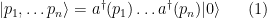
 . Individual modes simply can’t be localized within a Schwarzschild radius from the horizon (and it’s rather difficult to imagine how the interior mode can fit at all). Of course, as Freivogel has pointed out, it is possible to localize wave packets within the zone, and even to entangle them across Rindler horizons, but the implications for Hawking radiation in this case are less immediately clear (the radiation does not, as far as we know, come out in conveniently localized Gaussian packets). However, there is a deeper, non-model-specific reason to suspect that the pair picture breaks down, which goes by the name of “scrambling.”
. Individual modes simply can’t be localized within a Schwarzschild radius from the horizon (and it’s rather difficult to imagine how the interior mode can fit at all). Of course, as Freivogel has pointed out, it is possible to localize wave packets within the zone, and even to entangle them across Rindler horizons, but the implications for Hawking radiation in this case are less immediately clear (the radiation does not, as far as we know, come out in conveniently localized Gaussian packets). However, there is a deeper, non-model-specific reason to suspect that the pair picture breaks down, which goes by the name of “scrambling.” , which will approach thermal equilibrium as the system thermalizes. This is just the statement that entropy approaches its maximum value. We say that the total system has “scrambled” when any subsystem with
, which will approach thermal equilibrium as the system thermalizes. This is just the statement that entropy approaches its maximum value. We say that the total system has “scrambled” when any subsystem with  has maximum entanglement entropy. The reason for the terminology is that at this point, no information is recoverable from less than half the total degrees of freedom.
has maximum entanglement entropy. The reason for the terminology is that at this point, no information is recoverable from less than half the total degrees of freedom.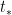 , and depends on the system under study. But the key point for our discussion is that black holes are the fastest scramblers in the universe, with
, and depends on the system under study. But the key point for our discussion is that black holes are the fastest scramblers in the universe, with  (where
(where  ). In such a system, every degree of freedom is directly coupled to every other, so that information diffuses maximally rapidly. (Several papers by Susskind and collaborators discuss this in more detail).
). In such a system, every degree of freedom is directly coupled to every other, so that information diffuses maximally rapidly. (Several papers by Susskind and collaborators discuss this in more detail). . This is the amount of time it takes for the infalling partner mode to become entangled with the entire black hole. This is fast, about
. This is the amount of time it takes for the infalling partner mode to become entangled with the entire black hole. This is fast, about 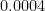 seconds for a solar mass black hole. Clearly, it makes no sense to speak of pairwise entangled particles for more than an instant, let alone over the lifetime of the black hole, against which the current age of the universe is nothing. Therefore the outgoing Hawking mode must be entangled, not with its partner, but with the entire black hole.
seconds for a solar mass black hole. Clearly, it makes no sense to speak of pairwise entangled particles for more than an instant, let alone over the lifetime of the black hole, against which the current age of the universe is nothing. Therefore the outgoing Hawking mode must be entangled, not with its partner, but with the entire black hole.
 is the Hilbert space of the initial (pure state) matter that formed the hole (equivalently, the hole before any Hawking pairs are emitted), and
is the Hilbert space of the initial (pure state) matter that formed the hole (equivalently, the hole before any Hawking pairs are emitted), and  is the Hilbert space of created pairs. The states in this latter space are of the form
is the Hilbert space of created pairs. The states in this latter space are of the form
 ) and exterior (
) and exterior ( ) modes. After
) modes. After 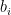 and the interior, which consists of
and the interior, which consists of 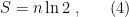
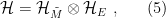
 subsuming the interior partner, while
subsuming the interior partner, while  contains the exterior mode. States in this total Hilbert space have the form
contains the exterior mode. States in this total Hilbert space have the form
 represent the state of the black hole where the partner mode is either 0 or 1, respectively. Crucially, black holes states in this factorization contain one-less bit than before the photon was emitted (since one bit moved from
represent the state of the black hole where the partner mode is either 0 or 1, respectively. Crucially, black holes states in this factorization contain one-less bit than before the photon was emitted (since one bit moved from ![\displaystyle Z=\int\mathcal{D}g\mathcal{D}\phi e^{iI[\phi]} \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3D%5Cint%5Cmathcal%7BD%7Dg%5Cmathcal%7BD%7D%5Cphi+e%5E%7BiI%5B%5Cphi%5D%7D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is the action functional of the fields
is the action functional of the fields  (to avoid confusion, we’ll use
(to avoid confusion, we’ll use  for entropy). Gibbons and Hawking begin by pointing out that, in the case of black holes, the presence of spacetime singularities prevents one from evaluating the action. However, one can side-step this difficulty by Wick rotating to Euclidean signature, whereupon the geometry pinches off smoothly at the event horizon, thus providing one with a non-singular, compact manifold on which to evaluate the action. Let’s see how this works.
for entropy). Gibbons and Hawking begin by pointing out that, in the case of black holes, the presence of spacetime singularities prevents one from evaluating the action. However, one can side-step this difficulty by Wick rotating to Euclidean signature, whereupon the geometry pinches off smoothly at the event horizon, thus providing one with a non-singular, compact manifold on which to evaluate the action. Let’s see how this works. dimensions, the gravitational action is
dimensions, the gravitational action is
 contains second-order derivatives with respect to the metric:
contains second-order derivatives with respect to the metric:![\displaystyle R=2g^{\mu\nu}\left(\Gamma^\rho_{\mu\left[\nu,\rho\right]}+\Gamma^\sigma_{\mu\left[\nu\right.}\Gamma^\rho_{\left.\rho\right]\sigma}\right)~,\;\;\; \Gamma_{\rho\mu\nu}=\frac{1}{2}\left( g_{\rho\mu,\nu}+g_{\rho\nu,\mu}-g_{\mu\nu,\rho}\right)~, \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R%3D2g%5E%7B%5Cmu%5Cnu%7D%5Cleft%28%5CGamma%5E%5Crho_%7B%5Cmu%5Cleft%5B%5Cnu%2C%5Crho%5Cright%5D%7D%2B%5CGamma%5E%5Csigma_%7B%5Cmu%5Cleft%5B%5Cnu%5Cright.%7D%5CGamma%5E%5Crho_%7B%5Cleft.%5Crho%5Cright%5D%5Csigma%7D%5Cright%29%7E%2C%5C%3B%5C%3B%5C%3B+%5CGamma_%7B%5Crho%5Cmu%5Cnu%7D%3D%5Cfrac%7B1%7D%7B2%7D%5Cleft%28+g_%7B%5Crho%5Cmu%2C%5Cnu%7D%2Bg_%7B%5Crho%5Cnu%2C%5Cmu%7D-g_%7B%5Cmu%5Cnu%2C%5Crho%7D%5Cright%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)

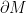 . The second term is known as the Gibbons-Hawking-York boundary term, where
. The second term is known as the Gibbons-Hawking-York boundary term, where  is the induced metric on
is the induced metric on  is the trace of the second fundamental form. (Recall that the first fundamental form is the inner product induced on the tangent space of a surface
is the trace of the second fundamental form. (Recall that the first fundamental form is the inner product induced on the tangent space of a surface 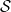 in
in 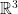 by the dot product on the latter. The second fundamental form is a quadratic form on the tangent plane of
by the dot product on the latter. The second fundamental form is a quadratic form on the tangent plane of  to the boundary term that depends only on the induced metric
to the boundary term that depends only on the induced metric  , it can be absorbed in the normalization of the measure on the space of all metrics. For convenience, we choose this constant so that in the asymptotically flat spacetimes with which we’re concerned,
, it can be absorbed in the normalization of the measure on the space of all metrics. For convenience, we choose this constant so that in the asymptotically flat spacetimes with which we’re concerned,  for the flat-space metric
for the flat-space metric 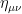 . Therefore
. Therefore 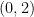 -tensor, and hence does not have a trace in the strictest sense (since the trace should not be coordinate dependent, while
-tensor, and hence does not have a trace in the strictest sense (since the trace should not be coordinate dependent, while  clearly is). Thus when one speaks of the trace of
clearly is). Thus when one speaks of the trace of  (this last is a
(this last is a 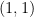 -tensor, and is therefore coordinate independent, as desired).
-tensor, and is therefore coordinate independent, as desired).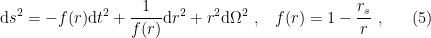
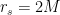 . We shall henceforth suppress the 2-sphere
. We shall henceforth suppress the 2-sphere  , as it plays no role in the following. As is well-known, the Schwarzschild metric has singularities at
, as it plays no role in the following. As is well-known, the Schwarzschild metric has singularities at  and
and  , but the latter is merely a coordinate singularity and can by removed by transforming to (among other things) Kruskal coordinates:
, but the latter is merely a coordinate singularity and can by removed by transforming to (among other things) Kruskal coordinates:
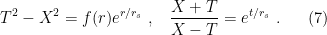
 and
and  change as one crosses to the interior, there’s nothing pathological at the horizon itself. Additionally, note that the curvature singularity
change as one crosses to the interior, there’s nothing pathological at the horizon itself. Additionally, note that the curvature singularity  .
. . Aside from the obvious sign change in the metric, this changes the definition of
. Aside from the obvious sign change in the metric, this changes the definition of 
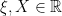 , we must have
, we must have  . In other words, the Euclidean black hole has no interior; the geometry stops at the horizon!
. In other words, the Euclidean black hole has no interior; the geometry stops at the horizon!

 , we have
, we have
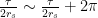 to avoid a conical deficit. This is one of many ways to see that Wick rotation leads to periodicity in imaginary time.
to avoid a conical deficit. This is one of many ways to see that Wick rotation leads to periodicity in imaginary time. , from the suppressed 2-sphere
, from the suppressed 2-sphere  . Note that, as explained above, the geometry pinches off smoothly at the horizon: the end-point at the left is at
. Note that, as explained above, the geometry pinches off smoothly at the horizon: the end-point at the left is at  .
.
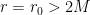 , whose boundary
, whose boundary  (periodic time cross the suppressed
(periodic time cross the suppressed 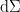 , this becomes
, this becomes
 is found from the bulk metric
is found from the bulk metric 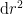 component
component  :
:
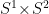 at
at 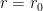 , with induced metric
, with induced metric
 . Since the covariant derivative generally involves non-trivial Christoffel symbols, I’m going to call this the brute-force method. Of course, these are well-known for the Schwarzschild metric, so in this case we may simply write down the relevant components:
. Since the covariant derivative generally involves non-trivial Christoffel symbols, I’m going to call this the brute-force method. Of course, these are well-known for the Schwarzschild metric, so in this case we may simply write down the relevant components:
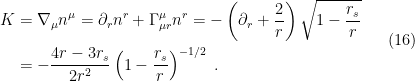
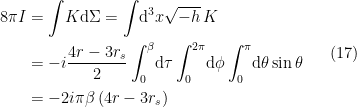
 , and using the fact that
, and using the fact that 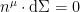 by definition, one obtains
by definition, one obtains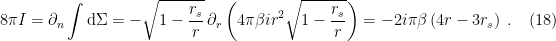
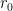 to infinity, where any deviation from Minkowski space is due to the
to infinity, where any deviation from Minkowski space is due to the  . We just calculated the first term; now let’s do the second.
. We just calculated the first term; now let’s do the second. , so
, so 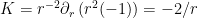 . Plugging these components into the action, and evaulating with the same limits as above, we have the flat-space contribution
. Plugging these components into the action, and evaulating with the same limits as above, we have the flat-space contribution 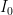 :
:
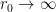 (keep in mind that
(keep in mind that 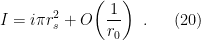
 and
and 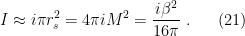
 and fields
and fields  ,
,  , and
, and![\displaystyle I[g,\phi]=I[g_0,\phi_0]+\ldots \ \ \ \ \ (22)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+I%5Bg%2C%5Cphi%5D%3DI%5Bg_0%2C%5Cphi_0%5D%2B%5Cldots+%5C+%5C+%5C+%5C+%5C+%2822%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle Z=e^{iI[g_0,\phi_0]}\implies \ln Z=iI[g_0,\phi_0]=-\frac{\beta^2}{16\pi} \ \ \ \ \ (23)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3De%5E%7BiI%5Bg_0%2C%5Cphi_0%5D%7D%5Cimplies+%5Cln+Z%3DiI%5Bg_0%2C%5Cphi_0%5D%3D-%5Cfrac%7B%5Cbeta%5E2%7D%7B16%5Cpi%7D+%5C+%5C+%5C+%5C+%5C+%2823%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is precisely a fourth the area of the horizon. But so far this is an expression for an action, not an entropy. To make the connection betwixt them, we’ll need some thermodynamics.
is precisely a fourth the area of the horizon. But so far this is an expression for an action, not an entropy. To make the connection betwixt them, we’ll need some thermodynamics. ) weighted by their probabilities
) weighted by their probabilities 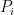 :
: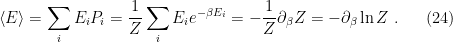
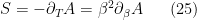
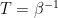 .
. 
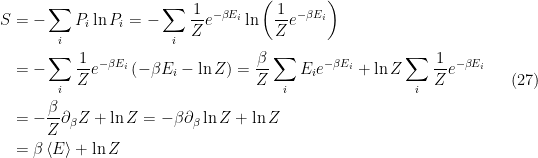
 . Now, from the definition of the Helmholtz free energy,
. Now, from the definition of the Helmholtz free energy,
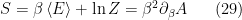



 ) featured crucially in the analysis. An extension of this method, where the fixed points form a conical deficit, can be shown to yield the same result. Indeed, the same feature lies at the heart of the recent proof of the Ryu-Takayanagi proposal by Lewkowycz and Maldacena, where the above geometrical computation of horizon entropy is extended to holography. Given the inextensibility (so far) of most of the other myriad ways of computing black hole entropy (e.g. Hawking pairs, string microstates, Noether charge) to arbitrary spacetime horizons, this further suggests a deep connection between entropy and geometry; one which we are only beginning to unravel.
) featured crucially in the analysis. An extension of this method, where the fixed points form a conical deficit, can be shown to yield the same result. Indeed, the same feature lies at the heart of the recent proof of the Ryu-Takayanagi proposal by Lewkowycz and Maldacena, where the above geometrical computation of horizon entropy is extended to holography. Given the inextensibility (so far) of most of the other myriad ways of computing black hole entropy (e.g. Hawking pairs, string microstates, Noether charge) to arbitrary spacetime horizons, this further suggests a deep connection between entropy and geometry; one which we are only beginning to unravel.