
Reference: John Preskill’s notes on Quantum Information and Computation.
In quantum mechanics, a state is a complete description of a physical system. Mathematically, it is given by a ray (an equivalence class of vectors) in Hilbert space, 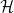
Hilbert spaces can be real or complex, finite- or infinite-dimensional; for definiteness we’ll assume complex, finite-dimensional Hilbert spaces here. The inner product is simply a map that associates an element of the field to pairs of elements in the vector space; in this case, 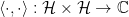


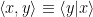
- Positivity:
, with equality iff
.
- Linearity:
.
- Skew symmetry:
.
The inner product induces a norm, 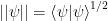
Note that we are free to choose the normalization 

Although states are the basic mathematical objects in this formalism, we never measure them. Rather, we measure observables, which are self-adjoint (a.k.a. Hermitian) operators that act as linear maps on states, 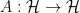


where 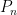
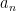

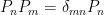

The numerical result of a measurement in quantum mechanics is given by the eigenvalue of the observable in question,

and the normalized quantum state with eigenvalue
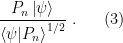
This is the point at which probability notoriously enters the picture; we’ll have more to say about this later. Note that, since the system is now in an eigenstate, immediately repeating the measurement will yield the same eigenvalue with probability 1.
The fact that the measurement process appears to induce such decisiveness on the part of the state leads to the notion of “wave function collapse”, which is a horribly misleading oversimplification to which we will return. Suffice to say that wave functions don’t collapse, but we’ve a bit more math to cover before the reality can be made precise.
So much for states and observables. What about dynamics? As in classical mechanics, the Hamiltonian 
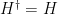



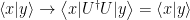

Given such an operator
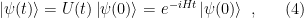
where in the second equality we’ve assumed 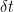
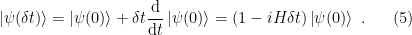
Comparing terms at linear order, we recognize the Schrödinger equation,

which describes the evolution of states in the Schrödinger picture, wherein states are time-dependent while operators (including observables) are constants. This is precisely the opposite of the Heisenberg picture, wherein operators carry the time-dependence while states are constant. The two pictures are related by a change of basis, analagous to the relation between active and passive transformations. A third picture, the interaction picture, is often later introduced as a rather ham-fisted compromise between these two; it forms a fantastically successful premise for perturbation theory, but it doesn’t actually exist (see Haag’s theorem).
Note that unitary evolution, as encapsulated in the Schrödinger equation, is entirely deterministic: specification of an initial state 
Another interesting observation is that according to the Schrödinger equation, quantum mechanical evolution is linear, in contrast to the non-linear evolution often encountered in classical theories. This is tied up with the issue of probability above: probability theory is fundamentally linear. But the connection isn’t quite so straightforward.
As an aside, the linearity of quantum mechanics is why quantum chaos is so subtle. Naïvely, quantum systems should be incapable of supporting chaos, since small perturbations to the initial state don’t wildly change the evolution in the case of linear dynamics. However, two states which are close in Hilbert space can nonetheless yield wildly different measurements. Quantum chaos has important implications in a number of areas, particularly holography and black holes; but that’s a subject for another post.
So, to summarize, we’ve seen that in quantum mechanics, states are vectors in Hilbert space, observables are Hermitian operators, symmetries are unitary operators, and measurements are orthogonal projections.
Now here’s the kicker: everything we’ve said so far applies only to a single, isolated system. This is an idealization that simply does not exist. Another way to phrase this is that the formulation above only holds if applied to the entire universe. Even ignoring the issue of how one would make a measurement in such a scenario, this is clearly not a realistic description. In fact, it’s frankly wrong: in general (that is, when considering subsystems) states are not rays, measurements are not orthogonal projections, and evolution is not unitary!
The simplest extension of the above is to consider a bipartite system, the Hilbert space for which is a tensor product of the Hilbert spaces of the constituents, 



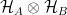

where, by unitarity, the eigenvalues satisfy 
Let us now consider an observable that acts only on subsystem 
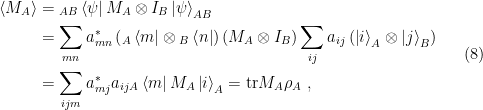
where we’ve introduced the reduced density matrix

In contrast to the trace, which is a scalar-valued function given by the sum of eigenvalues, the partial trace w.r.t. 
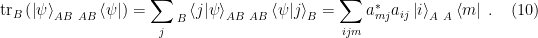
The elegant expression for the expectation value 
The reduced density matrix will play a central role in what follows, so it’s worth elaborating the properties that follow from the definition above (in particular the explicit form (10)):
- Hermiticity:
.
- Non-negativity (of its eigenvalues):
,
.
- Unit norm:
(since
is normalized).
As mentioned above, pure states are rays in Hilbert space, but mixed states are not. However, both are described by a reduced density matrix, which therefore provides a suitably general definition of quantum states. In the case of a pure state, 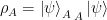




where the eigenvalues satisfy 


As alluded above, in a coherent superposition of states, the relative phase is physically meaningful (i.e., observable). This is merely a consequence of the linearity of the Schrödinger equation: any linear combination of solutions is also a solution. In contrast, the mixed state 
We should note that probability again enters this updated picture when we consider that the expectation value of any observable 


which leads to the interpretation of 

As a concrete example, consider the spin state

which is a (coherent) superposition of spins along the 


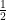

In contrast, the ensemble in which each of these states occurs with this probability is

But since the identity is invariant under a unitary change of basis (

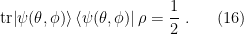
In other words, we obtain spin up or down with equal probability, regardless of what we do. This is a reflection of the fact that the relative phases in a superposition are observable, but those in an ensemble are not. A mixed state can thus be thought of as an ensemble of pure states in many different ways, all of which are experimentally indistinguishable. (As an aside, further clarity on these relationships can be gained by studying the Bloch sphere, which I shall not digress upon here).
A bipartite pure state can be expressed in a standard form, which is often very useful. One begins by observing that an arbitrary state 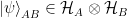

where 

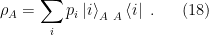
However, by definition (9), this is also equivalent to tracing out system

And therefore, it must be the case that

i.e., the new basis 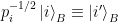
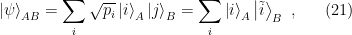
which is the Schmidt decomposition of the bipartite pure state 
Observe that by tracing over one of the Hilbert spaces in (21), we find that both 

though since the dimensions of 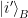

The Schmidt decomposition is useful for characterizing whether pure states are separable or entangled (for mixed states, the situation is more subtle). In particular, the bipartite pure state above, 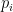




Entanglement is quantified by the von Neumann entropy. Entanglement entropy is a tremendously rich topic in itself, to say nothing of its connections to other areas of physics, and thus we defer further discussion elsewhere.
To summarize, it is only in the case for idealized, isolated systems (i.e., the entire universe) that quantum states may be described by rays in Hilbert space. In reality, since we always deal with subsystems, states are given by (reduced) density matrices defined by tracing out the complement of the Hilbert space under consideration. (The Hilbert spaces themselves are associated with spatial regions, and thus what we mean is that we trace over all degrees of freedom localized in the complement of our subregion. As mentioned elsewhere however, this is generally still too naïve).
It remains to justify our earlier claim that generic measurements are not orthogonal projections, and evolution non-unitary. In the course of doing so, we shall resolve Preskill’s “disconcerting dualism” between determinism and probability, and explain why the notion of wave-function collapse is an illusion. But this will require us to develop slightly beyond the basic mathematical machinery above, and as such we partition the discussion into Part 2.
