
You should call it entropy, for two reasons. In the first place your uncertainty function has been used in statistical mechanics under that name, so it already has a name. In the second place, and more important, no one really knows what entropy really is, so in a debate you will always have the advantage.
— John von Neumann to Claude Shannon, as to what the latter should call his uncertainty function.
I recently read the classic article [1] by Jaynes, which elucidates the relationship between subjective and objective notions of entropy—that is, between the information-theoretic notion of entropy as a reflection of our ignorance, and the thermodynamic notion of entropy as a measure of the statistical microstates of a system. These two notions are formally identical, and can be written

where 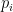
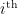
(As an aside, readers without a theoretical physics background may be confused by the fact that the thermodynamic entropy is typically written with a prefactor 

As a prelude, let us first explain what entropy has to do with subjective uncertainty. That is, why is (1) a sensible/meaningful/well-defined measure of the information we have available? Enter Claude Shannon, whose landmark paper [2] proved, perhaps surprisingly, that (1) is in fact the unique, unambiguous quantification of the “amount of uncertainty” represented by a discrete probability distribution! Jaynes offers a more intuitive proof in his appendix A [1], which proceeds as follows. Suppose we have a variable 



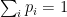


- If all
(since probabilities sum to 1), and
is a monotonically increasing function of
.
- If we decompose an event into sub-events, then the original value of
The first requirement simply ensures that  On the left, we have three probabilities
On the left, we have three probabilities 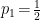


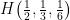


where the 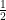
To generalize this, it is convenient to represent the probabilities as rational fractions,

(The fact that 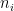

To see this, consider the example given by Jaynes, in which we take 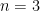
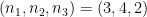



Thus we see that at the highest level, the uncertainty — had we thrown away the fine-grained information in each cluster — is 
The final trick is to consider the case where all 

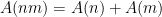




where we’ve used the fact that probabilities sum to 1 to write 
Thus, on the subjective side, we see that entropy (1) is the least biased representation of our state of knowledge. And this fact underlies a form of statistical inference known as maximum entropy or max-ent estimation. The basic problem is how to make inferences — that is, assign probabilities — based on incomplete information. Obviously, we want our decisions to be as unbiased as possible, and therefore we must use the probability distribution which has the maximum entropy subject to known constraints—in other words, the distribution which is maximally non-committal with respect to missing information. To use any other distribution is tantamount to imposing additional, arbitrary constraints, thereby biasing our decisions. In this sense, max-ent estimation may be regarded as a mathematization of rationality, insofar as it represents the absolute best (i.e., most rational) guess we could possibly make given the information at hand.
To make contact with the objective notion of entropy in thermodynamics, let’s examine the max-ent procedure in more detail. Suppose, as in the examples above, that we have a variable 

Now the question is, based on this information, what is the expectation value of some other function 


and (6) collectively provide only 2 constraints. Max-ent is the additional principle which not only makes this problem tractable, but ensures that our distribution will be as broad as possible (i.e., that we don’t concentrate our probability mass any more narrowly than the given information allows).
As the name suggest, the idea is to maximize the entropy (1) subject to the constraints (6) and (7). We therefore introduce the Lagrange multipliers 

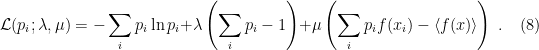
Imposing 

We can then redefine

To solve for the Lagrange multipliers, we simply substitute this into the contraints (7) and (6), respectively:

Now observe that the sum in these expressions is none other than the partition function for the canonical ensemble at inverse temperature

We therefore have

i.e., 

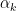
This essentially completes the connection with the thermodynamic concept of entropy. If only the average energy of the system is fixed, then the microstates will be described by the Boltzmann distribution (10). This is an objective fact about the system, reflecting the lack of any additional physical constraints. Thus the subjective and objective notions of entropy both reference the same underlying concept, namely, that the correct probability mass function is dispersed as widely as possible given the constraints on the system (or one’s knowledge thereof). Indeed, a priori, one may go so far as to define the thermodynamic entropy as the quantity which is maximized at thermal equilibrium (cf. the fundamental assumption of statistical mechanics).
Having said all that, one must exercise greater care in extending this analogy to continuous variables, and I’m unsure how much of this intuition survives in the quantum mechanical case (though Jaynes has a follow-up paper [3] in which he extends these ideas to density matrices). And that’s not to mention quantum field theory, where the von Neumann entropy is notoriously divergent. Nonetheless, I suspect a similar unity is at play. The connection between statistical mechanics and Euclidean field theory is certainly well-known, though I still find thermal Green functions rather remarkable. Relative entropy is another example, insofar as it provides a well-defined link between von Neumann entropy and the modular hamiltonian, and the latter appears to encode certain thermodynamic properties of the vacuum state. This is particularly interesting in the context of holography (as an admittedly biased reference, see [4]), and is a topic to which I hope to return soon.
References
- E. T. Jaynes, “Information Theory and Statistical Mechanics,” The Physical Review 106 no. 4, (1957).
- C. E. Shannon, “A Mathematical Theory of Communication,” The Bell System Technical Journal 27, (1948).
- E. T. Jaynes, “Information Theory and Statistical Mechanics II,” The Physical Review 108 no. 2, (1957).
- R. Jefferson, “Comments on black hole interiors and modular inclusions,” arXiv:1811.08900.
