
As a theoretical physicist making their first foray into machine learning, one is immediately captivated by the fascinating parallel between deep learning and the renormalization group. In essence, both are concerned with the extraction of relevant features via a process of coarse-graining, and preliminary research suggests that this analogy can be made rather precise. This is particularly interesting in the context of attempts to develop a theoretical framework for deep learning; insofar as the renormalization group is well-understood in theoretical physics, the strength of this mathematical analogy may pave the way towards a general theory of deep learning. I hope to return to this tantalizing correspondence soon; but first, we need to understand restricted Boltzmann machines (RBMs).
As the name suggests, an RBM is a special case of the Boltzmann machines we’ve covered before. The latter are useful for understanding the basic idea behind energy-based generative models, but it turns out that all-to-all connectivity leads to some practical problems when training such networks. In contrast, an RBM restricts certain connections (hence the name), which makes training them much more efficient. Specifically, the neurons in an RBM are divided into one of two layers, consisting of visible and hidden units, respectively, with intralayer connections prohibited. Visible units essentially correspond to outputs: these are the variables to which the observer has access. In contrast, hidden units interact only through their connection with the visible layer, but in such a way as to encode complex, higher-order interactions between the visible degrees of freedom. This ability to encode such latent variables is what makes RBMs so powerful, and underlies the close connection with the renormalization group (RG).
Latent or hidden variables correspond to the degrees of freedom one integrates out (“marginalizes over”, in machine learning (ML) parlance) when performing RG. When properly performed, this procedure ensures that the relevant physics is encoded in correlations between the remaining (visible) degrees of freedom, while allowing one to work with a much simpler model, analogous to an effective field theory. To understand how this works in detail, suppose we wish to apply Wilsonian RG to the Ising model (a pedagogical review by Dimitri Vvedensky can be found here). To do this, we must first transform the (discrete) Ising model into a (continuous) field theory, so that momentum-space RG techniques can be applied. This is achieved via a trick known as the Hubbard-Stratonovich transformation, which neatly illustrates how correlations between visible/relevant variables can be encoded via hidden/irrelevant degrees of freedom.
The key to the Hubbard-Stratonovich transformation is the observation that for any value of 

Since we’ll be working with a discrete lattice of spins, it’s helpful to write this in matrix notation:
![\displaystyle e^{\frac{1}{2}\sum_{ij}K_{ij}s_is_j} =\left[\frac{\mathrm{det}K}{(2\pi)^N}\right]^{1/2}\prod_{k=1}^N\int\!\mathrm{d}\phi_k\exp\left(-\frac{1}{2}\sum_{ij}K_{ij}\phi_i\phi_j+\sum_{ij}K_{ij}s_i\phi_j\right)~, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+e%5E%7B%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bij%7DK_%7Bij%7Ds_is_j%7D+%3D%5Cleft%5B%5Cfrac%7B%5Cmathrm%7Bdet%7DK%7D%7B%282%5Cpi%29%5EN%7D%5Cright%5D%5E%7B1%2F2%7D%5Cprod_%7Bk%3D1%7D%5EN%5Cint%5C%21%5Cmathrm%7Bd%7D%5Cphi_k%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bij%7DK_%7Bij%7D%5Cphi_i%5Cphi_j%2B%5Csum_%7Bij%7DK_%7Bij%7Ds_i%5Cphi_j%5Cright%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 

with spins 

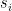


which is typically solved by the transfer-matrix method. To recast this as a field theory, we observe that the sum over the second term in (2) may be written
![\displaystyle \begin{aligned} {}&\sum_{s_i=\pm1}\exp\left(\sum\nolimits_{ij}K_{ij}s_i\phi_j\right) =\sum_{s_i=\pm1}\prod_i\exp\left(\sum\nolimits_{j}K_{ij}s_i\phi_j\right)\\ &=\prod_i\left[\exp\left(\sum\nolimits_{j}K_{ij}\phi_j\right)+\exp\left(-\sum\nolimits_{j}K_{ij}\phi_j\right)\right]\\ &=2^N\prod_i\cosh\left(\sum\nolimits_{j}K_{ij}\phi_j\right) =2^N\exp\left[\sum\nolimits_i\ln\cosh\left(\sum\nolimits_jK_{ij}\phi_j\right)\right]~, \end{aligned} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%7B%7D%26%5Csum_%7Bs_i%3D%5Cpm1%7D%5Cexp%5Cleft%28%5Csum%5Cnolimits_%7Bij%7DK_%7Bij%7Ds_i%5Cphi_j%5Cright%29+%3D%5Csum_%7Bs_i%3D%5Cpm1%7D%5Cprod_i%5Cexp%5Cleft%28%5Csum%5Cnolimits_%7Bj%7DK_%7Bij%7Ds_i%5Cphi_j%5Cright%29%5C%5C+%26%3D%5Cprod_i%5Cleft%5B%5Cexp%5Cleft%28%5Csum%5Cnolimits_%7Bj%7DK_%7Bij%7D%5Cphi_j%5Cright%29%2B%5Cexp%5Cleft%28-%5Csum%5Cnolimits_%7Bj%7DK_%7Bij%7D%5Cphi_j%5Cright%29%5Cright%5D%5C%5C+%26%3D2%5EN%5Cprod_i%5Ccosh%5Cleft%28%5Csum%5Cnolimits_%7Bj%7DK_%7Bij%7D%5Cphi_j%5Cright%29+%3D2%5EN%5Cexp%5Cleft%5B%5Csum%5Cnolimits_i%5Cln%5Ccosh%5Cleft%28%5Csum%5Cnolimits_jK_%7Bij%7D%5Cphi_j%5Cright%29%5Cright%5D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the spin degrees of freedom have been summed over, and we’ve re-exponentiated the result in preparation for its insertion below. This enables us to express the partition function entirely in terms of the latent variable 
![\displaystyle Z=\left[\frac{\mathrm{det}K}{(\pi/2)^N}\right]^{1/2}\prod_{k=1}^N\int\!\mathrm{d}\phi_k\exp\left(-\frac{1}{2}\sum_{ij}K_{ij}\phi_i\phi_j+\sum\nolimits_i\ln\cosh\sum\nolimits_jK_{ij}\phi_j\right)~, \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3D%5Cleft%5B%5Cfrac%7B%5Cmathrm%7Bdet%7DK%7D%7B%28%5Cpi%2F2%29%5EN%7D%5Cright%5D%5E%7B1%2F2%7D%5Cprod_%7Bk%3D1%7D%5EN%5Cint%5C%21%5Cmathrm%7Bd%7D%5Cphi_k%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bij%7DK_%7Bij%7D%5Cphi_i%5Cphi_j%2B%5Csum%5Cnolimits_i%5Cln%5Ccosh%5Csum%5Cnolimits_jK_%7Bij%7D%5Cphi_j%5Cright%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
where, since the first term in (2) is independent of 
So what does this have to do with (restricted) Boltzmann machines? This is neatly explained in the amazing review by Pankaj Mehta et al., A high-bias, low-variance introduction to Machine Learning for physicists, which receives my highest recommendations. The idea is that by including latent variables in generative models, one can encode complex interactions between visible variables without sacrificing trainability (because the correlations between visible degrees of freedom are mediated via the UV degrees of freedom over which one marginalizes, rather than implemented directly as intralayer couplings). The following exposition draws heavily from section XVI of Mehta et al., and the reader is encouraged to turn there for more details.
Consider a Boltzmann distribution with energy

where 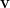
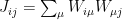
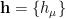


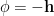

Of course, this is simply a special case of the following multidimensional Gaussian integral: recall that if 


Thus, reverting to matrix notation, and absorbing the normalization into the partition function 

where on the second line, we’ve introduced the joint energy function

The salient feature of this new hamiltonian is that it contains no interactions between the visible neurons: the original, intralayer coupling 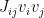

A general RBM is described by the hamiltonian

where the functions 

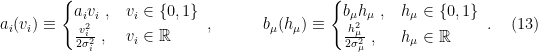
The upper choice, with binary neurons, is referred to as a Bernoulli layer, while the lower choice, with continuous outputs, is called a Gaussian layer. Note that choosing the visible layer to be Bernoulli and the hidden Gaussian reduces to the example considered above, with standard deviations 

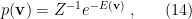
where the marginalized energy of visible neurons is given by

Now, to understand how higher-order correlations are encoded in 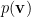

The associated cumulant generating function is
![\displaystyle K_\mu(t)=\ln E_q\left[e^{th_\mu}\right] =\ln\int\!\mathrm{d} h_\mu\,q_\mu(h_\mu)e^{th_\mu} =\sum_n\kappa_\mu^{(n)}\frac{t^n}{n!}~, \ \ \ \ \ (17)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+K_%5Cmu%28t%29%3D%5Cln+E_q%5Cleft%5Be%5E%7Bth_%5Cmu%7D%5Cright%5D+%3D%5Cln%5Cint%5C%21%5Cmathrm%7Bd%7D+h_%5Cmu%5C%2Cq_%5Cmu%28h_%5Cmu%29e%5E%7Bth_%5Cmu%7D+%3D%5Csum_n%5Ckappa_%5Cmu%5E%7B%28n%29%7D%5Cfrac%7Bt%5En%7D%7Bn%21%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2817%29&bg=ffffff&fg=000000&s=0&c=20201002)
where ![{E_q[\cdot]}](https://s0.wp.com/latex.php?latex=%7BE_q%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
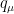



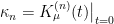

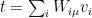

In other words, after marginalizing over the latent variables, we obtain an effective hamiltonian with arbitrarily high-order interactions between the visible neurons, with the effective couplings weighted by the associated cumulant. As emphasized by Mehta et al., it is the ability to encode such complex interactions with only the simplest couplings between visible and hidden neurons that underlies the incredible power of RBMs. See my later post on the relationship between deep learning and RG for a much more in-depth look at this.
As final comment, there’s an interesting connection between cumulants and statistical physics, which stems from the fact that for a thermal system with partition function 
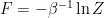

Hi Ro, thanks a lot for this nice review. It seems the link to Vvedensky‘s review is not working. Do you have the file stored anywhere? That would be very useful. Thanks!
LikeLike
Thanks Francesco, I’m glad you liked it! And thanks for pointing out the broken link; sadly I cannot find the notes online anymore, but Dimitri was kind enough to send me the pdfs, which I’ll be happy to email you.
LikeLike
Hi Ro. Thank you so much for your wonderful explanation.
LikeLike