I alluded previously that information geometry had many interesting applications, among them machine learning and computational neuroscience more generally. A classic example is the original paper by Amari, Kurata, and Nagaoka, Information Geometry of Boltzmann Machines [1]. This paper has a couple hundred citations, so the following is by no means a review of the current state of the art; however, it does provide a concrete setting in which to apply the theoretical framework introduced in my three-part information geometry sequence, and is as good a place to start as any.
Boltzmann machines belong to the class of so-called “energy-based” models of neural networks, for reasons which will be elucidated below, which makes them particularly intuitive from a physics perspective (see, e.g., the spin-glass analogy of neural networks). Additionally, at least in the absence of hidden layers, they have a number of nice mathematical properties that make them ideal toy models for the geometric approach. Let us briefly introduce these models, following the notation in [1]. A Boltzmann machine is network of  stochastic neurons with symmetric connection weights
stochastic neurons with symmetric connection weights  between the
between the 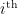 and
and  neurons (with
neurons (with  ). A neuron is a binary variable which has a value of either 1 (excited) or 0 (quiescent). As the network is evolved in time, the state of the neuron is updated according to the potential
). A neuron is a binary variable which has a value of either 1 (excited) or 0 (quiescent). As the network is evolved in time, the state of the neuron is updated according to the potential

where 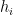 is the threshold for the neuron (i.e., a free parameter that determines that neuron’s sensitivity to firing), and in the second equality we have absorbed this by defining the zeroth neuron with
is the threshold for the neuron (i.e., a free parameter that determines that neuron’s sensitivity to firing), and in the second equality we have absorbed this by defining the zeroth neuron with  and
and  . The state of the neuron is updated to 1 with probability
. The state of the neuron is updated to 1 with probability  , and 0 with probability
, and 0 with probability 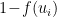 , where
, where

We can now see the reason for the name as follows: the network’s state is described by the vector 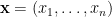 , and hence the transition between states forms a Markov chain with
, and hence the transition between states forms a Markov chain with  sites. In particular, if there are no disconnected nodes, then it forms an ergodic Markov chain with a unique stationary distribution
sites. In particular, if there are no disconnected nodes, then it forms an ergodic Markov chain with a unique stationary distribution

i.e., the probability of finding the network in a given state will asymptotically approach the Boltzmann distribution. In this expression, the normalization is given by the partition function for the canonical ensemble,

where we sum over all possible microstates. We then recognize  as the energy of the state
as the energy of the state 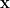 , which is given by
, which is given by

where the second equality follows from the symmetry of the connection matrix. In other words, (5) is the hamiltonian for a system of nearest-neighbor interactions with coupling 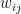 .
.
The relationship between the Boltzmann distribution and the update rule (2) is most easily seen in reverse: consider two states which differ only by a single neuron. Their energy difference is  , where
, where  denotes the state in which the neuron is excited, etc. By (3), we have
denotes the state in which the neuron is excited, etc. By (3), we have
![\displaystyle \begin{aligned} \Delta E&=-\ln p(x_i\!=\!1)+\ln p(x_i\!=\!0) =-\ln p(x_i\!=\!1)+\ln [1-p(x_i\!=\!1)]\\ &=\ln\left[\frac{1}{p(x_i\!=\!1)}-1\right] \;\implies\; p(x_i\!=\!1)=\frac{1}{1+e^{\Delta E}}~, \end{aligned} \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5CDelta+E%26%3D-%5Cln+p%28x_i%5C%21%3D%5C%211%29%2B%5Cln+p%28x_i%5C%21%3D%5C%210%29+%3D-%5Cln+p%28x_i%5C%21%3D%5C%211%29%2B%5Cln+%5B1-p%28x_i%5C%21%3D%5C%211%29%5D%5C%5C+%26%3D%5Cln%5Cleft%5B%5Cfrac%7B1%7D%7Bp%28x_i%5C%21%3D%5C%211%29%7D-1%5Cright%5D+%5C%3B%5Cimplies%5C%3B+p%28x_i%5C%21%3D%5C%211%29%3D%5Cfrac%7B1%7D%7B1%2Be%5E%7B%5CDelta+E%7D%7D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the  terms have canceled, and we have used the fact that probabilities sum to 1. Now observe that since we only changed a single neuron,
terms have canceled, and we have used the fact that probabilities sum to 1. Now observe that since we only changed a single neuron, 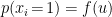 , whereupon (2) mandates the identification
, whereupon (2) mandates the identification 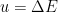 . Thus, thermodynamically,
. Thus, thermodynamically,  is a thermal spectrum, and
is a thermal spectrum, and  is the momentum mode associated with the excitation
is the momentum mode associated with the excitation 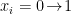 (said differently, is the energy gap associated with the transition). Given the hamiltonian (5) — that is, the fact that the network is stochastic and fully connected — the form of the probability update rule (2) therefore encodes the fact that the system is in thermal equilibrium: the set of all possible states satisfies a Boltzmann distribution (with temperature
(said differently, is the energy gap associated with the transition). Given the hamiltonian (5) — that is, the fact that the network is stochastic and fully connected — the form of the probability update rule (2) therefore encodes the fact that the system is in thermal equilibrium: the set of all possible states satisfies a Boltzmann distribution (with temperature 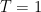 in our units).
in our units).
Now, (machine) “learning”, in this context, consists of adjusting the distribution 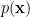 to match, as closely as possible, a given input or environmental distribution
to match, as closely as possible, a given input or environmental distribution  . This is achieved by modifying the connection weights (which in our compact notation includes the threshold values ) according to a specified learning rule. Accordingly, we shall impose that the average adjustment to is given by
. This is achieved by modifying the connection weights (which in our compact notation includes the threshold values ) according to a specified learning rule. Accordingly, we shall impose that the average adjustment to is given by

where 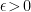 is a small constant, and the expectation values with respect to the distributions , are
is a small constant, and the expectation values with respect to the distributions , are
![\displaystyle q_{ij}=E_q[x_ix_j]=\sum_xq(\mathbf{x})x_ix_j~, \qquad\quad p_{ij}=E_p[x_ix_j]=\sum_xp(\mathbf{x})x_ix_j~, \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%7Bij%7D%3DE_q%5Bx_ix_j%5D%3D%5Csum_xq%28%5Cmathbf%7Bx%7D%29x_ix_j%7E%2C+%5Cqquad%5Cquad+p_%7Bij%7D%3DE_p%5Bx_ix_j%5D%3D%5Csum_xp%28%5Cmathbf%7Bx%7D%29x_ix_j%7E%2C+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
cf. eq. (9) in part 1 of my information geometry sequence. Intuitively, the rule (7) simply says that we adjust the weights according to the difference between our reference and target distributions (more carefully: we adjust the connection strength between two neurons in proportion to the difference between the expectation values of both neurons being excited under said distributions). The reason for this particular rule — aside from its intuitive appeal — is that it realizes the (stochastic) gradient descent algorithm for optimizing the Kullback-Leibler divergence between and ,

i.e., (7) may be written
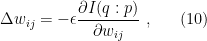
where the derivative is with respect to the weights of the initial distribution 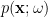 . We’ll see this explicitly below, after introducing some facilitating machinery, whereupon the fact that this realizes gradient descent on the divergence (9) will also be seen to emerge naturally from the geometric framework; the original proof, as far as I’m aware, was given in [2].
. We’ll see this explicitly below, after introducing some facilitating machinery, whereupon the fact that this realizes gradient descent on the divergence (9) will also be seen to emerge naturally from the geometric framework; the original proof, as far as I’m aware, was given in [2].
Incidentally, another interesting feature of the learning rule (7) is that it’s (ultra)local. Thus, in contrast to methods like backpropagation which require global information about the network, it may represent a more biologically plausible model insofar as it relies only on local synaptic data (in addition to being computationally simpler).
In order to apply the methods of information geometry to the Boltzmann machines introduced above, let us first review the relevant aspects in this context. Let  be the set of all probability distributions over the state space
be the set of all probability distributions over the state space  . The latter consists of states, but the constraint
. The latter consists of states, but the constraint

implies that we have only 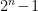 degrees of freedom; thus we may treat
degrees of freedom; thus we may treat  as a
as a 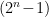 -dimensional Euclidean manifold. (Since we’re working with finite-dimensional distributions, we mean that is a manifold in the sense that it is topologically locally equivalent to Euclidean space; additionally, the constraint
-dimensional Euclidean manifold. (Since we’re working with finite-dimensional distributions, we mean that is a manifold in the sense that it is topologically locally equivalent to Euclidean space; additionally, the constraint  implies that we exclude the boundary
implies that we exclude the boundary 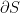 . So technically, is an open simplex with this dimensionality, but the distinction will not be relevant for our purposes). As will become apparent below, forms a dually flat space, which underlies many of the nice properties alluded above.
. So technically, is an open simplex with this dimensionality, but the distinction will not be relevant for our purposes). As will become apparent below, forms a dually flat space, which underlies many of the nice properties alluded above.
By a suitable choice of coordinates, we can represent as an exponential family,
![\displaystyle q(\mathbf{x};\theta)=\exp\!\left[\theta^IX_I-\psi(\theta)\right]~, \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q%28%5Cmathbf%7Bx%7D%3B%5Ctheta%29%3D%5Cexp%5C%21%5Cleft%5B%5Ctheta%5EIX_I-%5Cpsi%28%5Ctheta%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=0&c=20201002)
cf. eq. (26) in part 1. Here,  is a -dimensional vector of canonical parameters,
is a -dimensional vector of canonical parameters, 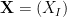 with
with  , and the index
, and the index  runs over all combinations of subsets
runs over all combinations of subsets  for
for  . The condition
. The condition 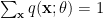 then identifies the potential
then identifies the potential  as the cumulant generating function,
as the cumulant generating function,
![\displaystyle \psi(\theta)=\ln\sum_\mathbf{x}\exp\!\left[\theta^IX_I(\mathbf{x})\right]~. \ \ \ \ \ (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpsi%28%5Ctheta%29%3D%5Cln%5Csum_%5Cmathbf%7Bx%7D%5Cexp%5C%21%5Cleft%5B%5Ctheta%5EIX_I%28%5Cmathbf%7Bx%7D%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2813%29&bg=ffffff&fg=000000&s=0&c=20201002)
Now recall from part 2 that the dual coordinate  is defined via the expectation with respect to
is defined via the expectation with respect to 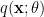 ,
,
![\displaystyle \eta_I\equiv E_\theta[X_I]=\mathrm{prob}\left\{x_{i_1}=\ldots=x_{i_m}=1\,|\,I=(i_1,\ldots,i_m)\right\}~, \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ceta_I%5Cequiv+E_%5Ctheta%5BX_I%5D%3D%5Cmathrm%7Bprob%7D%5Cleft%5C%7Bx_%7Bi_1%7D%3D%5Cldots%3Dx_%7Bi_m%7D%3D1%5C%2C%7C%5C%2CI%3D%28i_1%2C%5Cldots%2Ci_m%29%5Cright%5C%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the second equality follows from the fact that the only non-zero term in the sum is that for which all neurons are excited, hence we just have the probability  . As explained in part 3, this identification is tantamount to the statement that the coordinates
. As explained in part 3, this identification is tantamount to the statement that the coordinates  and
and  are related through the dual potential
are related through the dual potential 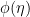 , which is defined via the Legendre transform. In the present case, we have via (13),
, which is defined via the Legendre transform. In the present case, we have via (13),

where  is the entropy of state. Note that we can also express this as
is the entropy of state. Note that we can also express this as

which provides a useful relationship between the (dual) coordinates and potentials that will come in handy later.
To see that is dually flat, recall that the canonical and dual parameters,  and
and  , respectively induce 1-affine and
, respectively induce 1-affine and 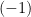 -affine coordinate systems, with respect to which is
-affine coordinate systems, with respect to which is 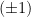 -flat; cf. eq. (30) and (34) in part 1. Thus admits a unique Riemannian metric — the Fisher information metric — which can be expressed in the natural basis of coordinates as
-flat; cf. eq. (30) and (34) in part 1. Thus admits a unique Riemannian metric — the Fisher information metric — which can be expressed in the natural basis of coordinates as
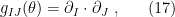
i.e., for any two vectors  ,
,
![\displaystyle g_{IJ}(\theta)=\langle X,Y\rangle_\theta=E_\theta[X\ell_\theta(\mathbf{x}) Y\ell_\theta(\mathbf{x})] \ \ \ \ \ (18)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7BIJ%7D%28%5Ctheta%29%3D%5Clangle+X%2CY%5Crangle_%5Ctheta%3DE_%5Ctheta%5BX%5Cell_%5Ctheta%28%5Cmathbf%7Bx%7D%29+Y%5Cell_%5Ctheta%28%5Cmathbf%7Bx%7D%29%5D+%5C+%5C+%5C+%5C+%5C+%2818%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  ; cf. eqs. (12) and (14) in part 1. Taking and
; cf. eqs. (12) and (14) in part 1. Taking and  to be basis vectors, we recover the general definition
to be basis vectors, we recover the general definition
![\displaystyle g_{IJ}(\theta)=E_\theta[\partial_I\ell_\theta(\mathbf{x}) \partial_J\ell_\theta(\mathbf{x})]~. \ \ \ \ \ (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7BIJ%7D%28%5Ctheta%29%3DE_%5Ctheta%5B%5Cpartial_I%5Cell_%5Ctheta%28%5Cmathbf%7Bx%7D%29+%5Cpartial_J%5Cell_%5Ctheta%28%5Cmathbf%7Bx%7D%29%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2819%29&bg=ffffff&fg=000000&s=0&c=20201002)
This expression is general insofar as it holds for arbitrary coordinate systems (cf. the inner product on random variables). Since is  -flat however, it reduces to
-flat however, it reduces to

which one can verify explicitly via (13) (it is convenient to start with the form eq. (11) in part 1). Thus, dual flatness has the advantage that the metric can be directly obtained from the potential . In accordance with our discussion in part 2, we also have the inverse metric

which implies that 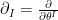 and
and 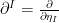 are mutually dual basis vectors at every point in , i.e.,
are mutually dual basis vectors at every point in , i.e., 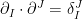 .
.
Of course, the manifold is generically curved with respect to the Riemannian metric  above. But the special feature of dually flat spaces is that we can introduce dual
above. But the special feature of dually flat spaces is that we can introduce dual 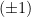 -connections with respect to which appears flat. Recall that any dual structure
-connections with respect to which appears flat. Recall that any dual structure 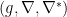 is naturally induced from a divergence. Specifically, let us take the canonical divergence
is naturally induced from a divergence. Specifically, let us take the canonical divergence

where by the argument of the potential, we mean the associated coordinate; e.g.,  , where
, where 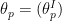 is the canonical coordinate of
is the canonical coordinate of 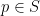 . One can readily see that this induces the metric above, in the sense that
. One can readily see that this induces the metric above, in the sense that

where the last equality follows by (20). Additionally, we saw in part 2 that the Kullback-Leibler divergence corresponds to the  -divergence for
-divergence for 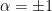 , and that the latter is in turn a special case of the more general
, and that the latter is in turn a special case of the more general  -divergence. But for the dual structure
-divergence. But for the dual structure  , this is none other than the canonical divergence! That is, given the potentials and dual coordinate systems and above, (22) leads to (9), i.e.,
, this is none other than the canonical divergence! That is, given the potentials and dual coordinate systems and above, (22) leads to (9), i.e.,

(note the change in ordering).
We may now regard the space of Boltzmann machines  as a submanifold of . One can see this by taking the log of the distribution (3),
as a submanifold of . One can see this by taking the log of the distribution (3),

where the potential  accounts for the normalization; note that this is constant with respect to . In terms of the canonical coordinates above, this corresponds to
accounts for the normalization; note that this is constant with respect to . In terms of the canonical coordinates above, this corresponds to 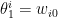 ,
,  , and
, and  for all
for all 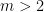 . The last of these constitutes a system of -linear constraints, which implies that is in particular an -linear submanifold of , and therefore inherits the dually linear properties of itself. Furthermore, since is an exponential family, we shall henceforth denote its canonical coordinates by
. The last of these constitutes a system of -linear constraints, which implies that is in particular an -linear submanifold of , and therefore inherits the dually linear properties of itself. Furthermore, since is an exponential family, we shall henceforth denote its canonical coordinates by 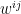 (with upper indices) for consistency with the conventions above. We then define the dual coordinates (cf. eq. (14))
(with upper indices) for consistency with the conventions above. We then define the dual coordinates (cf. eq. (14))
![\displaystyle \eta_{ij}=E_w[x_ix_j]=p_{ij}=\mathrm{prob}\{x_i=x_j=1\}~, \qquad\quad i<j~,\quad i=0,\ldots,n~, \ \ \ \ \ (26)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ceta_%7Bij%7D%3DE_w%5Bx_ix_j%5D%3Dp_%7Bij%7D%3D%5Cmathrm%7Bprob%7D%5C%7Bx_i%3Dx_j%3D1%5C%7D%7E%2C+%5Cqquad%5Cquad+i%3Cj%7E%2C%5Cquad+i%3D0%2C%5Cldots%2Cn%7E%2C+%5C+%5C+%5C+%5C+%5C+%2826%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the penultimate equality follows from (8). Note that unlike the canonical coordinates above, the remaining parts 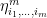 are generally nonlinear functions of
are generally nonlinear functions of  for points in . (This implies that is not an
for points in . (This implies that is not an  -linear submanifold of , but since it’s -linear, we can find some other coordinates to reveal the dual -linear structure that must possess). The (invariant!) divergence between two Boltzmann machines
-linear submanifold of , but since it’s -linear, we can find some other coordinates to reveal the dual -linear structure that must possess). The (invariant!) divergence between two Boltzmann machines  and
and  is then given by
is then given by
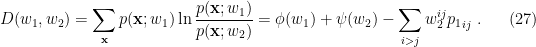
(Note that this differs from eq. (34) in [1]; I believe the authors have mistakenly swapped the distribution labels  . Explicitly, (15) allows us to identify the first term as
. Explicitly, (15) allows us to identify the first term as
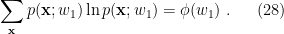
Meanwhile, the second term is easily found to be

where we used the fact that ![{p_{ij}=\eta_{ij}=E_w[x_ix_j]}](https://s0.wp.com/latex.php?latex=%7Bp_%7Bij%7D%3D%5Ceta_%7Bij%7D%3DE_w%5Bx_ix_j%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Subtracting this from the entropy term above yields (27) as written). From (20) and (16), the induced the metric is simply given by
. Subtracting this from the entropy term above yields (27) as written). From (20) and (16), the induced the metric is simply given by

This, of course, has a statistical interpretation as the Fisher information matrix; it may be alternatively expressed as [1]
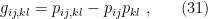
where the first term is the probability that all four neurons are excited,

As mentioned above, the learning task is for the Boltzmann machine to realize an environmental or target probability distribution as closely as possible, according to the divergence (27). We now wish to connect this notion of minimum divergence to the intuitive differential geometric picture of as a submanifold of , whereby one expects that the best approximation is given by the point 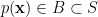 that minimizes the geodesic distance between and . To do so, consider three points,
that minimizes the geodesic distance between and . To do so, consider three points, 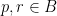 and
and  , where
, where  is the current state of the Boltzmann machine, and
is the current state of the Boltzmann machine, and  is the best possible approximation of the environmental distribution
is the best possible approximation of the environmental distribution  (which generically lies beyond ). Clearly, the point is given by
(which generically lies beyond ). Clearly, the point is given by

where  is the divergence between the distributions and defined above. The right-hand side of (33) describes the geodesic or -projection of onto , so named because the tangent vector of the geodesic is orthogonal to
is the divergence between the distributions and defined above. The right-hand side of (33) describes the geodesic or -projection of onto , so named because the tangent vector of the geodesic is orthogonal to  (the tangent space of at the point ). Furthermore, since is -flat, this projection is unique: there are no local minima of the divergence aside from this global minimum.
(the tangent space of at the point ). Furthermore, since is -flat, this projection is unique: there are no local minima of the divergence aside from this global minimum.
To elaborate, let
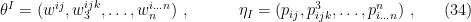
respectively denote the canonical and dual coordinates of , where as a shorthand we include both  and in , and both
and in , and both 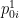 and
and  in
in  . Then recall that since
. Then recall that since 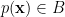 , we must have
, we must have 
 . Thus both and lie in the submanifold
. Thus both and lie in the submanifold

that is, the first part of the -coordinates are constrained to be , while the remainder are left free. This defines  in terms of a set of linear constraints in the -coordinates, and hence is an -flat manifold (analogous to how is an -flat manifold). The geodesic projection defined by (33) is therefore an -geodesic in (hence the name).
in terms of a set of linear constraints in the -coordinates, and hence is an -flat manifold (analogous to how is an -flat manifold). The geodesic projection defined by (33) is therefore an -geodesic in (hence the name).
The construction of also implies that the tangent space of at  ,
,  , is spanned by the basis vectors
, is spanned by the basis vectors 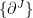 , where
, where  runs over the second (unspecified) part of the -coordinates. Similarly, is spanned by
runs over the second (unspecified) part of the -coordinates. Similarly, is spanned by  , where runs over the first (unspecified) part of the
, where runs over the first (unspecified) part of the  -coordinates (since is defined by fixing the second part to zero). Since
-coordinates (since is defined by fixing the second part to zero). Since 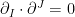 for
for 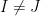 , we conclude that and are orthogonal at , and hence that the geodesic projection defined by (33) — that is, the -geodesic connecting and — is likewise orthogonal to . This is useful because it enables us to use the generalized Pythagorean theorem, in the form
, we conclude that and are orthogonal at , and hence that the geodesic projection defined by (33) — that is, the -geodesic connecting and — is likewise orthogonal to . This is useful because it enables us to use the generalized Pythagorean theorem, in the form
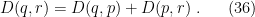
Here, the left-hand side plays the role of the hypotenuse: it is the divergence between the distribution and the current state of the Boltzmann machine  . This is given, on the right-hand side, by the aforementioned -geodesic representing the projection of “straight down” to , , and an -geodesic (because it lies entirely within ) representing the divergence between the current machine and the optimal machine ,
. This is given, on the right-hand side, by the aforementioned -geodesic representing the projection of “straight down” to , , and an -geodesic (because it lies entirely within ) representing the divergence between the current machine and the optimal machine ,  . Since we can’t leave the submanifold , the part is an unavoidable error: we can’t shrink the divergence between the current state of the machine and the target state to zero; note that this is independent of the current state of the machine, and arises simply from the fact that
. Since we can’t leave the submanifold , the part is an unavoidable error: we can’t shrink the divergence between the current state of the machine and the target state to zero; note that this is independent of the current state of the machine, and arises simply from the fact that 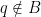 . We thus see that to accomplish our learning task, we need to minimize by bringing the current machine closer to the optimum; i.e., the learning trajectory is the e-geodesic connecting the state of the current machine to that of the optimal machine .
. We thus see that to accomplish our learning task, we need to minimize by bringing the current machine closer to the optimum; i.e., the learning trajectory is the e-geodesic connecting the state of the current machine to that of the optimal machine .
To move along this geodesic, we simply follow the steepest descent algorithm from the point . Denoting the connection weights thereof by (with apologies for reusing notation), the gradient is

where, in the first equality, we have used the aforementioned fact that the unavoidable error is independent of (and hence of ); as for the second, we have via (27)
![\displaystyle \frac{\partial}{\partial w_1^{ij}}D(w_1,w_2) =\frac{\partial}{\partial w_1^{ij}}\left[\phi(w_1)+\psi(w_2)-\sum_{i>j}w_1^{ij}{p_2}_{ij}\right] ={p_1}_{ij}-{p_2}_{ij}~, \ \ \ \ \ (38)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+w_1%5E%7Bij%7D%7DD%28w_1%2Cw_2%29+%3D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+w_1%5E%7Bij%7D%7D%5Cleft%5B%5Cphi%28w_1%29%2B%5Cpsi%28w_2%29-%5Csum_%7Bi%3Ej%7Dw_1%5E%7Bij%7D%7Bp_2%7D_%7Bij%7D%5Cright%5D+%3D%7Bp_1%7D_%7Bij%7D-%7Bp_2%7D_%7Bij%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2838%29&bg=ffffff&fg=000000&s=0&c=20201002)
where we have used the fact that, from (16),  ; we then identified
; we then identified  and
and 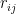 according to (8). We thus come full-circle to (7), i.e.,
according to (8). We thus come full-circle to (7), i.e.,

(Note the change of order). Of course, this expression is only valid in the dually flat coordinates above, and does not have an invariant meaning. But we can uplift the learning rule for steepest descent to a general Riemannian manifold simply by inserting the (inverse) metric:

Since the inverse metric merely interchanges upper and lower indices, the generalized rule (40) is still an -geodesic equation on , and is therefore linear in the -coordinates. As noted in [1], this may be practically relevant since, in addition to being more tractable, the convergence to the optimum is likely much faster than in more complicated (i.e., non-linear) networks.
The paper [1] goes on to generalize their results to Boltzmann machines with hidden units; while these are more useful in practice (particularly in the form of restricted Boltzmann machines), I will not discuss them here. Instead, let me close by tying back into the physics-lingo at the beginning, where I mentioned that Boltzmann machines belong to the class of energy-based models. In particular, note that the energy difference between the target and optimum is

Therefore, since  , we may think of the optimum Boltzmann machine as that which minimizes the energy difference between these two states, cf. (33). Thus the learning problem is intuitively the mandate that we flow to the minimum energy state, where here the energy is defined relative to the target distribution . And the solution — that is, the learning trajectory — is the minimum-length geodesic in the space of Boltzmann machines . Neat!
, we may think of the optimum Boltzmann machine as that which minimizes the energy difference between these two states, cf. (33). Thus the learning problem is intuitively the mandate that we flow to the minimum energy state, where here the energy is defined relative to the target distribution . And the solution — that is, the learning trajectory — is the minimum-length geodesic in the space of Boltzmann machines . Neat!
References
- S.-i. Amari, K. Kurata, and H. Nagaoka, “Information Geometry of Boltzmann Machines,” IEEE Transactions on Neural Networks 3 no. 2, (1992).
- D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, “A Learning Algorithm for Boltzmann Machines,” Cognitive Science 9 (1985).

