Insofar as quantum mechanics can be regarded as an extension of (classical) probability theory, most of the concepts developed in the previous two parts of this sequence can be extended to quantum information theory as well, thus giving rise to quantum information geometry.
Quantum preliminaries
Let’s first review a few basic quantum mechanical notions; we’ve covered this in more detail before, but it will be helpful to establish present notation/language.
Quantum mechanics is the study of linear operators acting on some complex Hilbert space 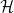 . We shall take this to be finite-dimensional, and hence identify
. We shall take this to be finite-dimensional, and hence identify 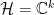 , the space of
, the space of  complex matrices, where
complex matrices, where  . In the usual bra-ket notation, the adjoint
. In the usual bra-ket notation, the adjoint 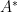 of an operator
of an operator  is defined by
is defined by 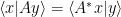 for all vectors
for all vectors  . The density operator
. The density operator  , which describes a quantum state, is a postive semidefinite hermitian operator of unit trace. is a pure state if it is of rank 1 (meaning it admits a representation of the form
, which describes a quantum state, is a postive semidefinite hermitian operator of unit trace. is a pure state if it is of rank 1 (meaning it admits a representation of the form  ), and mixed otherwise.
), and mixed otherwise.
A measurement 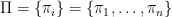 is a set of operators on which satisfy
is a set of operators on which satisfy

whose action on the state yields the outcome 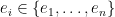 with probability
with probability
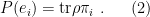
Note that by virtue of (1),  is a probability distribution:
is a probability distribution:

If we further impose that 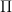 consist of orthogonal projections, i.e.,
consist of orthogonal projections, i.e.,
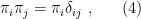
then the above describes a “simple measurement”, or PVM (projection-valued measure). More generally of course, a measurement is described by a POVM (positive operator-valued measure). We covered this concept in an earlier post, but the distinction will not be relevant here.
An observable is formally defined as the pair 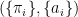 , where
, where 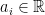 is a real number associated with the measurement outcome
is a real number associated with the measurement outcome 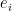 . Since
. Since  are orthogonal projectors, we may represent the observable as a (hermitian) operator acting on whose associated eigenvalues are
are orthogonal projectors, we may represent the observable as a (hermitian) operator acting on whose associated eigenvalues are  , i.e.,
, i.e.,

The expectation and variance of in the state are then
![\displaystyle E_\rho[A]=\sum_i\mathrm{tr}{\rho\pi_i}a_i=\mathrm{tr}{\rho A}~, \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%5Crho%5BA%5D%3D%5Csum_i%5Cmathrm%7Btr%7D%7B%5Crho%5Cpi_i%7Da_i%3D%5Cmathrm%7Btr%7D%7B%5Crho+A%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle V_\rho[A]=\sum_i\mathrm{tr}{\rho\pi_i}\left(a_i-E_\rho[A]\right)^2=\mathrm{tr}\!\left[\rho\left(A-E_\rho[A]\right)^2\right]~. \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_%5Crho%5BA%5D%3D%5Csum_i%5Cmathrm%7Btr%7D%7B%5Crho%5Cpi_i%7D%5Cleft%28a_i-E_%5Crho%5BA%5D%5Cright%29%5E2%3D%5Cmathrm%7Btr%7D%5C%21%5Cleft%5B%5Crho%5Cleft%28A-E_%5Crho%5BA%5D%5Cright%29%5E2%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
We shall denote the set of all operators on by

and define

Then the set of all density operators is a convex subset of  :
:

Note the similarities with the embedding formalism introduced in the previous post. The set of density operators admits a partition based on the rank of the matrix,

Pure states are then elements of 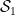 , which form the extreme points of the convex set
, which form the extreme points of the convex set  (i.e., they cannot be represented as convex combinations of other points, which is the statement that ). Geometrically, the pure states are the vertices of the convex hull, while the (strictly positive) mixed states
(i.e., they cannot be represented as convex combinations of other points, which is the statement that ). Geometrically, the pure states are the vertices of the convex hull, while the (strictly positive) mixed states  lie in the interior.
lie in the interior.
We need one more preliminary notion, namely the set 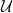 of unitary operators on :
of unitary operators on :
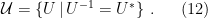
This forms a Lie group, whose action on is given by
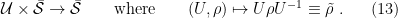
(The first expression says that the group multiplication by  sends elements of to , while the second specifies how this mapping acts on individual elements). Since the matrix rank is preserved, each
sends elements of to , while the second specifies how this mapping acts on individual elements). Since the matrix rank is preserved, each  is closed under the action of . It follows from (13) that maps measurements and observables to
is closed under the action of . It follows from (13) that maps measurements and observables to

and that the probability distributions and expectation values are therefore invariant, i.e.,

Of course, this last is the familiar statement that the unitarity of quantum mechanics ensures that probabilities are preserved.
Geometric preliminaries
Now, on to (quantum information) geometry! Let us restrict our attention to for now; we shall consider mixed states below. Recall that pure states are actually rays, not vectors, in Hilbert space. Since , we therefore identify  (i.e., the pure states are in one-to-one correspondence with the rays in
(i.e., the pure states are in one-to-one correspondence with the rays in 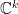 , where we’ve projected out by the physically irrelevant phase). We now wish to associate a metric to this space of states; in particular, we seek a Riemannian metric which is invariant under unitary transformations . It turns out that, up to an overall constant, this is uniquely provided by the Fubini-Study metric. Recall that when considering classical distributions, we found that the Fisher metric was the unique Riemannian metric that preserved the inner product. The Fubini-Study metric is thus the natural extension of the Fisher metric to the quantum mechanical case (for pure states only!). Unfortunately, Amari & Nagaoka neither define nor discuss this entity, but it’s reasonably well-known in the quantum information community, and has recently played a role in efforts to define holographic complexity in field theories. A particularly useful expression in this context is
, where we’ve projected out by the physically irrelevant phase). We now wish to associate a metric to this space of states; in particular, we seek a Riemannian metric which is invariant under unitary transformations . It turns out that, up to an overall constant, this is uniquely provided by the Fubini-Study metric. Recall that when considering classical distributions, we found that the Fisher metric was the unique Riemannian metric that preserved the inner product. The Fubini-Study metric is thus the natural extension of the Fisher metric to the quantum mechanical case (for pure states only!). Unfortunately, Amari & Nagaoka neither define nor discuss this entity, but it’s reasonably well-known in the quantum information community, and has recently played a role in efforts to define holographic complexity in field theories. A particularly useful expression in this context is

where  parametrizes the unitary
parametrizes the unitary  that performs the transformation between states in .
that performs the transformation between states in .
In the remainder of this post, we shall follow Amari & Nagaoka (chapter 7) in considering only mixed states; accordingly, for convenience, we hence forth denote  by simply
by simply 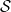 , i.e.,
, i.e.,

This is an open subset of , and thus we may regard it as a real manifold of dimension 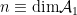 . Since the dimension of is given by the number of linearly independent basis vectors, minus 1 for the trace constraint,
. Since the dimension of is given by the number of linearly independent basis vectors, minus 1 for the trace constraint, 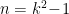 . The tangent space
. The tangent space  at a point is then identified with
at a point is then identified with

Note that this precisely parallels the embedding formalism used in defining the m-representation. Hence we denote a tangent vector  by
by  , and call it the m-representation of
, and call it the m-representation of  in analogy with the classical case. (We’ll come to the quantum analogue of the e-representation later).
in analogy with the classical case. (We’ll come to the quantum analogue of the e-representation later).
The PVM introduced above can also be represented in geometrical terms, via the submanifold

That is, 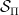 is the intersection of two sets. The first,
is the intersection of two sets. The first,  , is simply the set of all operators with unit trace. From (5), we recognize the second as the spectral representation of operators in the eigenbasis of . Imposing the trace constraint then implies that the eigenvalues of are weighted probabilities, where
, is simply the set of all operators with unit trace. From (5), we recognize the second as the spectral representation of operators in the eigenbasis of . Imposing the trace constraint then implies that the eigenvalues of are weighted probabilities, where 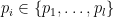 and
and  is the totality of positive probability distributions
is the totality of positive probability distributions 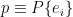 with
with ![{i\in[1,l]}](https://s0.wp.com/latex.php?latex=%7Bi%5Cin%5B1%2Cl%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . To see this, observe that
. To see this, observe that

since  ; this underlies the second equality in the expression for above.
; this underlies the second equality in the expression for above.
Lastly, the action of a unitary  at a point results in a new vector, given by the mapping (13), which lives in (a subspace of) the tangent space
at a point results in a new vector, given by the mapping (13), which lives in (a subspace of) the tangent space 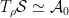 . Such elements may be written
. Such elements may be written
![\displaystyle \frac{\mathrm{d}}{\mathrm{d}t}U_t\rho U_t^{-1}\Big|_{t=0}=[\Omega,\rho]~, \ \ \ \ \ (21)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7Dt%7DU_t%5Crho+U_t%5E%7B-1%7D%5CBig%7C_%7Bt%3D0%7D%3D%5B%5COmega%2C%5Crho%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2821%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  is a curve in the space of unitaries with
is a curve in the space of unitaries with  , and
, and  is its derivative at
is its derivative at  (note that
(note that  corresponds to
corresponds to  in the expression for the Fubini-Study metric (16) above).
in the expression for the Fubini-Study metric (16) above).
With the above notions in hand, we may now proceed to introduce a dual structure 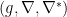 on , and thereby the quantum analogues of the
on , and thereby the quantum analogues of the  -connections, divergence, etc.
-connections, divergence, etc.
Quantum divergences
In part 2 of this sequence, we introduced the f-divergence, which satisfies a number of desireable properties such as monotonicity. It also serves as the super-class to which the -divergence belongs; the latter is particularly important, since it induces the dual structure consisting of the Fisher metric and  -connections, and reduces to the familiar Kullback-Leibler divergence (a.k.a. relative entropy) for
-connections, and reduces to the familiar Kullback-Leibler divergence (a.k.a. relative entropy) for 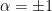 . We shall now introduce the quantum analogue of the f-divergence.
. We shall now introduce the quantum analogue of the f-divergence.
Denote by 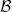 the set of all (not necessarily hermitian) operators on . Then given two strictly postive density operators
the set of all (not necessarily hermitian) operators on . Then given two strictly postive density operators  , the relative modular operator
, the relative modular operator  is defined by
is defined by
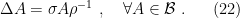
Since  may be viewed as a hermitian and positive-definite operator on the Hilbert space, we may promote an arbitrary function
may be viewed as a hermitian and positive-definite operator on the Hilbert space, we may promote an arbitrary function  to a hermitian operator
to a hermitian operator  on said space such that
on said space such that

We then define the quantum f-divergence as
![\displaystyle D_f(\rho||\sigma)=\mathrm{tr}\left[\rho f(\Delta)\,1\right]~, \ \ \ \ \ (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D_f%28%5Crho%7C%7C%5Csigma%29%3D%5Cmathrm%7Btr%7D%5Cleft%5B%5Crho+f%28%5CDelta%29%5C%2C1%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2824%29&bg=ffffff&fg=000000&s=0&c=20201002)
To see how this is consistent with (that is, reduces to) the classical f-divergence defined previously, consider the spectral representations

where , 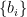 are the eigenvalues for the PVMs
are the eigenvalues for the PVMs 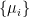 ,
,  . Then from the definition of the relative modular operator above,
. Then from the definition of the relative modular operator above,
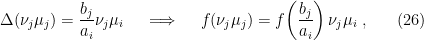
and hence for simple measurements,
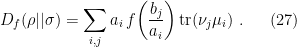
To compare with the classical expression given in part 2 (cf. eq. (18)), we must take into account the fact that  and
and  are only independently orthonormal (that is, it does not follow that
are only independently orthonormal (that is, it does not follow that  ). Accordingly, consider performing sequential measurement followed by , i.e.,
). Accordingly, consider performing sequential measurement followed by , i.e.,  with
with  . This can be used to constructed the POVM
. This can be used to constructed the POVM  , where
, where

where we have used the orthonormality of . Applying von Neumann’s projection hypothesis, this takes the initial state to the final state 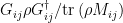 with probability
with probability
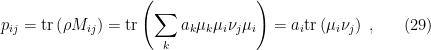
where in the last step we have again used the orthonormality condition (4), and the cyclic property of the trace. Similarly, by inverting this sequence of measurements, we may construct the POVM with elements  . Let us denote the probabilities associated with the outcomes of acting on as
. Let us denote the probabilities associated with the outcomes of acting on as  . Solving for the eigenvalues
. Solving for the eigenvalues  and
and 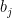 in these expressions then enables one rewrite (27) in terms of the probability distributions
in these expressions then enables one rewrite (27) in terms of the probability distributions  ,
,  , whereupon we find
, whereupon we find
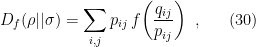
which is the discrete analogue of the classical divergence referenced above.
Now, recall that every dual structure is naturally induced by a divergence. In particular, it follows from Chentsov’s theorem that the Fisher metric and -connections are induced from the f-divergence  for any smooth convex function which satisfies
for any smooth convex function which satisfies

Thus, to find the formal quantum analogues of these objects, we restrict to the class of functions  which satisfy the above conditions, whereupon the quantum f-divergence induces the dual structure
which satisfy the above conditions, whereupon the quantum f-divergence induces the dual structure 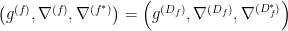 , where
, where  . In fact, for a simple measurement which diagonalizes , the restriction of this triple to
. In fact, for a simple measurement which diagonalizes , the restriction of this triple to  coincides precisely with the Fisher metric and
coincides precisely with the Fisher metric and  -connections. Additionally, note that is invariant under unitary transformations, in the sense that
-connections. Additionally, note that is invariant under unitary transformations, in the sense that  ; in other words, for arbitrary vector fields ,
; in other words, for arbitrary vector fields ,  , we have
, we have

where  is formally understood as the vector field such that
is formally understood as the vector field such that  . Thus
. Thus  ,
, 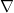 , and
, and  are indeed invariant under the action of , which is the characteristic property of the classical analogues we wanted to preserve.
are indeed invariant under the action of , which is the characteristic property of the classical analogues we wanted to preserve.
As in the classical case, we can further restrict the class of functions to satisfy eq.~(20) in part 1, which defines the quantum -divergence  . Then for
. Then for 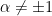 , we obtain
, we obtain
![\displaystyle D^{(\alpha)}(\rho||\sigma)=\frac{4}{1-\alpha^2}\left[1-\mathrm{tr}\left(\rho^{\frac{1-\alpha}{2}}\sigma^{\frac{1+\alpha}{2}}\right)\right]~, \ \ \ \ \ (33)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D%5E%7B%28%5Calpha%29%7D%28%5Crho%7C%7C%5Csigma%29%3D%5Cfrac%7B4%7D%7B1-%5Calpha%5E2%7D%5Cleft%5B1-%5Cmathrm%7Btr%7D%5Cleft%28%5Crho%5E%7B%5Cfrac%7B1-%5Calpha%7D%7B2%7D%7D%5Csigma%5E%7B%5Cfrac%7B1%2B%5Calpha%7D%7B2%7D%7D%5Cright%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2833%29&bg=ffffff&fg=000000&s=0&c=20201002)
while for , we instead have
![\displaystyle D^{(-1)}(\rho||\sigma)=D^{(1)}(\sigma||\rho)=\mathrm{tr}\left[\rho\left(\ln\rho-\ln\sigma\right)\right]~, \ \ \ \ \ (34)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D%5E%7B%28-1%29%7D%28%5Crho%7C%7C%5Csigma%29%3DD%5E%7B%281%29%7D%28%5Csigma%7C%7C%5Crho%29%3D%5Cmathrm%7Btr%7D%5Cleft%5B%5Crho%5Cleft%28%5Cln%5Crho-%5Cln%5Csigma%5Cright%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2834%29&bg=ffffff&fg=000000&s=0&c=20201002)
cf. eq. (21) and (22) ibid. In obtaining these expressions, we used the fact that the relative modular operator satisfies
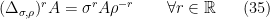
and

where the  -power and logarithm of an operator with eigenvalues
-power and logarithm of an operator with eigenvalues 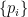 are defined such that these become
are defined such that these become 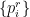 and
and  , respectively, with the same (original) orthonormal eigenvectors. Of course, the quantum analogue of the Kullback-Leibler divergence (34) is none other than the quantum relative entropy!
, respectively, with the same (original) orthonormal eigenvectors. Of course, the quantum analogue of the Kullback-Leibler divergence (34) is none other than the quantum relative entropy!
Many of the classical geometric relations can also be extended to the quantum case. In particular, is dually flat with respect to 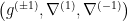 , and the canonical divergence is the (quantum) relative entropy
, and the canonical divergence is the (quantum) relative entropy  . And as in the discussion of (classical) exponential families, we can parameterize the elements of an arbitrary
. And as in the discussion of (classical) exponential families, we can parameterize the elements of an arbitrary  -autoparallel submanifold
-autoparallel submanifold  as
as
![\displaystyle \rho_\theta=\mathrm{exp}\left[C+\theta^iF_i-\psi(\theta)\right]~, \ \ \ \ \ (37)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Crho_%5Ctheta%3D%5Cmathrm%7Bexp%7D%5Cleft%5BC%2B%5Ctheta%5EiF_i-%5Cpsi%28%5Ctheta%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2837%29&bg=ffffff&fg=000000&s=0&c=20201002)
where now  are hermitian operators, and
are hermitian operators, and  is an
is an 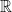 -valued function on the canonical parameters
-valued function on the canonical parameters ![{[\theta^i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctheta%5Ei%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . As in the classical case, these form a 1-affine coordinate system, and hence the dual
. As in the classical case, these form a 1-affine coordinate system, and hence the dual 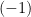 -affine coordinates are given by
-affine coordinates are given by 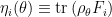 , which naturally extends the classical definition in terms of the expectation value of
, which naturally extends the classical definition in terms of the expectation value of  , cf. eq. (36) of part 2. Recall that and
, cf. eq. (36) of part 2. Recall that and ![{[\eta_i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ceta_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) are related through the dual potential
are related through the dual potential 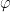 , defined via the Legendre transform
, defined via the Legendre transform
![\displaystyle \varphi(\theta)=\mathrm{sup}_{\theta'}\left[\theta'^i\eta_i(\theta)-\psi(\theta')\right]~. \ \ \ \ \ (38)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvarphi%28%5Ctheta%29%3D%5Cmathrm%7Bsup%7D_%7B%5Ctheta%27%7D%5Cleft%5B%5Ctheta%27%5Ei%5Ceta_i%28%5Ctheta%29-%5Cpsi%28%5Ctheta%27%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2838%29&bg=ffffff&fg=000000&s=0&c=20201002)
Taking a derivative of the bracketed quantity, the maximum occurs when 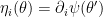 , where the derivative is with respect to
, where the derivative is with respect to 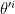 . But this condition precisely corresponds to the definition of
. But this condition precisely corresponds to the definition of 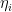 above, cf. eq. (37) in part 2. Hence
above, cf. eq. (37) in part 2. Hence
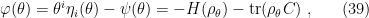
where we have identified the von Neumann entropy 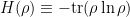 , and used the fact that
, and used the fact that 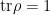 (that is,
(that is, 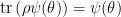 ).
).
As one might expect from the appearance of the von Neumann entropy, several other important concepts in quantum information theory emerge naturally from this framework. For example, the monotonicity of the classical f-divergence can be extended to the quantum f-divergence as well, whence satisfies the monotonicity relation

for any completely positive trace-preserving map  (i.e., a quantum channel), and operator convex function ; see section 7.2 for more details. Since the -divergence is a special case of the f-divergence, this result implies the monotonicity of relative entropy (a detailed analysis can be found in [1]).
(i.e., a quantum channel), and operator convex function ; see section 7.2 for more details. Since the -divergence is a special case of the f-divergence, this result implies the monotonicity of relative entropy (a detailed analysis can be found in [1]).
To close, let us comment briefly on some relations to Tomita-Takesaki modular theory. In this context, the relative modular operator is defined through the relative Tomita-Takesaki anti-linear operator  , and provides a definition of relative entropy even for type-III factors. For finite-dimensional systems, one can show that this reduces precisely to the familiar definition of quantum relative entropy given above. For more details, I warmly recommend the recent review by Witten [2]. Additionally, the fact that satisfies monotonicity (40) corresponds to the statement that the relative entropy is monotonic under inclusions, which can in turn be used to demonstrate positivity of the generator of (half-sided) modular inclusions; see [3] for an application of these ideas in the context of the eternal black hole.
, and provides a definition of relative entropy even for type-III factors. For finite-dimensional systems, one can show that this reduces precisely to the familiar definition of quantum relative entropy given above. For more details, I warmly recommend the recent review by Witten [2]. Additionally, the fact that satisfies monotonicity (40) corresponds to the statement that the relative entropy is monotonic under inclusions, which can in turn be used to demonstrate positivity of the generator of (half-sided) modular inclusions; see [3] for an application of these ideas in the context of the eternal black hole.
References
- A. Mueller-Hermes and D. Reeb, “Monotonicity of the quantum relative entropy under positive maps,” arXiv:1512.06117 [quant-ph]
- E. Witten, “Notes on some entanglement properties of quantum field theory,” arXiv:1803.04993 [hep-th]
- R. Jefferson, “Comments on black hole interiors and modular inclusions,” arXiv:1811.08900 [hep-th]


hi, thank you very much for your beautiful and useful posts, I have a question, do methods of information geometry have applications in Ads/CFT or holographic quantum error correction or computational complexity which is the focus of your work
LikeLike
Thank you, I’m very glad you enjoyed them!
In fact, one of the reasons I became interested in information geometry was because of its potential applications to holographic complexity. In the original paper with Rob Myers — in which we put forth a first definition of complexity for quantum field theories — “complexity” is basically identified with the minimum distance between quantum states. In order for “distance” to have a well-defined meaning, we first had to figure out how to define a geometry on the space of states, after which we could compute geodesics. But for technical reasons, our analysis was limited to free theories, and extending this concept to interacting theories has proven challenging.
Information geometry does something very similar: one gets a geometry on the space of probability distributions. Hence if one works at the level of wavefunctions, it’s natural to ask whether this provides a more general way of inducing a geometry on the space of states than the approach from circuit complexity mentioned above. In particular, I’d like to know whether this technology can be used to move beyond the class of Gaussian states. To really make contact with holography, we need a definition of complexity for strongly interacting CFTs, since this is the class of theories known to have good bulk duals.
More generally, as you seem well aware, the past few years have seen the rise of a fascinating interplay between quantum information theory and high energy physics, particularly in the context of emergent spacetime or “it from qubit”. In AdS/CFT, entanglement entropy has taken center stage in efforts to reconstruct the bulk spacetime. Relative entropy, for example, has proven particularly important—and it emerges quite naturally in information geometry as the Kullback-Leibler divergence. Given these deepening connections, my personal sense is that information geometry may provide a powerful framework for furthering our understanding of this interplay, but I have no idea whether it will ultimately be of any practical use. That’s why we call it “research”. 😉
LikeLike