In a previous post, I alluded to the question of whether criticality played any role in deep neural networks. The question I originally had in mind was whether the fact that the correlation length diverges at a critical point implies an advantage in terms of information propagation in such systems. In particular, would a neural net operating at or near the critical point (e.g., by savvy initialization of weights and biases) exhibit advantages in training or performance? As it turns out, a few papers have actually addressed this issue using a prescription from physics known as mean field theory (MFT). In this two-part sequence, I’d like to first explain briefly what MFT is, and then in part 2 understand how machine learning researchers have applied it to obtain impressive real-world improvements in training performance.
In a nutshell, the idea behind MFT is that most partition functions (containing interactions) are too hard to evaluate explicitly, but can be made tractable by replacing each degree of freedom, together with its interactions, with an effective degree of freedom — the mean field — in which these interactions have been averaged over. Note that MFT is an approximation, for two reasons: it ignores higher-order fluctuations, and the averaging prescription necessarily washes-out some fine-grained information. We’ll cover both these points in more detail below, when discussing the situations under which MFT fails. Perhaps ironically given the previous paragraph, MFT breaks down precisely at the critical point, so it’s important to understand the conditions under which the associated predictions are valid.
To make our discussion concrete, consider the  -dimensional Ising hamiltonian with
-dimensional Ising hamiltonian with  spins total (i.e.,
spins total (i.e.,  spins per direction):
spins per direction):
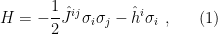
where 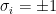 , and for compactness I’m employing Einstein’s summation convention with
, and for compactness I’m employing Einstein’s summation convention with 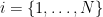 and
and 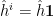 . Since all directions are spacelike, there’s no difference between raised and lowered indices (e.g.,
. Since all directions are spacelike, there’s no difference between raised and lowered indices (e.g.,  ), so I’ll denote the inverse matrix
), so I’ll denote the inverse matrix 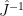 explicitly to avoid any possible confusion, i.e.,
explicitly to avoid any possible confusion, i.e.,  and
and  . In a 1d lattice, one would typically avoid boundary effects by joining the ends into an
. In a 1d lattice, one would typically avoid boundary effects by joining the ends into an 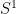 by setting
by setting  , but this issue won’t be relevant for our purposes, as we’ll be interested in the thermodynamic limit
, but this issue won’t be relevant for our purposes, as we’ll be interested in the thermodynamic limit 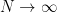 anyway.
anyway.
One approach to constructing a MFT for this model is to observe that for a given spin 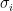 , the effect of all the other spins acts like an external magnetic field. That is, observe that we may write (1) as
, the effect of all the other spins acts like an external magnetic field. That is, observe that we may write (1) as
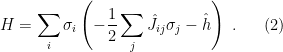
We then replace 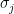 by the average value,
by the average value,  . We’ll give a more thorough Bayesian treatment of MFT below, but the idea here is that since no spin is special, the most likely value of is the mean. This allows us to define an effective magnetic field at site
. We’ll give a more thorough Bayesian treatment of MFT below, but the idea here is that since no spin is special, the most likely value of is the mean. This allows us to define an effective magnetic field at site  :
:
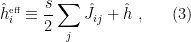
so that the hamiltonian becomes
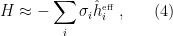
where the interactions have been absorbed into the effective magnetic field. Thus we’ve reduced an interacting many-body problem to a non-interacting one-body problem, which is much easier to solve!
As mentioned above however, this result is an approximation, which in the present case amounts to neglecting the correlation between spins at different sites. That is, when we replaced by the mean, we secretly discarded terms of order  . This is illustrated explicitly in John McGreevy’s entertaining notes on the Renormalization Group, and runs as follows. As mentioned above, one can think of MFT as the replacement of the degrees of freedom by the average value plus fluctuations:
. This is illustrated explicitly in John McGreevy’s entertaining notes on the Renormalization Group, and runs as follows. As mentioned above, one can think of MFT as the replacement of the degrees of freedom by the average value plus fluctuations:
![\displaystyle \begin{aligned} \sigma_i\sigma_i&=\left[s+(\sigma_i-s)\right]\left[s+(\sigma_j-s)\right] =\left( s+\delta s_i\right)\left( s+\delta s_j\right)\\ &=s^2+s\left( \delta s_i+\delta s_j\right)+O(\delta s^2) =-s^2+s\left(\sigma_i+\sigma_j\right)+O(\delta s^2)~, \end{aligned} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csigma_i%5Csigma_i%26%3D%5Cleft%5Bs%2B%28%5Csigma_i-s%29%5Cright%5D%5Cleft%5Bs%2B%28%5Csigma_j-s%29%5Cright%5D+%3D%5Cleft%28+s%2B%5Cdelta+s_i%5Cright%29%5Cleft%28+s%2B%5Cdelta+s_j%5Cright%29%5C%5C+%26%3Ds%5E2%2Bs%5Cleft%28+%5Cdelta+s_i%2B%5Cdelta+s_j%5Cright%29%2BO%28%5Cdelta+s%5E2%29+%3D-s%5E2%2Bs%5Cleft%28%5Csigma_i%2B%5Csigma_j%5Cright%29%2BO%28%5Cdelta+s%5E2%29%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 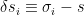 . We then substitute this into the hamiltonian (1); taking
. We then substitute this into the hamiltonian (1); taking  for simplicity, we obtain
for simplicity, we obtain

Note that the first term is some constant factor of the lattice size, and hence doesn’t affect the dynamics (we simply absorb it into the normalization of the partition function). If we then define an effective action as in (3) (with a suitable factor of 2) and work to linear order in the fluctuations, we recover the effective one-body hamiltonian (4). Thus, in the course of our mean field approximation, we averaged over the fluctuations, but lost some information about the interactions between spins.
Despite its approximate nature, the hamiltonian (6) (equivalently, (1)) is quite useful insofar as it can be used to obtain upper bound on the free energy. To understand this, let us introduce the Bayesian perspective promised above. In MFT, we’re ignoring some information about the system at hand, but we want to make inferences that are as accurate as possible subject to the available constraints. Recall from our discussion of entropy that if we do not know the underlying distribution with respect to which a particular expectation value is computed, the most rational choice is obtained by maximizing the von Neumann entropy. In particular, if we know the average energy, 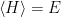 , this procedure yields the Boltzmann distribution
, this procedure yields the Boltzmann distribution
![\displaystyle p_i\equiv p(x_i)=\frac{1}{Z[\beta]}e^{-\beta E_i}~, \qquad\qquad\sum_ip_i=1~, \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p_i%5Cequiv+p%28x_i%29%3D%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7De%5E%7B-%5Cbeta+E_i%7D%7E%2C+%5Cqquad%5Cqquad%5Csum_ip_i%3D1%7E%2C+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  , and we identify the inverse temperature
, and we identify the inverse temperature  as the Lagrange multiplier arising from the constraint on the energy.
as the Lagrange multiplier arising from the constraint on the energy.
Now suppose that instead of knowing the average energy, we know only the temperature (i.e., we consider the canonical rather than microcanonical ensemble). As explained in a previous post, this amounts to a constraint in the (canonically) dual space, so the appropriate extremization procedure is instead to minimize the free energy,

(Note that for a given energy configuration, the free energy is minimized when the entropy is maximized). One finds again (7), with ![{Z[\beta]=e^{\beta\lambda}}](https://s0.wp.com/latex.php?latex=%7BZ%5B%5Cbeta%5D%3De%5E%7B%5Cbeta%5Clambda%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) where
where  is the Lagrange multiplier for the normalization constraint, cf. the max-ent procedure here.
is the Lagrange multiplier for the normalization constraint, cf. the max-ent procedure here.
The upshot is that the max-ent distribution (7) has minimum free energy: had we used any other distribution, it would amount to the imposition of additional constraints on the system, thereby reducing the entropy and increasing  in (8). This is essentially what happens in MFT, since we select a more tractable distribution with respect to which we can compute expectation values (i.e., a simpler hamiltonian, with a constraint on the fluctuations). In the present case, this implies that the normalized free energy obtained via the mean-field hamiltonian (6), denoted
in (8). This is essentially what happens in MFT, since we select a more tractable distribution with respect to which we can compute expectation values (i.e., a simpler hamiltonian, with a constraint on the fluctuations). In the present case, this implies that the normalized free energy obtained via the mean-field hamiltonian (6), denoted  , provides an upper bound on the true (equilibrium) free energy
, provides an upper bound on the true (equilibrium) free energy  :
:

where 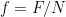 (henceforth I’ll refer to this simply as the free energy, without the “normalized” qualifier). This statement, sometimes referred to as the Bogolyubov inequality, can be easily shown to follow from Gibb’s inequality. (This apparently standard derivation is however not a sufficient explanation per se, since it simply assumes that expectation values are taken with respect to the mean-field distribution. Had we chosen to take them with respect to the equilibrium (max-ent) distribution, the bound would be reversed!)
(henceforth I’ll refer to this simply as the free energy, without the “normalized” qualifier). This statement, sometimes referred to as the Bogolyubov inequality, can be easily shown to follow from Gibb’s inequality. (This apparently standard derivation is however not a sufficient explanation per se, since it simply assumes that expectation values are taken with respect to the mean-field distribution. Had we chosen to take them with respect to the equilibrium (max-ent) distribution, the bound would be reversed!)
Working to linear order in the fluctuations, the mean-field partition function for (6) is
![\displaystyle \begin{aligned} Z_\textrm{\tiny{MF}}&=\sum_{\{\sigma\}}e^{-\beta H_\textrm{\tiny{MF}}} =\prod_{k=1}^N\sum_{\sigma_k=\pm1}\exp\left[-NdJs^2+\left(2dJs+h\right)\sum_i\sigma_i\right]\\ &=e^{-NdJs^2}\prod_{k=1}^N\exp\left[-\left(2dJs+h\right)+\left(2dJs+h\right)\right]\\ &=2^Ne^{-NdJs^2}\cosh^N\left(2dJs+h\right)~. \end{aligned} \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+Z_%5Ctextrm%7B%5Ctiny%7BMF%7D%7D%26%3D%5Csum_%7B%5C%7B%5Csigma%5C%7D%7De%5E%7B-%5Cbeta+H_%5Ctextrm%7B%5Ctiny%7BMF%7D%7D%7D+%3D%5Cprod_%7Bk%3D1%7D%5EN%5Csum_%7B%5Csigma_k%3D%5Cpm1%7D%5Cexp%5Cleft%5B-NdJs%5E2%2B%5Cleft%282dJs%2Bh%5Cright%29%5Csum_i%5Csigma_i%5Cright%5D%5C%5C+%26%3De%5E%7B-NdJs%5E2%7D%5Cprod_%7Bk%3D1%7D%5EN%5Cexp%5Cleft%5B-%5Cleft%282dJs%2Bh%5Cright%29%2B%5Cleft%282dJs%2Bh%5Cright%29%5Cright%5D%5C%5C+%26%3D2%5ENe%5E%7B-NdJs%5E2%7D%5Ccosh%5EN%5Cleft%282dJs%2Bh%5Cright%29%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
where for simplicity we have restricted to homogeneous nearest-neighbor interactions (in spatial dimensions, each of the spins has 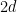 neighbors with coupling strength
neighbors with coupling strength  and
and 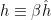 ). The corresponding free energy is then
). The corresponding free energy is then
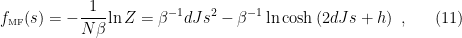
where we have dropped the  term, since this doesn’t contribute to any of the observables for which serves as a generating function (that is, it’s just a normalization factor).
term, since this doesn’t contribute to any of the observables for which serves as a generating function (that is, it’s just a normalization factor).
Now, as per our discussion above, (11) provides an upper bound on the true free energy. Thus we can obtain the tightest possible bound (given our ansatz (6)) by minimizing over  :
:

This last is referred to as the self-consistency condition. The reason is that it’s precisely what we would have obtained had we computed the average spin via the single-site hamiltonian (6), or equivalently (4): since the linear term has been absorbed into the effective magnetic field  , it looks as though
, it looks as though  , and therefore
, and therefore

where  . Substituting in (3) for the homogeneous nearest-neighbor case at hand (that is, without the factor of
. Substituting in (3) for the homogeneous nearest-neighbor case at hand (that is, without the factor of  , cf. (6)) then gives precisely (12).
, cf. (6)) then gives precisely (12).
The self-consistency equation can be solved graphically, i.e., the critical points are given by the intersections of the left- and right-hand sides; see [1] for a pedagogical treatment. In brief, for  , the global minimum of
, the global minimum of  is given by the intersection at positive , regardless of temperature. For
is given by the intersection at positive , regardless of temperature. For  in contrast, there’s a single minimum at
in contrast, there’s a single minimum at  for high temperatures, and two degenerate minima at
for high temperatures, and two degenerate minima at  at low temperatures (depending on whether
at low temperatures (depending on whether  crosses for
crosses for  ; to see this, recall that for small
; to see this, recall that for small  ,
,  , so a sufficiently small value of makes this an approximately straight line whose slope is less than ). The critical temperature that divides these two regimes is found by imposing that
, so a sufficiently small value of makes this an approximately straight line whose slope is less than ). The critical temperature that divides these two regimes is found by imposing that

Note that this is completely wrong for low dimensions! For  ,
,  , while for
, while for 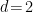 ,
, 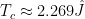 ; we’ll have more to say about this failure below.
; we’ll have more to say about this failure below.
Let’s concentrate on the case henceforth: note that the critical point 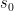 will always be small (
will always be small ( ) independent of
) independent of  (since
(since  ), so we can expand
), so we can expand

whence the free energy (11) near the critical point is approximately

where we have defined

and dropped all higher-order terms. Observe that the sign of  changes at the critical temperature
changes at the critical temperature  , which determines whether the global minimum of lies at
, which determines whether the global minimum of lies at  (
( ) or
) or  (
( ). The physical interpretation is that below the critical temperature, it is energetically favourable for the spins to align, resulting in a non-zero magnetization (which is what the average spin
). The physical interpretation is that below the critical temperature, it is energetically favourable for the spins to align, resulting in a non-zero magnetization (which is what the average spin 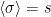 is). Above the critical temperature however, thermal fluctuations disrupt this ordering, so the net magnetization is zero. For this reason, the magnetization is an example of an order parameter, since it parametrizes which “order” — that is, which phase — we’re in on either side of the critical point.
is). Above the critical temperature however, thermal fluctuations disrupt this ordering, so the net magnetization is zero. For this reason, the magnetization is an example of an order parameter, since it parametrizes which “order” — that is, which phase — we’re in on either side of the critical point.
As alluded above however, there’s a problem with the MFT results for the critical point, namely that it’s precisely at the critical point where MFT breaks down! The reason is that at the critical point, fluctuations at all scales are important, whereas MFT includes only fluctuations to linear order (cf. (5)). The contribution from all scales is related to the statement we made in the introductory paragraph, namely that the correlation length diverges at the critical point. To properly understand this, we need to go beyond the MFT approach above. In particular, while the discrete lattice is a helpful starting point, we can gain further insight by considering a continuum field theory. We’ll see that MFT corresponds to the leading-order saddle point approximation, and that the first corrections to this expansion can qualitatively change these results.
To proceed, we’ll map our square-lattice Ising model to an equivalent theory of scalar fields. (If you like, you can just jump to the Ginzburg-Landau action (32) and take it as an ansatz, but I find the mapping both neat and instructive). Starting again from (1), the partition function is

where as before we have absorbed the pesky factor of by defining  ,
,  . The first step is to apply the Hubbard-Stratanovich transformation,
. The first step is to apply the Hubbard-Stratanovich transformation,
![\displaystyle e^{\frac{1}{2}K^{ij}s_is_j}=\left[\frac{\mathrm{det}K}{(2\pi)^N}\right]^{1/2}\!\int\!\mathrm{d}^N\phi\exp\left(-\frac{1}{2}K^{ij}\phi_i\phi_j+K^{ij}s_i\phi_j\right)~, \qquad\forall\,s_i\in\mathbb{R}~. \ \ \ \ \ (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+e%5E%7B%5Cfrac%7B1%7D%7B2%7DK%5E%7Bij%7Ds_is_j%7D%3D%5Cleft%5B%5Cfrac%7B%5Cmathrm%7Bdet%7DK%7D%7B%282%5Cpi%29%5EN%7D%5Cright%5D%5E%7B1%2F2%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5Cphi%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B2%7DK%5E%7Bij%7D%5Cphi_i%5Cphi_j%2BK%5E%7Bij%7Ds_i%5Cphi_j%5Cright%29%7E%2C+%5Cqquad%5Cforall%5C%2Cs_i%5Cin%5Cmathbb%7BR%7D%7E.+%5C+%5C+%5C+%5C+%5C+%2819%29&bg=ffffff&fg=000000&s=0&c=20201002)
(We used this before in our post on restricted Boltzmann machines; the difference here is that we want to allow  ). Applying this transformation to the first term in the partition function, we have
). Applying this transformation to the first term in the partition function, we have
![\displaystyle Z=\left[\frac{\mathrm{det}J}{(2\pi)^N}\right]^{1/2}\!\int\!\mathrm{d}^N\phi\sum_{\{\sigma\}}\exp\left[-\frac{1}{2}J^{ij}\phi_i\phi_j+\left( J^{ij}\phi_j+h^i\right)\sigma_i\right]~. \ \ \ \ \ (20)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3D%5Cleft%5B%5Cfrac%7B%5Cmathrm%7Bdet%7DJ%7D%7B%282%5Cpi%29%5EN%7D%5Cright%5D%5E%7B1%2F2%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5Cphi%5Csum_%7B%5C%7B%5Csigma%5C%7D%7D%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7Bij%7D%5Cphi_i%5Cphi_j%2B%5Cleft%28+J%5E%7Bij%7D%5Cphi_j%2Bh%5Ei%5Cright%29%5Csigma_i%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=0&c=20201002)
At a computational level, the immediate advantage of the Hubbard-Stratanovich transformation in the present case is that we can sum over the binary spins  , leaving us with an expression entirely in terms of the new field variables
, leaving us with an expression entirely in terms of the new field variables  . Observe that for each spin,
. Observe that for each spin,
![\displaystyle \sum_{\sigma_i=\pm1}\exp\left[\left( J^{ij}\phi_j+h^i\right)\sigma_i\right]=2\cosh\left( J^{ij}\phi_j+h^i\right)~, \ \ \ \ \ (21)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7B%5Csigma_i%3D%5Cpm1%7D%5Cexp%5Cleft%5B%5Cleft%28+J%5E%7Bij%7D%5Cphi_j%2Bh%5Ei%5Cright%29%5Csigma_i%5Cright%5D%3D2%5Ccosh%5Cleft%28+J%5E%7Bij%7D%5Cphi_j%2Bh%5Ei%5Cright%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%2821%29&bg=ffffff&fg=000000&s=0&c=20201002)
and therefore by re-exponentiating this expression, the partition function becomes
![\displaystyle Z=\left[\left(\frac{2}{\pi}\right)^N\!\mathrm{det}J\right]^{1/2}\!\int\!\mathrm{d}^N\phi\exp\!\left[-\frac{1}{2}J^{ij}\phi_i\phi_j+\sum_i\ln\cosh\left( J^{ij}\phi_j+h^i\right)\right]~. \ \ \ \ \ (22)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3D%5Cleft%5B%5Cleft%28%5Cfrac%7B2%7D%7B%5Cpi%7D%5Cright%29%5EN%5C%21%5Cmathrm%7Bdet%7DJ%5Cright%5D%5E%7B1%2F2%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5Cphi%5Cexp%5C%21%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7Bij%7D%5Cphi_i%5Cphi_j%2B%5Csum_i%5Cln%5Ccosh%5Cleft%28+J%5E%7Bij%7D%5Cphi_j%2Bh%5Ei%5Cright%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2822%29&bg=ffffff&fg=000000&s=0&c=20201002)
We now observe that  can be thought of as the mean field
can be thought of as the mean field 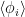 at site , incorporating the interaction with all other sites as well as the external magnetic field. We can then express the partition function in terms of the mean field
at site , incorporating the interaction with all other sites as well as the external magnetic field. We can then express the partition function in terms of the mean field  by inverting this identification:
by inverting this identification:
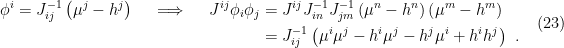
As for the change in the measure, it follows from the anti-symmetry of the wedge product, together with the fact that 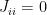 , that
, that

Hence the partition function may be equivalently expressed as
![\displaystyle Z=\left[\left(\frac{2}{\pi}\right)^N\!\mathrm{det}J^{-1}\right]^{1/2}\!e^{-\frac{1}{2}J^{-1}_{ij}h^ih^j}\!\int\!\mathrm{d}^N\!\mu\exp\!\left[-\frac{1}{2}J^{-1}_{ij}\mu^i\mu^j+J^{-1}_{ij}h^i\mu^j+\sum_i\ln\cosh\mu_i\right]~, \ \ \ \ \ (25)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%3D%5Cleft%5B%5Cleft%28%5Cfrac%7B2%7D%7B%5Cpi%7D%5Cright%29%5EN%5C%21%5Cmathrm%7Bdet%7DJ%5E%7B-1%7D%5Cright%5D%5E%7B1%2F2%7D%5C%21e%5E%7B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7B-1%7D_%7Bij%7Dh%5Eih%5Ej%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5C%21%5Cmu%5Cexp%5C%21%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7B-1%7D_%7Bij%7D%5Cmu%5Ei%5Cmu%5Ej%2BJ%5E%7B-1%7D_%7Bij%7Dh%5Ei%5Cmu%5Ej%2B%5Csum_i%5Cln%5Ccosh%5Cmu_i%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2825%29&bg=ffffff&fg=000000&s=0&c=20201002)
where I’ve assumed . While this only becomes a proper (mean) field theory in the thermodynamic limit, it’s worth emphasizing that up to this point, the transformation from the original lattice model (18) to is exact!
Now comes the approximation: to obtain a more tractable expression, let’s consider the case where the external magnetic field is very small as we did above. In this case, since the spin interactions don’t induce any preferred direction, we expect the mean field to be centered near zero, i.e., 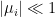 . We can then expand
. We can then expand
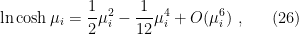
whereupon the partition function becomes
![\displaystyle Z\approx\left[\left(\frac{2}{\pi}\right)^N\!\mathrm{det}J^{-1}\right]^{1/2}\!e^{-\frac{1}{2}J^{-1}_{ij}h^ih^j}\!\int\!\mathrm{d}^N\mu\exp\!\left[-\frac{1}{2}J^{-1}_{ij}\mu^i\mu^j +J^{-1}_{ij}h^i\mu^j +\sum_i\left(\frac{1}{2}\mu_i^2-\frac{1}{12}\mu_i^4\right)\right]~. \ \ \ \ \ (27)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5Capprox%5Cleft%5B%5Cleft%28%5Cfrac%7B2%7D%7B%5Cpi%7D%5Cright%29%5EN%5C%21%5Cmathrm%7Bdet%7DJ%5E%7B-1%7D%5Cright%5D%5E%7B1%2F2%7D%5C%21e%5E%7B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7B-1%7D_%7Bij%7Dh%5Eih%5Ej%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5Cmu%5Cexp%5C%21%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7B-1%7D_%7Bij%7D%5Cmu%5Ei%5Cmu%5Ej+%2BJ%5E%7B-1%7D_%7Bij%7Dh%5Ei%5Cmu%5Ej+%2B%5Csum_i%5Cleft%28%5Cfrac%7B1%7D%7B2%7D%5Cmu_i%5E2-%5Cfrac%7B1%7D%7B12%7D%5Cmu_i%5E4%5Cright%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2827%29&bg=ffffff&fg=000000&s=0&c=20201002)
Finally, we take the continuum limit, in which we label the field at each site by the {-dimensional} vector 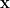 (i.e.,
(i.e.,  and
and 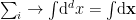 ), and obtain the path-integral measure
), and obtain the path-integral measure
![\displaystyle \left[\left(\frac{2}{\pi}\right)^N\!\mathrm{det}J^{-1}\right]^{1/2}\!e^{-\frac{1}{2}J^{-1}_{ij}h^ih^j}\!\int\!\mathrm{d}^N\mu \;\longrightarrow\;\mathcal{N}\!\int\!\mathcal{D}\mu~. \ \ \ \ \ (28)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cleft%28%5Cfrac%7B2%7D%7B%5Cpi%7D%5Cright%29%5EN%5C%21%5Cmathrm%7Bdet%7DJ%5E%7B-1%7D%5Cright%5D%5E%7B1%2F2%7D%5C%21e%5E%7B-%5Cfrac%7B1%7D%7B2%7DJ%5E%7B-1%7D_%7Bij%7Dh%5Eih%5Ej%7D%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5EN%5Cmu+%5C%3B%5Clongrightarrow%5C%3B%5Cmathcal%7BN%7D%5C%21%5Cint%5C%21%5Cmathcal%7BD%7D%5Cmu%7E.+%5C+%5C+%5C+%5C+%5C+%2828%29&bg=ffffff&fg=000000&s=0&c=20201002)
Thus the continuum field theory for the Ising model is
![\displaystyle \begin{aligned} Z\approx\mathcal{N}\!\int\!\mathcal{D}\mu\exp\bigg\{\!&-\frac{1}{2}\int\!\mathrm{d}\mathbf{x}\mathrm{d}\mathbf{y}\,\mu(\mathbf{x})J^{-1}(\mathbf{x}-\mathbf{y})\big[\mu(\mathbf{y})-h\big]\\ &+\frac{1}{2}\int\!\mathrm{d}\mathbf{x}\left[\mu(\mathbf{x})^2-\frac{1}{6}\mu(\mathbf{x})^4\right]\bigg\}~, \end{aligned} \ \ \ \ \ (29)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+Z%5Capprox%5Cmathcal%7BN%7D%5C%21%5Cint%5C%21%5Cmathcal%7BD%7D%5Cmu%5Cexp%5Cbigg%5C%7B%5C%21%26-%5Cfrac%7B1%7D%7B2%7D%5Cint%5C%21%5Cmathrm%7Bd%7D%5Cmathbf%7Bx%7D%5Cmathrm%7Bd%7D%5Cmathbf%7By%7D%5C%2C%5Cmu%28%5Cmathbf%7Bx%7D%29J%5E%7B-1%7D%28%5Cmathbf%7Bx%7D-%5Cmathbf%7By%7D%29%5Cbig%5B%5Cmu%28%5Cmathbf%7By%7D%29-h%5Cbig%5D%5C%5C+%26%2B%5Cfrac%7B1%7D%7B2%7D%5Cint%5C%21%5Cmathrm%7Bd%7D%5Cmathbf%7Bx%7D%5Cleft%5B%5Cmu%28%5Cmathbf%7Bx%7D%29%5E2-%5Cfrac%7B1%7D%7B6%7D%5Cmu%28%5Cmathbf%7Bx%7D%29%5E4%5Cright%5D%5Cbigg%5C%7D%7E%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2829%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  , since the external magnetic field is the same for all lattice sites, cf. the definition of
, since the external magnetic field is the same for all lattice sites, cf. the definition of  below (1).
below (1).
In obtaining (29), I haven’t made any assumptions about the form of the coupling matrix  , except that it be a symmetric invertible matrix, with no self-interactions (). Typically however, we’re interested in the case in which the hamiltonian (1) includes only nearest-neighbor interactions — as we eventually specified in our lattice model, cf. (10) — and we’d like to preserve this notion of locality in the field theory. To do this, we take
, except that it be a symmetric invertible matrix, with no self-interactions (). Typically however, we’re interested in the case in which the hamiltonian (1) includes only nearest-neighbor interactions — as we eventually specified in our lattice model, cf. (10) — and we’d like to preserve this notion of locality in the field theory. To do this, we take  and Taylor expand the field
and Taylor expand the field 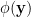 around :
around :
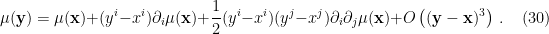
That is, we view  as mediating interactions between fields at infinitesimally separated points in space, with increasingly non-local (i.e., higher-derivative) terms suppressed by powers of the separation. Upon substituting this expansion into (29), and working to second-order in this local expansion, one obtains a partition function of the form
as mediating interactions between fields at infinitesimally separated points in space, with increasingly non-local (i.e., higher-derivative) terms suppressed by powers of the separation. Upon substituting this expansion into (29), and working to second-order in this local expansion, one obtains a partition function of the form
![\displaystyle Z\approx\mathcal{N}\!\int\!\mathcal{D}\mu\,e^{-S[\mu]}~, \ \ \ \ \ (31)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5Capprox%5Cmathcal%7BN%7D%5C%21%5Cint%5C%21%5Cmathcal%7BD%7D%5Cmu%5C%2Ce%5E%7B-S%5B%5Cmu%5D%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2831%29&bg=ffffff&fg=000000&s=0&c=20201002)
with
![\displaystyle S[\mu]=\int\!\mathrm{d}^d\mathbf{x}\left[\frac{1}{2}\kappa(\nabla\mu)^2-h\mu+\frac{1}{2}\tilde r\mu^2+\frac{\tilde g}{4!}\mu^4\right]~, \ \ \ \ \ (32)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%5B%5Cmu%5D%3D%5Cint%5C%21%5Cmathrm%7Bd%7D%5Ed%5Cmathbf%7Bx%7D%5Cleft%5B%5Cfrac%7B1%7D%7B2%7D%5Ckappa%28%5Cnabla%5Cmu%29%5E2-h%5Cmu%2B%5Cfrac%7B1%7D%7B2%7D%5Ctilde+r%5Cmu%5E2%2B%5Cfrac%7B%5Ctilde+g%7D%7B4%21%7D%5Cmu%5E4%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2832%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the coefficients  ,
,  , and
, and 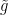 are some (analytic) functions of the physical parameters, and can be expressed in terms of the zero modes of the inverse coupling matrix. I’m not going to go through the details of that computation here, since a great exposition is already available in the answer to this post on Stack Exchange (note however that they do not keep the linear
are some (analytic) functions of the physical parameters, and can be expressed in terms of the zero modes of the inverse coupling matrix. I’m not going to go through the details of that computation here, since a great exposition is already available in the answer to this post on Stack Exchange (note however that they do not keep the linear 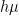 term).
term).
The main lesson of this field-theoretic exercise is that MFT is nothing more than the leading saddle point of (31). Denoting the minimum 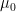 , and expanding the action to second order in the fluctuations
, and expanding the action to second order in the fluctuations 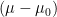 , we have
, we have
![\displaystyle Z\approx\mathcal{N} e^{-S[\mu_0]}\int\!\mathcal{D}\mu\,e^{-\frac{1}{2}(\mu-\mu_0)^2S''[\mu_0]}~, \ \ \ \ \ (33)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5Capprox%5Cmathcal%7BN%7D+e%5E%7B-S%5B%5Cmu_0%5D%7D%5Cint%5C%21%5Cmathcal%7BD%7D%5Cmu%5C%2Ce%5E%7B-%5Cfrac%7B1%7D%7B2%7D%28%5Cmu-%5Cmu_0%29%5E2S%27%27%5B%5Cmu_0%5D%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2833%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the prime denotes variation with respect to  , and the linear term has vanished by definition, i.e., is given by
, and the linear term has vanished by definition, i.e., is given by

where we have applied integration by parts and assumed that the field vanishes at infinity. If we then keep only the leading-order saddle point, the partition function is given entirely by the prefactor
![\displaystyle Z\approx\mathcal{N} e^{-S[\mu_0]} \quad\mathrm{with}\quad S[\mu_0]=\int\!\mathrm{d}^d\mathbf{x}\left(\tilde r\mu_0^2+\frac{\tilde g}{8}\mu_0^4-\frac{3}{2}h\mu_0\right)~, \ \ \ \ \ (35)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5Capprox%5Cmathcal%7BN%7D+e%5E%7B-S%5B%5Cmu_0%5D%7D+%5Cquad%5Cmathrm%7Bwith%7D%5Cquad+S%5B%5Cmu_0%5D%3D%5Cint%5C%21%5Cmathrm%7Bd%7D%5Ed%5Cmathbf%7Bx%7D%5Cleft%28%5Ctilde+r%5Cmu_0%5E2%2B%5Cfrac%7B%5Ctilde+g%7D%7B8%7D%5Cmu_0%5E4-%5Cfrac%7B3%7D%7B2%7Dh%5Cmu_0%5Cright%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%2835%29&bg=ffffff&fg=000000&s=0&c=20201002)
so that the free energy is

where the subscript “sp” stands for “saddle point”, and we have dropped the non-dynamical  term. In the second equality, we have simply extracted the factor of from by defining
term. In the second equality, we have simply extracted the factor of from by defining  (cf. the absorption of into the coefficients
(cf. the absorption of into the coefficients  in (18), and the definition of below (22)), and defined
in (18), and the definition of below (22)), and defined 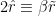 ,
, 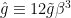 , and
, and 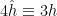 . For , this is formally identical to obtained above, cf. (16)! (By this point the two theories are technically different, though Kopietz et al. [1] do give an argument as to how one might match the coefficients; otherwise one can compute them explicitly via Fourier transform as mentioned above).
. For , this is formally identical to obtained above, cf. (16)! (By this point the two theories are technically different, though Kopietz et al. [1] do give an argument as to how one might match the coefficients; otherwise one can compute them explicitly via Fourier transform as mentioned above).
Now suppose we kept the leading correction to the MFT result, given by the quadratic term in the path integral (33). For ![{S''[\mu_0]}](https://s0.wp.com/latex.php?latex=%7BS%27%27%5B%5Cmu_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we have the operator
, we have the operator

where  . Substituting this into (33) and doing the Gaussian integral, one finds that the contribution from this term is given by the sum of the eigenvalues of the operator
. Substituting this into (33) and doing the Gaussian integral, one finds that the contribution from this term is given by the sum of the eigenvalues of the operator  . I’m not going to go through this in detail, since this post is getting long-winded, and McGreevy’s notes already do a great job. The result is an additional contribution to the free energy that shifts the location of the critical point. Whether or not these higher-order corrections are important depends not only on the size of the fluctuations, but also on the spatial dimension of the system. It turns out that for systems in the Ising universality class (that is, systems whose critical points are characterized by the same set of critical exponents), the MFT result is good enough in
. I’m not going to go through this in detail, since this post is getting long-winded, and McGreevy’s notes already do a great job. The result is an additional contribution to the free energy that shifts the location of the critical point. Whether or not these higher-order corrections are important depends not only on the size of the fluctuations, but also on the spatial dimension of the system. It turns out that for systems in the Ising universality class (that is, systems whose critical points are characterized by the same set of critical exponents), the MFT result is good enough in  , but the fluctuations diverge in
, but the fluctuations diverge in  and hence render its conclusions invalid. We’ll give a better explanation for this dimensional-dependent validity below.
and hence render its conclusions invalid. We’ll give a better explanation for this dimensional-dependent validity below.
There’s another way to see the breakdown of MFT at the critical point in a manner that makes more transparent the precise role of the higher-order terms in the expansion, via the renormalization group. Suppose we’d included all higher-order terms in (32)—that is, all terms consistent with the symmetries of the problem (rotation & translation invariance, and  symmetry if ). The result is called the Ginzburg-Landau action, after the eponymous authors who first used it to study systems near critical points. Now observe that the field has mass dimension
symmetry if ). The result is called the Ginzburg-Landau action, after the eponymous authors who first used it to study systems near critical points. Now observe that the field has mass dimension 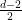 , so the squared mass has dimension 2, the quartic coupling has dimension
, so the squared mass has dimension 2, the quartic coupling has dimension 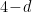 , a sextic coupling would have dimension
, a sextic coupling would have dimension  , and so on. Recall that a coupling is relevant if its mass dimension
, and so on. Recall that a coupling is relevant if its mass dimension  (since the dimensionless coupling carries a factor of
(since the dimensionless coupling carries a factor of  , e.g.,
, e.g., 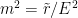 ), irrelevant if
), irrelevant if 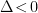 (since it runs like
(since it runs like 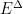 ), and marginal if
), and marginal if  . Thus we see that the quadratic term is always relevant, and that higher-order corrections are increasingly suppressed under RG in a dimension-dependent manner.
. Thus we see that the quadratic term is always relevant, and that higher-order corrections are increasingly suppressed under RG in a dimension-dependent manner.
So, a more sophisticated alternative to our particular MFT attempt above — where we kept the quartic  term in the saddle point — is to compute the Gaussian path integral consisting of only the quadratic contribution, and treat the quartic and higher terms perturbatively. (As these originally arose from higher-order terms in the Taylor expansion, this is morally in line with simply taking
term in the saddle point — is to compute the Gaussian path integral consisting of only the quadratic contribution, and treat the quartic and higher terms perturbatively. (As these originally arose from higher-order terms in the Taylor expansion, this is morally in line with simply taking 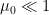 in the MFT result
in the MFT result  ). Treating the action as a Gaussian integral also allows us to obtain a simple expression for the two-point correlator that captures the limiting behaviour in which we’re primarily interested. That is, tying all this back to the information theory / neural network connections alluded in the introduction, we’re ultimately interested in understanding the propagation of information near the critical point, so understanding how correlation functions behave in the leading-order / MFT / saddle point approximation — and how perturbative corrections from fluctuations might affect this — is of prime importance.
). Treating the action as a Gaussian integral also allows us to obtain a simple expression for the two-point correlator that captures the limiting behaviour in which we’re primarily interested. That is, tying all this back to the information theory / neural network connections alluded in the introduction, we’re ultimately interested in understanding the propagation of information near the critical point, so understanding how correlation functions behave in the leading-order / MFT / saddle point approximation — and how perturbative corrections from fluctuations might affect this — is of prime importance.
We thus consider the partition function (31), with the quadratic action
![\displaystyle S[\mu]=\int\!\mathrm{d}^d\mathbf{x}\left[\frac{1}{2}(\nabla\mu(\mathbf{x}))^2+\frac{m^2}{2}\mu(\mathbf{x})^2-h\mu(\mathbf{x})\right]~, \ \ \ \ \ (38)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%5B%5Cmu%5D%3D%5Cint%5C%21%5Cmathrm%7Bd%7D%5Ed%5Cmathbf%7Bx%7D%5Cleft%5B%5Cfrac%7B1%7D%7B2%7D%28%5Cnabla%5Cmu%28%5Cmathbf%7Bx%7D%29%29%5E2%2B%5Cfrac%7Bm%5E2%7D%7B2%7D%5Cmu%28%5Cmathbf%7Bx%7D%29%5E2-h%5Cmu%28%5Cmathbf%7Bx%7D%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2838%29&bg=ffffff&fg=000000&s=0&c=20201002)
where we’ve set 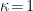 and relabelled the quadratic coefficient
and relabelled the quadratic coefficient  . Evaluating partition functions of this type is a typical exercise in one’s first QFT course, since the action now resembles that of a free massive scalar field, where
. Evaluating partition functions of this type is a typical exercise in one’s first QFT course, since the action now resembles that of a free massive scalar field, where 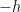 plays the role of the source (normally denoted ). The basic prescription is to Fourier transform to momentum space, where the modes decouple, and then absorb the remaining source-independent term into the overall normalization. The only difference here is that we’re in Euclidean rather than Lorentzian signature, so there’s no issues of convergence; see for example Tong’s statistical field theory notes for a pedagogical exposition. The result is
plays the role of the source (normally denoted ). The basic prescription is to Fourier transform to momentum space, where the modes decouple, and then absorb the remaining source-independent term into the overall normalization. The only difference here is that we’re in Euclidean rather than Lorentzian signature, so there’s no issues of convergence; see for example Tong’s statistical field theory notes for a pedagogical exposition. The result is
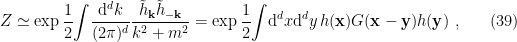
where the position-dependence of the external field  merely serves as a mnemonic, and
merely serves as a mnemonic, and 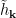 is the same field in momentum space. In the second equality, we’ve simply Fourier transformed back to real space by identifying the propagator
is the same field in momentum space. In the second equality, we’ve simply Fourier transformed back to real space by identifying the propagator

which describes the correlation between the field and  . To see that this is indeed a correlation function, recall that the variance is given by the second cumulant:
. To see that this is indeed a correlation function, recall that the variance is given by the second cumulant:

and thus  is indeed the connected 2-point correlator. (I should mention that in the present case, there’s a special name for this which seems to be preferred by condensed matter theorists: it’s the magnetic susceptibility, defined as the sensitivity of with respect to
is indeed the connected 2-point correlator. (I should mention that in the present case, there’s a special name for this which seems to be preferred by condensed matter theorists: it’s the magnetic susceptibility, defined as the sensitivity of with respect to  ,
,
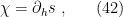
where the connection arises by observing that the magnetization is none other than the mean (i.e., the first cumulant),

But I’ll continue to refer to it as the correlation function, or the connected Green function, since calling it the “susceptibility” obscures its deeper physical and information-theoretic significance. Actually seeing that this is a Green function does however require slightly more work.)
The evaluation of (40) is treated very nicely in the aforementioned notes by Tong. In brief, we proceed by defining a length scale  , and use the identity
, and use the identity

to massage the integral into the following form:

which is obtained by completing the square in the exponential and performing the integral over  ; we’ve also used rotation invariance with
; we’ve also used rotation invariance with  (not to be confused with the old name for the quadratic coefficient).
(not to be confused with the old name for the quadratic coefficient).
As will shortly become apparent,  is the correlation length that determines the size of fluctuations, and hence the spatial structure of correlations. Since we’re primarily interested in the limiting cases where
is the correlation length that determines the size of fluctuations, and hence the spatial structure of correlations. Since we’re primarily interested in the limiting cases where  and
and  , it is more illuminating to evaluate the integral via saddle point, rather than to preserve the exact form (which, as it turns out, can be expressed as a Bessel function). We thus exponentiate the
, it is more illuminating to evaluate the integral via saddle point, rather than to preserve the exact form (which, as it turns out, can be expressed as a Bessel function). We thus exponentiate the 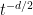 factor to write
factor to write

so that we have, to second order,

where the saddle point 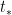 is given by
is given by

Substituting these case values into (47), we find the following limiting behaviour for the correlation function:

Recalling that  near the critical point, we see that the correlation length diverges as
near the critical point, we see that the correlation length diverges as

as the system approaches criticality. This means that at the critical point, we are always in the regime , and hence the correlator exhibits a power law divergence. Another way to say this is that there is no longer any length scale in the problem (since that role was played by , which has gone to infinity). This is why the divergence of the correlator at criticality must be a power law: any other function would require a length scale on dimensional grounds.
In the previous MFT treatment, we mentioned that fluctuations can change the results. From the RG perspective, this is because the quadratic coupling (which determines the location of the critical point) may be adjusted in the renormalization process as we integrate out UV modes. (In fact, we saw an explicit example of this in our post on deep learning and the renormalization group). The lower the dimension, the more relevant operators we need to take into account; in particular, all operators are relevant in , so the saddle point approximation is exceedingly poor. In contrast, as the dimension increases, more and more operators are suppressed under RG flow. In the lattice picture, we can understand the fact that MFT gets more accurate in higher dimensions by noting that more dimensions means more neighbors, and hence approximating the degrees of freedom by the mean field is more likely to be accurate.
Finally, let us return to the comment we made at the beginning of this post, namely that the correlation length diverges at a critical point. This is another way of understanding the breakdown of MFT, since a divergent correlation length implies that fluctuations on all scales are important (and hence we neglect them at our peril). Explicitly, MFT (broadly interpreted) is valid when the fluctuations are much smaller than the mean or background field around which they’re fluctuating, i.e.,  . Tong offers a clean way to see the dimensional dependence explicitly: simply integrate these expectation values over a ball of radius and compare the ratio
. Tong offers a clean way to see the dimensional dependence explicitly: simply integrate these expectation values over a ball of radius and compare the ratio
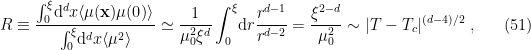
where  is the mean field from above, and in the last step we have used the scaling behaviours of
is the mean field from above, and in the last step we have used the scaling behaviours of  and
and  (the latter can be obtained by minimizing the quartic result for (16)). Upon demanding that this ratio be much less than unity, we see that the MFT results (for the Ising universality class) are only trustworthy in
(the latter can be obtained by minimizing the quartic result for (16)). Upon demanding that this ratio be much less than unity, we see that the MFT results (for the Ising universality class) are only trustworthy in  dimensions. (The case
dimensions. (The case 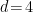 actually requires a more careful RG treatment due to the logarithmic divergence; see Tong’s notes for more details).
actually requires a more careful RG treatment due to the logarithmic divergence; see Tong’s notes for more details).
To summarize: MFT is a useful approximation method that averages over interactions and enables one to obtain closed-form expressions of otherwise intractable partition functions. It is tantamount to the saddle point approximation, and — in the context of RG — may be qualitatively altered by any relevant higher-order terms. While these corrections can potentially shift the location of the critical point however, the basic fact that the correlation function diverges at criticality remains unchanged. As we’ll see in part 2, it is this feature that makes phase transitions interesting from a computational perspective, since it means that the propagation of information at this point is especially stable.
References
1. P. Kopietz, L. Bartosch, and F. Schütz, “Mean-field Theory and the Gaussian Approximation,” Lect. Notes Phys. 798 (2010).

