Lately, I’ve been spending a lot of time exploring the surprisingly rich mathematics at the intersection of physics, information theory, and machine learning. Among other things, this has led me to a new appreciation of cumulants. At face value, these are just an alternative to the moments that characterize a given probability distribution function, and aren’t particularly exciting. Except they show up all over statistical thermodynamics, quantum field theory, and the structure of deep neural networks, so of course I couldn’t resist trying to better understand the information-theoretic connections to which this seems to allude. In the first part of this two-post sequence, I’ll introduce them in the context of theoretical physics, and then turn to their appearance in deep learning in the next post, where I’ll dive into the parallel with the renormalization group.
The relation between these probabilistic notions and statistical physics is reasonably well-known, though the literature on this particular point unfortunately tends to be slightly sloppy. Loosely speaking, the partition function corresponds to the moment generating function, and the (Helmholtz) free energy corresponds to the cumulant generating function. By way of introduction, let’s make this identification precise.
The moment generating function for a random variable  is
is

where  denotes the expectation value for the corresponding distribution. (As a technical caveat: in some cases, the moments — and correspondingly,
denotes the expectation value for the corresponding distribution. (As a technical caveat: in some cases, the moments — and correspondingly,  — may not exist, in which case one can resort to the characteristic function instead). By series expanding the exponential, we have
— may not exist, in which case one can resort to the characteristic function instead). By series expanding the exponential, we have

were  is the
is the  moment, which we can obtain by taking
moment, which we can obtain by taking  derivatives and setting
derivatives and setting  , i.e.,
, i.e.,
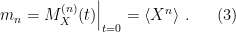
However, it is often more convenient to work with cumulants instead of moments (e.g., for independent random variables, the cumulant of the sum is the sum of the cumulants, thanks to the log). These are uniquely specified by the moments, and vice versa—unsurprisingly, since the cumulant generating function is just the log of the moment generating function:

where  is the cumulant, which we again obtain by differentiating times and setting
is the cumulant, which we again obtain by differentiating times and setting  :
:

Note however that is not simply the log of !
Now, to make contact with thermodynamics, consider the case in which is the energy of the canonical ensemble. The probability of a given energy eigenstate 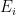 is
is
![\displaystyle p_i\equiv p(E_i)=\frac{1}{Z[\beta]}e^{-\beta E_i}~, \quad\quad \sum\nolimits_ip_i=1~. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p_i%5Cequiv+p%28E_i%29%3D%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7De%5E%7B-%5Cbeta+E_i%7D%7E%2C+%5Cquad%5Cquad+%5Csum%5Cnolimits_ip_i%3D1%7E.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
The moment generating function for energy is then
![\displaystyle M_E(t)=\langle e^{tE}\rangle=\sum_i p(E_i)e^{tE_i} =\frac{1}{Z[\beta]}\sum_ie^{-(\beta\!-\!t)E_i} =\frac{Z[\beta-t]}{Z[\beta]}~. \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_E%28t%29%3D%5Clangle+e%5E%7BtE%7D%5Crangle%3D%5Csum_i+p%28E_i%29e%5E%7BtE_i%7D+%3D%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7D%5Csum_ie%5E%7B-%28%5Cbeta%5C%21-%5C%21t%29E_i%7D+%3D%5Cfrac%7BZ%5B%5Cbeta-t%5D%7D%7BZ%5B%5Cbeta%5D%7D%7E.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
Thus we see that the partition function ![{Z[\beta]}](https://s0.wp.com/latex.php?latex=%7BZ%5B%5Cbeta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is not the moment generating function, but there’s clearly a close relationship between the two. Rather, the precise statement is that the moment generating function
is not the moment generating function, but there’s clearly a close relationship between the two. Rather, the precise statement is that the moment generating function  is the ratio of two partition functions at inverse temperatures
is the ratio of two partition functions at inverse temperatures  and
and  , respectively. We can gain further insight by considering the moments themselves, which are — by definition (3) — simply expectation values of powers of the energy:
, respectively. We can gain further insight by considering the moments themselves, which are — by definition (3) — simply expectation values of powers of the energy:
![\displaystyle \langle E^n\rangle=M^{(n)}(t)\Big|_{t=0} =\frac{1}{Z[\beta]}\frac{\partial^n}{\partial t^n}Z[\beta\!-\!t]\bigg|_{t=0} =(-1)^n\frac{Z^{(n)}[\beta\!-\!t]}{Z[\beta]}\bigg|_{t=0} =(-1)^n\frac{Z^{(n)}[\beta]}{Z[\beta]}~. \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+E%5En%5Crangle%3DM%5E%7B%28n%29%7D%28t%29%5CBig%7C_%7Bt%3D0%7D+%3D%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7D%5Cfrac%7B%5Cpartial%5En%7D%7B%5Cpartial+t%5En%7DZ%5B%5Cbeta%5C%21-%5C%21t%5D%5Cbigg%7C_%7Bt%3D0%7D+%3D%28-1%29%5En%5Cfrac%7BZ%5E%7B%28n%29%7D%5B%5Cbeta%5C%21-%5C%21t%5D%7D%7BZ%5B%5Cbeta%5D%7D%5Cbigg%7C_%7Bt%3D0%7D+%3D%28-1%29%5En%5Cfrac%7BZ%5E%7B%28n%29%7D%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D%7E.+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
Note that derivatives of the partition function with respect to  have, at , become derivatives with respect to inverse temperature (obviously, this little slight of hand doesn’t work for all functions; simple counter example:
have, at , become derivatives with respect to inverse temperature (obviously, this little slight of hand doesn’t work for all functions; simple counter example: 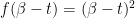 ). Of course, this is simply a more formal expression for the usual thermodynamic expectation values. The first moment of energy, for example, is
). Of course, this is simply a more formal expression for the usual thermodynamic expectation values. The first moment of energy, for example, is
![\displaystyle \langle E\rangle= -\frac{1}{Z[\beta]}\frac{\partial Z[\beta]}{\partial\beta} =\frac{1}{Z[\beta]}\sum_i E_ie^{-\beta E_i} =\sum_i E_i\,p_i~, \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+E%5Crangle%3D+-%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7D%5Cfrac%7B%5Cpartial+Z%5B%5Cbeta%5D%7D%7B%5Cpartial%5Cbeta%7D+%3D%5Cfrac%7B1%7D%7BZ%5B%5Cbeta%5D%7D%5Csum_i+E_ie%5E%7B-%5Cbeta+E_i%7D+%3D%5Csum_i+E_i%5C%2Cp_i%7E%2C+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=0&c=20201002)
which is the ensemble average. At a more abstract level however, (8) expresses the fact that the average energy — appropriately normalized — is canonically conjugate to . That is, recall that derivatives of the action are conjugate variables to those with respect to which we differentiate. In classical mechanics for example, energy is conjugate to time. Upon Wick rotating to Euclidean signature, the trajectories become thermal circles with period . Accordingly, the energetic moments can be thought of as characterizing the dynamics of the ensemble in imaginary time.
Now, it follows from (7) that the cumulant generating function (4) is
![\displaystyle K_E(t)=\ln\langle e^{tE}\rangle=\ln Z[\beta\!-\!t]-\ln Z[\beta]~. \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+K_E%28t%29%3D%5Cln%5Clangle+e%5E%7BtE%7D%5Crangle%3D%5Cln+Z%5B%5Cbeta%5C%21-%5C%21t%5D-%5Cln+Z%5B%5Cbeta%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
While the cumulant does not admit a nice post-derivative expression as in (8) (though I suppose one could write it in terms of Bell polynomials if we drop the adjective), it is simple enough to compute the first few and see that, as expected, the first cumulant is the mean, the second is the variance, and the third is the third central moment:
![\displaystyle \begin{aligned} K^{(1)}(t)\big|_{t=0}&=-\frac{Z'[\beta]}{Z[\beta]}=\langle E\rangle~,\\ K^{(2)}(t)\big|_{t=0}&=\frac{Z''[\beta]}{Z[\beta]}-\left(\frac{Z'[\beta]}{Z[\beta]}\right)^2=\langle E^2\rangle-\langle E\rangle^2\\ K^{(3)}(t)\big|_{t=0}&=-2\left(\frac{Z'[\beta]}{Z[\beta]}\right)^3+3\frac{Z'[\beta]Z''[\beta]}{Z[\beta]^2}-\frac{Z^{(3)}[\beta]}{Z[\beta]}\\ &=-2\langle E\rangle^3+3\langle E\rangle\langle E^2\rangle-\langle E^3\rangle =-\left\langle\left( E-\langle E\rangle\right)^3\right\rangle~. \end{aligned} \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+K%5E%7B%281%29%7D%28t%29%5Cbig%7C_%7Bt%3D0%7D%26%3D-%5Cfrac%7BZ%27%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D%3D%5Clangle+E%5Crangle%7E%2C%5C%5C+K%5E%7B%282%29%7D%28t%29%5Cbig%7C_%7Bt%3D0%7D%26%3D%5Cfrac%7BZ%27%27%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D-%5Cleft%28%5Cfrac%7BZ%27%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D%5Cright%29%5E2%3D%5Clangle+E%5E2%5Crangle-%5Clangle+E%5Crangle%5E2%5C%5C+K%5E%7B%283%29%7D%28t%29%5Cbig%7C_%7Bt%3D0%7D%26%3D-2%5Cleft%28%5Cfrac%7BZ%27%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D%5Cright%29%5E3%2B3%5Cfrac%7BZ%27%5B%5Cbeta%5DZ%27%27%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%5E2%7D-%5Cfrac%7BZ%5E%7B%283%29%7D%5B%5Cbeta%5D%7D%7BZ%5B%5Cbeta%5D%7D%5C%5C+%26%3D-2%5Clangle+E%5Crangle%5E3%2B3%5Clangle+E%5Crangle%5Clangle+E%5E2%5Crangle-%5Clangle+E%5E3%5Crangle+%3D-%5Cleft%5Clangle%5Cleft%28+E-%5Clangle+E%5Crangle%5Cright%29%5E3%5Cright%5Crangle%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the prime denotes the derivative with respect to . Note that since the second term in the generating function (10) is independent of , the normalization drops out when computing the cumulants, so we would have obtained the same results had we worked directly with the partition function and taken derivatives with respect to . That is, we could define
![\displaystyle K_E(\beta)\equiv-\ln Z[\beta] \qquad\implies\qquad \kappa_n=(-1)^{n-1}K_E^{(n)}(\beta)~, \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+K_E%28%5Cbeta%29%5Cequiv-%5Cln+Z%5B%5Cbeta%5D+%5Cqquad%5Cimplies%5Cqquad+%5Ckappa_n%3D%28-1%29%5E%7Bn-1%7DK_E%5E%7B%28n%29%7D%28%5Cbeta%29%7E%2C+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=0&c=20201002)
where, in contrast to (5), we don’t need to set anything to zero after differentiating. This expression for the cumulant generating function will feature more prominently when we discuss correlation functions below.
So, what does the cumulant generating function have to do with the (Helmholtz) free energy, ![{F[\beta]=-\beta^{-1}\ln Z[\beta]}](https://s0.wp.com/latex.php?latex=%7BF%5B%5Cbeta%5D%3D-%5Cbeta%5E%7B-1%7D%5Cln+Z%5B%5Cbeta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ? Given the form (12), one sees that they’re essentially one and the same, up to a factor of . And indeed the free energy is a sort of “generating function” in the sense that it allows one to compute any desired thermodynamic quantity of the system. The entropy, for example, is
? Given the form (12), one sees that they’re essentially one and the same, up to a factor of . And indeed the free energy is a sort of “generating function” in the sense that it allows one to compute any desired thermodynamic quantity of the system. The entropy, for example, is

where  is the Boltzmann distribution (6). However, the factor of
is the Boltzmann distribution (6). However, the factor of  in the definition of free energy technically prevents a direct identification with the cumulant generating function above. Thus it is really the log of the partition function itself — i.e., the dimensionless free energy
in the definition of free energy technically prevents a direct identification with the cumulant generating function above. Thus it is really the log of the partition function itself — i.e., the dimensionless free energy  — that serves as the cumulant generating function for the distribution. We’ll return to this idea momentarily, cf. (21) below.
— that serves as the cumulant generating function for the distribution. We’ll return to this idea momentarily, cf. (21) below.
So much for definitions; what does it all mean? It turns out that in addition to encoding correlations, cumulants are intimately related to connectedness (in the sense of connected graphs), which underlies their appearance in QFT. Consider, for concreteness, a real scalar field 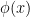 in 4 spacetime dimensions. As every student knows, the partition function
in 4 spacetime dimensions. As every student knows, the partition function
![\displaystyle Z[J]=\mathcal{N}\int\mathcal{D}\phi\,\exp\left\{i\!\int\!\mathrm{d}^dx\left[\mathcal{L}(\phi,\partial\phi)+J(x)\phi(x)\right]\right\} \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Z%5BJ%5D%3D%5Cmathcal%7BN%7D%5Cint%5Cmathcal%7BD%7D%5Cphi%5C%2C%5Cexp%5Cleft%5C%7Bi%5C%21%5Cint%5C%21%5Cmathrm%7Bd%7D%5Edx%5Cleft%5B%5Cmathcal%7BL%7D%28%5Cphi%2C%5Cpartial%5Cphi%29%2BJ%28x%29%5Cphi%28x%29%5Cright%5D%5Cright%5C%7D+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
is the generating function for the -point correlator or Green function  :
:
![\displaystyle G^{(n)}(x_1,\ldots,x_n)=\frac{1}{i^n}\frac{\delta^nZ[J]}{\delta J(x_1)\ldots\delta J(x_n)}\bigg|_{J=0}~, \ \ \ \ \ (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G%5E%7B%28n%29%7D%28x_1%2C%5Cldots%2Cx_n%29%3D%5Cfrac%7B1%7D%7Bi%5En%7D%5Cfrac%7B%5Cdelta%5EnZ%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cldots%5Cdelta+J%28x_n%29%7D%5Cbigg%7C_%7BJ%3D0%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the normalization 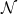 is fixed by demanding that in the absence of sources, we should recover the vacuum expectation value, i.e.,
is fixed by demanding that in the absence of sources, we should recover the vacuum expectation value, i.e., ![{Z[0]=\langle0|0\rangle=1}](https://s0.wp.com/latex.php?latex=%7BZ%5B0%5D%3D%5Clangle0%7C0%5Crangle%3D1%7D&bg=ffffff&fg=000000&s=0&c=20201002) . In the language of Feynman diagrams, the Green function contains all possible graphs — both connected and disconnected — that contribute to the corresponding transition amplitude. For example, the 4-point correlator of
. In the language of Feynman diagrams, the Green function contains all possible graphs — both connected and disconnected — that contribute to the corresponding transition amplitude. For example, the 4-point correlator of  theory contains, at first order in the coupling, a disconnected graph consisting of two Feynman propagators, another disconnected graph consisting of a Feynman propagator and a 1-loop diagram, and an irreducible graph consisting of a single 4-point vertex. But only the last of these contributes to the scattering process, so it’s often more useful to work with the generating function for connected diagrams only,
theory contains, at first order in the coupling, a disconnected graph consisting of two Feynman propagators, another disconnected graph consisting of a Feynman propagator and a 1-loop diagram, and an irreducible graph consisting of a single 4-point vertex. But only the last of these contributes to the scattering process, so it’s often more useful to work with the generating function for connected diagrams only,
![\displaystyle W[J]=-i\ln Z[J]~, \ \ \ \ \ (16)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+W%5BJ%5D%3D-i%5Cln+Z%5BJ%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2816%29&bg=ffffff&fg=000000&s=0&c=20201002)
from which we obtain the connected Green function 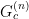 :
:
![\displaystyle G_c^{(n)}(x_1,\ldots,x_n)=\frac{1}{i^{n-1}}\frac{\delta^nW[J]}{\delta J(x_1)\ldots\delta J(x_n)}\bigg|_{J=0}~. \ \ \ \ \ (17)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G_c%5E%7B%28n%29%7D%28x_1%2C%5Cldots%2Cx_n%29%3D%5Cfrac%7B1%7D%7Bi%5E%7Bn-1%7D%7D%5Cfrac%7B%5Cdelta%5EnW%5BJ%5D%7D%7B%5Cdelta+J%28x_1%29%5Cldots%5Cdelta+J%28x_n%29%7D%5Cbigg%7C_%7BJ%3D0%7D%7E.+%5C+%5C+%5C+%5C+%5C+%2817%29&bg=ffffff&fg=000000&s=0&c=20201002)
The fact that the generating functions for connected vs. disconnected diagrams are related by an exponential, that is, ![{Z[J]=\exp{i W[J]}}](https://s0.wp.com/latex.php?latex=%7BZ%5BJ%5D%3D%5Cexp%7Bi+W%5BJ%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , is not obvious at first glance, but it is a basic exercise in one’s first QFT course to show that the coefficients of various diagrams indeed work out correctly by simply Taylor expanding the exponential
, is not obvious at first glance, but it is a basic exercise in one’s first QFT course to show that the coefficients of various diagrams indeed work out correctly by simply Taylor expanding the exponential 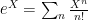 . In the example of theory above, the only first-order diagram that contributes to the connected correlator is the 4-point vertex. More generally, one can decompose
. In the example of theory above, the only first-order diagram that contributes to the connected correlator is the 4-point vertex. More generally, one can decompose  into plus products of
into plus products of 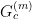 with
with 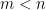 . The factor of
. The factor of 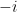 in (16) goes away in Euclidean signature, whereupon we see that
in (16) goes away in Euclidean signature, whereupon we see that ![{Z[J]}](https://s0.wp.com/latex.php?latex=%7BZ%5BJ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is analogous to — and hence plays the role of the moment generating function — while
is analogous to — and hence plays the role of the moment generating function — while ![{W[J]}](https://s0.wp.com/latex.php?latex=%7BW%5BJ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is analogous to
is analogous to ![{\beta F[\beta]}](https://s0.wp.com/latex.php?latex=%7B%5Cbeta+F%5B%5Cbeta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) — and hence plays the role of the cumulant generating function in the form (12).
— and hence plays the role of the cumulant generating function in the form (12).
Thus, the cumulant of the field  corresponds to the connected Green function , i.e., the contribution from correlators of all fields only, excluding contributions from lower-order correlators among them. For example, we know from Wick’s theorem that Gaussian correlators factorize, so the corresponding
corresponds to the connected Green function , i.e., the contribution from correlators of all fields only, excluding contributions from lower-order correlators among them. For example, we know from Wick’s theorem that Gaussian correlators factorize, so the corresponding  -point correlator
-point correlator 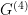 becomes
becomes

What this means is that there are no interactions among all four fields that aren’t already explained by interactions among pairs thereof. The probabilistic version of this statement is that for the normal distribution, all cumulants other than  are zero. (For a probabilist’s exposition on the relationship between cumulants and connectivity, see the first of three lectures by Novak and LaCroix [1], which takes a more graph-theoretic approach).
are zero. (For a probabilist’s exposition on the relationship between cumulants and connectivity, see the first of three lectures by Novak and LaCroix [1], which takes a more graph-theoretic approach).
There’s one more important function that deserves mention here: the final member of the triumvirate of generating functions in QFT, namely the effective action ![{\Gamma[\phi]}](https://s0.wp.com/latex.php?latex=%7B%5CGamma%5B%5Cphi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , defined as the Legendre transform of :
, defined as the Legendre transform of :
![\displaystyle \Gamma[\phi]=W[J]-\int\!\mathrm{d} x\,J(x)\phi(x)~. \ \ \ \ \ (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CGamma%5B%5Cphi%5D%3DW%5BJ%5D-%5Cint%5C%21%5Cmathrm%7Bd%7D+x%5C%2CJ%28x%29%5Cphi%28x%29%7E.+%5C+%5C+%5C+%5C+%5C+%2819%29&bg=ffffff&fg=000000&s=0&c=20201002)
The Legendre transform is typically first encountered in classical mechanics, where it relates the hamiltonian and lagrangian formulations. Geometrically, it translates between a function and its envelope of tangents. More abstractly, it provides a map between the configuration space (here, the sources  ) and the dual vector space (here, the fields ). In other words, and are conjugate pairs in the sense that
) and the dual vector space (here, the fields ). In other words, and are conjugate pairs in the sense that

As an example that connects back to the thermodynamic quantities above: we already saw that  and are conjugate variables by considering the partition function, but the Legendre transform reveals that the free energy and entropy are conjugate pairs as well. This is nicely explained in the lovely pedagogical treatment of the Legendre transform by Zia, Redish, and McKay [2], and also cleans up the disruptive factor of that prevented the identification with the cumulant generating function above. The basic idea is that since we’re working in natural units (i.e.,
and are conjugate variables by considering the partition function, but the Legendre transform reveals that the free energy and entropy are conjugate pairs as well. This is nicely explained in the lovely pedagogical treatment of the Legendre transform by Zia, Redish, and McKay [2], and also cleans up the disruptive factor of that prevented the identification with the cumulant generating function above. The basic idea is that since we’re working in natural units (i.e.,  ), the thermodynamic relation in the form
), the thermodynamic relation in the form  (13) obscures the duality between the properly dimensionless quantities
(13) obscures the duality between the properly dimensionless quantities  and
and 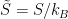 . From this perspective, it is more natural to work with
. From this perspective, it is more natural to work with  instead, in which case we have both an elegant expression for the duality in terms of the Legendre transform, and a precise identification of the dimensionless free energy with the cumulant generating function (12):
instead, in which case we have both an elegant expression for the duality in terms of the Legendre transform, and a precise identification of the dimensionless free energy with the cumulant generating function (12):

Now, back to QFT, in which generates one-particle irreducible (1PI) diagrams. A proper treatment of this would take us too far afield, but can be found in any introductory QFT book, e.g., [3]. The basic idea is that in order to be able to cut a reducible diagram, we need to work at the level of vertices rather than sources (e.g., stripping off external legs, and identifying the bare propagator between irreducible parts). The Legendre transform (19) thus removes the dependence on the sources , and serves as the generator for the vertex functions of , i.e., the fundamental interaction terms. The reason this is called the effective action is that in perturbation theory, contains the classical action as the leading saddle-point, as well as quantum corrections from the higher-order interactions in the coupling expansion.
In information-theoretic terms, the Legendre transform of the cumulant generating function is known as the rate function. This is a core concept in large deviations theory, and I won’t go into details here. Loosely speaking, it quantifies the exponential decay that characterizes rare events. Concretely, let  represent the outcome of some measurement or operation (e.g., a coin toss); then the mean after
represent the outcome of some measurement or operation (e.g., a coin toss); then the mean after  independent trials is
independent trials is
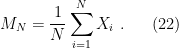
The probability that a given measurement deviates from this mean by some specified amount  is
is

where  is the aforementioned rate function. The formal similarity with the partition function in terms of the effective action,
is the aforementioned rate function. The formal similarity with the partition function in terms of the effective action,  , is obvious, though the precise dictionary between the two languages is not. I suspect that a precise translation between the two languages — physics and information theory — can be made here as well, in which the increasing rarity of events as one moves along the tail of the distribution correspond to increasingly high-order corrections to the quantum effective action, but I haven’t worked this out in detail.
, is obvious, though the precise dictionary between the two languages is not. I suspect that a precise translation between the two languages — physics and information theory — can be made here as well, in which the increasing rarity of events as one moves along the tail of the distribution correspond to increasingly high-order corrections to the quantum effective action, but I haven’t worked this out in detail.
Of course, the above is far from the only place in physics where cumulants are lurking behind the scenes, much less the end of the parallel with information theory more generally. In the next post, I’ll discuss the analogy between deep learning and the renormalization group, and see how Bayesian terminology can provide an underlying language for both.
References
[1] J. Novak and M. LaCroix, “Three lectures on free probability,” arXiv:1205.2097.
[2] R. K. P. Zia, E. F. Redish, and S. R. McKay, “Making sense of the Legendre transform, arXiv:0806.1147.
[3] L. H. Ryder, Quantum Field Theory. Cambridge University Press, 2 ed., 1996.


Thank you for these great posts! The approach you mention here has been extended by Eric Smith here: https://arxiv.org/abs/1102.3938
He has subsequently analyzed the “stochastic effective action” using information geometry and applied it to evolutionary game theory. I’m currently working on applying these ideas to reinforcement learning. I’d love to discuss this more over email with you if you’re interested.
(I just finished my Physics PhD at UCSB and am applying to AI Residencies.)
LikeLike
Thanks for the link JG! I see you’ve also written about Smith’s paper on your blog. I would indeed be very interested in discussing the application of these ideas to reinforcement learning!
LikeLike