In the previous post, we introduced the  -connection, and alluded to a dualistic structure between
-connection, and alluded to a dualistic structure between  and
and 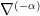 . In particular, the cases
. In particular, the cases 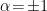 are intimately related to two important families of statistical models, the exponential or e-family with affine connection
are intimately related to two important families of statistical models, the exponential or e-family with affine connection  , and the mixed or m-family with affine connection
, and the mixed or m-family with affine connection 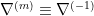 . Hence before turning to general aspects of the dual structure on
. Hence before turning to general aspects of the dual structure on  , it is illuminating to see how these families/connections emerge naturally via an embedding formalism.
, it is illuminating to see how these families/connections emerge naturally via an embedding formalism.
Two embeddings
For concreteness (or rather, to err on the safe side of mathematical rigour), let  be a finite set. As before, an arbitrary model on is a submanifold of
be a finite set. As before, an arbitrary model on is a submanifold of
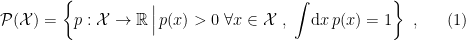
which in turn is a subset of the set of all 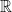 -valued functions on , denoted
-valued functions on , denoted
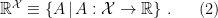
Note that since is finite, the normalization constraint is essentially the imposition that 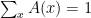 , which implies that
, which implies that 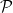 is specifically an open subset of the affine subspace
is specifically an open subset of the affine subspace
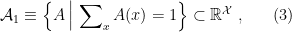
which further implies that the tangent space 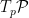 is naturally identified with the linear subspace
is naturally identified with the linear subspace

(One can see this by representing  as an algebraic curve). Vectors
as an algebraic curve). Vectors  , considered as elements of
, considered as elements of  , will be denoted
, will be denoted  . These define the mixture or m-representation of
. These define the mixture or m-representation of  , i.e.,
, i.e.,

As before, the natural basis 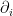 then defines the
then defines the  -affine coordinates
-affine coordinates ![{\xi=[\xi^i]}](https://s0.wp.com/latex.php?latex=%7B%5Cxi%3D%5B%5Cxi%5Ei%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , with
, with 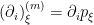 , with respect to which is -flat. The natural connection induced from this affine structure
, with respect to which is -flat. The natural connection induced from this affine structure  is the -connection introduced before, which preserves vectors identically under parallel transport
is the -connection introduced before, which preserves vectors identically under parallel transport  , i.e.,
, i.e.,
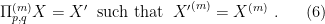
Thus we see that the natural embedding of into  makes the affine structure, and in particular the significance of the -connection, manifest.
makes the affine structure, and in particular the significance of the -connection, manifest.
Now consider the alternative embedding  , and identify with the subset
, and identify with the subset 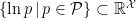 . Elements are then given by applying to the map , whereupon we denote them
. Elements are then given by applying to the map , whereupon we denote them  and call this the exponential or e-representation. In local coordinates, we have
and call this the exponential or e-representation. In local coordinates, we have  . By the chain rule, is then related to as
. By the chain rule, is then related to as

and therefore the tangent space 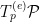 is obtained by modifying the constraint on above to
is obtained by modifying the constraint on above to ![{0=\sum\nolimits_xp(x)A(x)=E_p[A]}](https://s0.wp.com/latex.php?latex=%7B0%3D%5Csum%5Cnolimits_xp%28x%29A%28x%29%3DE_p%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , i.e.,
, i.e.,
![\displaystyle T_p^{(e)}\mathcal{P}\equiv\left\{X^{(e)}\,\Big|\,X\in T_p\mathcal{P}\right\} =\{A\in\mathcal{R}^\mathcal{X}\,|\,E_p[A]=0\}~. \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+T_p%5E%7B%28e%29%7D%5Cmathcal%7BP%7D%5Cequiv%5Cleft%5C%7BX%5E%7B%28e%29%7D%5C%2C%5CBig%7C%5C%2CX%5Cin+T_p%5Cmathcal%7BP%7D%5Cright%5C%7D+%3D%5C%7BA%5Cin%5Cmathcal%7BR%7D%5E%5Cmathcal%7BX%7D%5C%2C%7C%5C%2CE_p%5BA%5D%3D0%5C%7D%7E.+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
One sees immediately that unlike 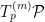 , depends on
, depends on  , and therefore parallel transport does not preserve . However, while an element
, and therefore parallel transport does not preserve . However, while an element  does not generally belong to
does not generally belong to  for
for 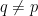 , the constraint in (7) implies that the shifted vector
, the constraint in (7) implies that the shifted vector ![{A'\equiv A-E_q[A]}](https://s0.wp.com/latex.php?latex=%7BA%27%5Cequiv+A-E_q%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) does belong to . We therefore have
does belong to . We therefore have
![\displaystyle \Pi_{p,q}^{(e)}X=X'\;\;\mathrm{such~that}\;\;{X'}^{(e)}=X^{(e)}-E_q[X^{(e)}]~, \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPi_%7Bp%2Cq%7D%5E%7B%28e%29%7DX%3DX%27%5C%3B%5C%3B%5Cmathrm%7Bsuch%7Ethat%7D%5C%3B%5C%3B%7BX%27%7D%5E%7B%28e%29%7D%3DX%5E%7B%28e%29%7D-E_q%5BX%5E%7B%28e%29%7D%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  denotes parallel transport with respect to the e-connection
denotes parallel transport with respect to the e-connection  . (Properly showing that is e-parallel under (9) is of course slightly more involved, and is done on page 41). Thus the exponential (or, if one prefers, logarithmic) embedding of into
. (Properly showing that is e-parallel under (9) is of course slightly more involved, and is done on page 41). Thus the exponential (or, if one prefers, logarithmic) embedding of into  leads naturally to the e-affine coordinate system and associated connection introduced in the previous post.
leads naturally to the e-affine coordinate system and associated connection introduced in the previous post.
It turns out that the e-representation has a number of interesting properties that allow one to establish close connections between the Fisher metric and various statistical notions. Note that, due to the presence of the log, the Fisher metric can be neatly expressed in the e-representation as
![\displaystyle \langle X,Y\rangle_p=E_p\left[X^{(e)}Y^{(e)}\right]~. \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+X%2CY%5Crangle_p%3DE_p%5Cleft%5BX%5E%7B%28e%29%7DY%5E%7B%28e%29%7D%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
Furthermore, with a bit more technical footwork involving cotangent spaces and the like, one can derive a number of fundamental relations. For example, the variance of a random variable is determined by the sensitivity of ![{E_p[A]}](https://s0.wp.com/latex.php?latex=%7BE_p%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to perturbations of , and may be expressed as
to perturbations of , and may be expressed as
![\displaystyle V_p[A]=E_p[(A-E_p[A])^2]=||(\mathrm{d} E[A])_p||_p^2~, \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_p%5BA%5D%3DE_p%5B%28A-E_p%5BA%5D%29%5E2%5D%3D%7C%7C%28%5Cmathrm%7Bd%7D+E%5BA%5D%29_p%7C%7C_p%5E2%7E%2C+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  is the differential of
is the differential of  at . See section 2.5 for more details.
at . See section 2.5 for more details.
As alluded previously, the geometrical arguments are somewhat less rigorous for the case when is infinite. Intuitively, the issue is that the identification of with , and by extension the isometry between and , requires that have the same dimensionality as . For finite , the constraint  is “loose enough” for this to be possible, but this constraint becomes increasingly strict as the cardinality of increases (i.e., the portion of identified with decreases). For infinite , one effectively has an infinite number of constraints, which makes this dimensional matching impossible. Nonetheless, I’m given to understand that much of the framework can still be made to go through; see the references at the end of section 2.5 and associated discussion.
is “loose enough” for this to be possible, but this constraint becomes increasingly strict as the cardinality of increases (i.e., the portion of identified with decreases). For infinite , one effectively has an infinite number of constraints, which makes this dimensional matching impossible. Nonetheless, I’m given to understand that much of the framework can still be made to go through; see the references at the end of section 2.5 and associated discussion.
Dual structures on
We’ve alluded to a duality between 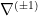 , but in fact this extends to general -connections. Hence, rather than consider a particular connection in isolation, the fundamental structure in information geometry is the triple
, but in fact this extends to general -connections. Hence, rather than consider a particular connection in isolation, the fundamental structure in information geometry is the triple  , which Amari & Nagaoka call a dualistic structure on (we prefer the term “dual structure” instead, and will use this henceforth). Formally, if one has two affine connections
, which Amari & Nagaoka call a dualistic structure on (we prefer the term “dual structure” instead, and will use this henceforth). Formally, if one has two affine connections 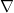 and
and  with respect to a Riemannian metric
with respect to a Riemannian metric  , then if these satisfy
, then if these satisfy

then and are duals with respect to , and one is called the dual or conjugate connection of the other. In local coordinates, this condition reads

which follows from the definition 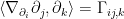 , and similarly for , with basis vectors
, and similarly for , with basis vectors  etc. Given a metric and connection on , the dual connection is generally unique, and satisfies
etc. Given a metric and connection on , the dual connection is generally unique, and satisfies 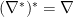 . Additionally, the combination
. Additionally, the combination 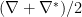 is metric. Conversely, one immediately sees that the condition for to be metric is that
is metric. Conversely, one immediately sees that the condition for to be metric is that  , and in this sense dual connections simply constitute a more general class thereof.
, and in this sense dual connections simply constitute a more general class thereof.
In particular, and are dual with respect to the Fisher metric. This follows readily from the general expressions for the -connection developed in section 2.6, which we’ve skipped over here. Suffice to say the framework of 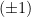 -connection admits a straightforward extension to arbitrary .
-connection admits a straightforward extension to arbitrary .
The significance of dual connections is neatly illustrated by considering the parallel transport along a curve  from
from  with respect to and , respectively denoted
with respect to and , respectively denoted 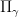 and
and  . As mentioned in the previous post, general connections are not metric; but the dual structure allows one to generalize the notion of preservation of the inner product along a curve, namely:
. As mentioned in the previous post, general connections are not metric; but the dual structure allows one to generalize the notion of preservation of the inner product along a curve, namely:
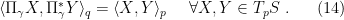
And furthermore, the relationship between and is completely fixed by this condition.
Divergences
The duality structure of statistical manifolds facilitates the introduction of a distance-like measure  , which enables us to compute something like a geometrical distance between distributions. In particular, we shall define a smooth function
, which enables us to compute something like a geometrical distance between distributions. In particular, we shall define a smooth function  such that
such that 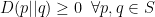 , with equality iff
, with equality iff 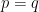 . While this provides a measure of the separation between and
. While this provides a measure of the separation between and  , it is asymmetric and does not satisfy the triangle inequality, and hence fails the conditions for a distance function. However, if further satisfies
, it is asymmetric and does not satisfy the triangle inequality, and hence fails the conditions for a distance function. However, if further satisfies

where ![{[g_{ij}^{(D)}]}](https://s0.wp.com/latex.php?latex=%7B%5Bg_%7Bij%7D%5E%7B%28D%29%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is a positive definite matrix everywhere on , then is a divergence or contrast function on . Note that a divergence uniquely defines a Riemannian metric
is a positive definite matrix everywhere on , then is a divergence or contrast function on . Note that a divergence uniquely defines a Riemannian metric  via
via
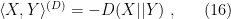
i.e.,  . We can also define an affine connection
. We can also define an affine connection  associated with this divergence, via the coefficients
associated with this divergence, via the coefficients 
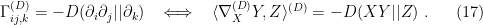
Similarly, we define the dual 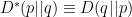 , from which we have
, from which we have 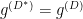 and
and  . Thus we have that and
. Thus we have that and  are dual with respect to
are dual with respect to  . In fact, any dual structure
. In fact, any dual structure 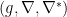 is naturally induced from a divergence!
is naturally induced from a divergence!
Of course, the above is quite general: there are infinitely many different divergences one could define on a manifold. Henceforth we shall specify to a particularly important class for statistical models, known as the f-divergence:

where  is an arbitrary convex function on
is an arbitrary convex function on  with
with 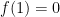 . The f-divergence satisfies a number of important properties (see page 56), chief of which is monotonicity under arbitrary probability transition functions. That is, let
. The f-divergence satisfies a number of important properties (see page 56), chief of which is monotonicity under arbitrary probability transition functions. That is, let 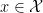 be randomly transformed into
be randomly transformed into 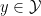 with probability
with probability 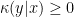 , with
, with  . This maps distributions
. This maps distributions  to
to  , respectively. Monotonicity of the f-divergence is then the statement that
, respectively. Monotonicity of the f-divergence is then the statement that

Spoiler alert: this will surface again in the form of monotonicity of relative entropy below! Note that  is a generalization of the deterministic mapping induced by
is a generalization of the deterministic mapping induced by  in the previous post, which corresponds to
in the previous post, which corresponds to 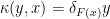 . Consequently, the equality is saturated iff is induced from a sufficient statistic, for which
. Consequently, the equality is saturated iff is induced from a sufficient statistic, for which 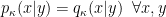 .
.
Within this still-broad class of f-divergences, one finds the -divergence  , defined for all
, defined for all 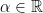 via
via

which yields, for 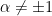 ,
,

and, for 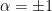 ,
,
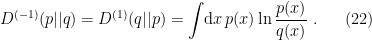
Of course, this last is none other than the relative entropy or Kullback-Leibler divergence!
The -divergence  is so named because it naturally induces the dual structure , i.e., the Fisher metric and (dual) -connections. Let us now explore this duality in more detail, which will lead us to a deeper appreciation for the divergence .
is so named because it naturally induces the dual structure , i.e., the Fisher metric and (dual) -connections. Let us now explore this duality in more detail, which will lead us to a deeper appreciation for the divergence .
Dually flat spaces
Suppose that, in a dual structure , both connections are symmetric, as is the case for -connections. This implies that -flatness and 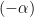 -flatness of are equivalent. In particular, we’ve seen that e-families are 1-flat, and m-families are
-flatness of are equivalent. In particular, we’ve seen that e-families are 1-flat, and m-families are 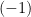 -flat, but the above implies that in fact they are both -flat. In general, if both duals and are flat, we call
-flat, but the above implies that in fact they are both -flat. In general, if both duals and are flat, we call  a dually flat space. Such spaces have a number of properties that are closely related to various concepts in statistics.
a dually flat space. Such spaces have a number of properties that are closely related to various concepts in statistics.
By definition, there exist -affine and -affine coordinate systems ![{[\theta^i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctheta%5Ei%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{[\eta_j]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ceta_j%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , respectively, in which vector fields are denoted
, respectively, in which vector fields are denoted  and
and  . Since both and
. Since both and  are flat, the condition on parallel transport (14) implies that
are flat, the condition on parallel transport (14) implies that  is in fact constant on . Furthermore, given , affine transformations allow us to choose the dual coordinate system
is in fact constant on . Furthermore, given , affine transformations allow us to choose the dual coordinate system ![{[\eta^j]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ceta%5Ej%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that

Coordinate systems which satisfy this requirement are called mutually dual. Such coordinate systems are special to dually flat spaces, and do not exist for general Riemannian manifolds; conversely, if one finds such coordinates for a Riemannian manifold  , then the connections and for which they are affine are uniquely determined, and is a dually flat space.
, then the connections and for which they are affine are uniquely determined, and is a dually flat space.
A quick remark on notation: we shall denote the components of the metric with respect to and by
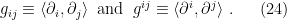
Coordinate transformations between them are given by the usual expressions,

In conjunction with (23), we therefore have
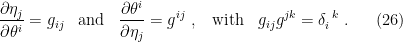
We may now introduce the potentials, which will prove useful below. At a mathematical level, these allow us to define the Legendre transformation that explicitly relates the dual coordinate systems and . Consider a function  that satisfies the following partial differential equation:
that satisfies the following partial differential equation:

From the coordinate expressions above, 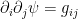 , and hence the second derivatives of
, and hence the second derivatives of  comprise a positive definite matrix. Hence is a strictly convex function of . Similarly, define
comprise a positive definite matrix. Hence is a strictly convex function of . Similarly, define 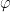 such that
such that

which is a strictly convex function of , since  . These two functions are related via
. These two functions are related via
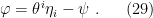
To see this, simply take the differential  , whereupon substituting in (27) one recovers (28). Now, the form of (29) — equivalently, the pair (27) and (28) — suggests that , form a conjugate pair of coordinates for the functions , in the context of Legendre transforms. However, (29) does not quite suffice to define the Legendre transform, since we must remove the
, whereupon substituting in (27) one recovers (28). Now, the form of (29) — equivalently, the pair (27) and (28) — suggests that , form a conjugate pair of coordinates for the functions , in the context of Legendre transforms. However, (29) does not quite suffice to define the Legendre transform, since we must remove the  dependence on the right-hand side in order for it to be uniquely invertible. Note that (strict) convexity is important here, since this implies a 1:1 map between a function and its first derivative, which in turn enables one — via the Legendre transform — to express all the information about a function in terms of its derivatives instead. By analogy with Fourier or Laplace transforms, this may lead to deeper mathematical/physical insight, or simple convenience, depending on the application. Hence, since we’re dealing with strictly convex functions, we define the Legendre transforms
dependence on the right-hand side in order for it to be uniquely invertible. Note that (strict) convexity is important here, since this implies a 1:1 map between a function and its first derivative, which in turn enables one — via the Legendre transform — to express all the information about a function in terms of its derivatives instead. By analogy with Fourier or Laplace transforms, this may lead to deeper mathematical/physical insight, or simple convenience, depending on the application. Hence, since we’re dealing with strictly convex functions, we define the Legendre transforms
![\displaystyle \varphi(q)=\mathrm{sup}_{p\in S}\left[\theta^i(p)\eta_i(q)-\psi(p)\right]\quad\mathrm{and}\quad \psi(p)=\mathrm{sup}_{q\in S}\left[\theta^i(p)\eta_i(q)-\varphi(q)\right]~. \ \ \ \ \ (30)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvarphi%28q%29%3D%5Cmathrm%7Bsup%7D_%7Bp%5Cin+S%7D%5Cleft%5B%5Ctheta%5Ei%28p%29%5Ceta_i%28q%29-%5Cpsi%28p%29%5Cright%5D%5Cquad%5Cmathrm%7Band%7D%5Cquad+%5Cpsi%28p%29%3D%5Cmathrm%7Bsup%7D_%7Bq%5Cin+S%7D%5Cleft%5B%5Ctheta%5Ei%28p%29%5Ceta_i%28q%29-%5Cvarphi%28q%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2830%29&bg=ffffff&fg=000000&s=0&c=20201002)
Thus we see that the dual/conjugate coordinate systems and are related by the Legendre transform given in terms of the potentials and , which provides another explanation for the name.
Incidentally, in addition to the compact expressions for the metric above, namely

the potentials also enable one to neatly express the connection coefficients as

Now, we mentioned earlier that any divergence induces a (torsion-free) dual structure, and vice-versa. But this map is not bijective; rather, a given dual structure admits infinitely many divergences. In the case of dually flat spaces however, the potentials defined above allow us to introduce a canonical divergence which is in some sense unique, namely

which of course satisfies 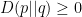 , with equality iff . To see that is a divergence which induces the metric , observe that
, with equality iff . To see that is a divergence which induces the metric , observe that

which further implies 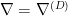 and
and  with
with 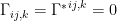 due to the -, resp. -affinity of , , where the dual divergence is
due to the -, resp. -affinity of , , where the dual divergence is  .
.
Generic properties of such canonical divergences are examined in section 3.4. Instead however, I’m going to close this post by jumping ahead to 3.5, which connects this discussion back to the e- and m-families and associated -connections we spent so much time on above.
Dual structure of exponential families
Recall that an exponential family consists of distributions of the form
![\displaystyle p(x;\theta)=\exp\left[C(x)+\theta^iF_i(x)-\psi(\theta)\right]~, \ \ \ \ \ (35)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%3B%5Ctheta%29%3D%5Cexp%5Cleft%5BC%28x%29%2B%5Ctheta%5EiF_i%28x%29-%5Cpsi%28%5Ctheta%29%5Cright%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2835%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the canonical parameters constitute a 1-affine coordinate system. The notation here was not chosen arbitrarily, but is in fact precisely the potential introduced above. This is a rather elegant fact that ties together some fundamental notions from statistics with the existence of the dual coordinates ![{[\eta_i]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ceta_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Suppose we didn’t know that
. Suppose we didn’t know that  is the dual coordinate to , and simply defined
is the dual coordinate to , and simply defined
![\displaystyle \eta_i=\eta_i(\theta)\equiv E_\theta[F_i]=\int\!\mathrm{d} x\,F_i(x)p(x;\theta)~. \ \ \ \ \ (36)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ceta_i%3D%5Ceta_i%28%5Ctheta%29%5Cequiv+E_%5Ctheta%5BF_i%5D%3D%5Cint%5C%21%5Cmathrm%7Bd%7D+x%5C%2CF_i%28x%29p%28x%3B%5Ctheta%29%7E.+%5C+%5C+%5C+%5C+%5C+%2836%29&bg=ffffff&fg=000000&s=0&c=20201002)
Then it follows that
![\displaystyle 0=E_\theta[\partial_i\ell_\theta]=E_\theta[F_i(x)-\partial_i\psi(\theta)]\;\;\implies\;\; \eta_i=\partial_i\psi~. \ \ \ \ \ (37)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+0%3DE_%5Ctheta%5B%5Cpartial_i%5Cell_%5Ctheta%5D%3DE_%5Ctheta%5BF_i%28x%29-%5Cpartial_i%5Cpsi%28%5Ctheta%29%5D%5C%3B%5C%3B%5Cimplies%5C%3B%5C%3B+%5Ceta_i%3D%5Cpartial_i%5Cpsi%7E.+%5C+%5C+%5C+%5C+%5C+%2837%29&bg=ffffff&fg=000000&s=0&c=20201002)
Additionally, the expression of the metric in the form ![{g_{ij}(\theta)=-E_\theta[\partial_i\partial_j\ell_\theta]}](https://s0.wp.com/latex.php?latex=%7Bg_%7Bij%7D%28%5Ctheta%29%3D-E_%5Ctheta%5B%5Cpartial_i%5Cpartial_j%5Cell_%5Ctheta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) implies that for an exponential family, . Thus (0.36) suffices to identify as the conjugate parameter to with respect to the Legendre potential . From the discussion above, this implies that is a -affine coordinate system dual to . Given the form of (0.36), are sometimes also referred to as the expectation parameters.
implies that for an exponential family, . Thus (0.36) suffices to identify as the conjugate parameter to with respect to the Legendre potential . From the discussion above, this implies that is a -affine coordinate system dual to . Given the form of (0.36), are sometimes also referred to as the expectation parameters.
It is a trivial exercise to work out  and
and  for the example of the normal distribution in the previous post. A more interesting example is the case when is a finite set, whence
for the example of the normal distribution in the previous post. A more interesting example is the case when is a finite set, whence 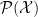 is identified with the parameters:
is identified with the parameters:
![\displaystyle \begin{aligned} \mathcal{X}=&\{x_0,\ldots,x_n\}~,\qquad \Xi=\left\{[\xi^i]\,\Big|\,\xi^i>0\;\;\forall i~,\;\;\sum_{i=1}^n\xi^i<1\right\}\\ &p(x_i;\xi)=\begin{cases} \xi^i & 1\leq i\leq n \\ 1-\sum_{i=1}^n\xi^i\quad & i=0 \end{cases}~. \end{aligned} \ \ \ \ \ (38)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathcal%7BX%7D%3D%26%5C%7Bx_0%2C%5Cldots%2Cx_n%5C%7D%7E%2C%5Cqquad+%5CXi%3D%5Cleft%5C%7B%5B%5Cxi%5Ei%5D%5C%2C%5CBig%7C%5C%2C%5Cxi%5Ei%3E0%5C%3B%5C%3B%5Cforall+i%7E%2C%5C%3B%5C%3B%5Csum_%7Bi%3D1%7D%5En%5Cxi%5Ei%3C1%5Cright%5C%7D%5C%5C+%26p%28x_i%3B%5Cxi%29%3D%5Cbegin%7Bcases%7D+%5Cxi%5Ei+%26+1%5Cleq+i%5Cleq+n+%5C%5C+1-%5Csum_%7Bi%3D1%7D%5En%5Cxi%5Ei%5Cquad+%26+i%3D0+%5Cend%7Bcases%7D%7E.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%2838%29&bg=ffffff&fg=000000&s=0&c=20201002)
(This is introduced as example 2.4 on page 27, and resurfaces as example 2.8 on page 35 and example 3.4 on page 66). Expressing this as an exponential family of the form (0.35) implies the parameter identifications
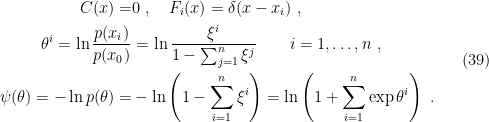
Then the dual coordinates are simply given by the parameters themselves:

Therefore, the dual potential (29) is
![\displaystyle \varphi(\theta)=E_\theta[\ln p_\theta-C]=-H(p_\theta)-E_\theta[C]~, \ \ \ \ \ (41)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvarphi%28%5Ctheta%29%3DE_%5Ctheta%5B%5Cln+p_%5Ctheta-C%5D%3D-H%28p_%5Ctheta%29-E_%5Ctheta%5BC%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2841%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 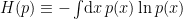 is the entropy!
is the entropy!
Finally, I promised you some statistical notions, which requires the introduction of one more concept, namely that of an estimator. Suppose that some data  is generated according to some unknown probability distribution
is generated according to some unknown probability distribution  . We wish to consider the problem of estimating the unknown parameter
. We wish to consider the problem of estimating the unknown parameter  by some function
by some function  of the data . The mapping
of the data . The mapping ![{[\hat\xi^i]:\mathcal{X}\rightarrow\mathbb{R}^n}](https://s0.wp.com/latex.php?latex=%7B%5B%5Chat%5Cxi%5Ei%5D%3A%5Cmathcal%7BX%7D%5Crightarrow%5Cmathbb%7BR%7D%5En%7D&bg=ffffff&fg=000000&s=0&c=20201002) is called an estimator. Furthermore,
is called an estimator. Furthermore, 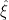 is an unbiased estimator if
is an unbiased estimator if
![\displaystyle E_\xi[\hat\xi(X)]=\xi\quad\forall\xi\in\Xi~, \ \ \ \ \ (42)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%5Cxi%5B%5Chat%5Cxi%28X%29%5D%3D%5Cxi%5Cquad%5Cforall%5Cxi%5Cin%5CXi%7E%2C+%5C+%5C+%5C+%5C+%5C+%2842%29&bg=ffffff&fg=000000&s=0&c=20201002)
which is the statement that the expectation value of does not depend on the data itself. The mean-squared error of such an estimator may be expressed via the variance-covariance matrix ![{V_\xi[\hat\xi]=[v_\xi^{ij}]}](https://s0.wp.com/latex.php?latex=%7BV_%5Cxi%5B%5Chat%5Cxi%5D%3D%5Bv_%5Cxi%5E%7Bij%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , whose elements are defined via
, whose elements are defined via
![\displaystyle v_\xi^{ij}\equiv E_\xi\left[(\hat\xi^i(X)-\xi^i)(\hat\xi^j(X)-\xi^j)\right]~. \ \ \ \ \ (43)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%5Cxi%5E%7Bij%7D%5Cequiv+E_%5Cxi%5Cleft%5B%28%5Chat%5Cxi%5Ei%28X%29-%5Cxi%5Ei%29%28%5Chat%5Cxi%5Ej%28X%29-%5Cxi%5Ej%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%2843%29&bg=ffffff&fg=000000&s=0&c=20201002)
Lastly, the Cramér-Rao inequality (Theorem 2.2) states that the variance-covariance matrix of an unbiased estimator satisfies
![\displaystyle V_\xi[\hat\xi]\geq G(\xi)^{-1}~, \ \ \ \ \ (44)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_%5Cxi%5B%5Chat%5Cxi%5D%5Cgeq+G%28%5Cxi%29%5E%7B-1%7D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2844%29&bg=ffffff&fg=000000&s=0&c=20201002)
i.e., the difference ![{V_\xi[\hat\xi]-G(\xi)^{-1}}](https://s0.wp.com/latex.php?latex=%7BV_%5Cxi%5B%5Chat%5Cxi%5D-G%28%5Cxi%29%5E%7B-1%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is a positive semidefinite matrix. An unbiased estimator which saturates this inequality for all is an efficient estimator, which means it has the minimum variance among all unbiased estimators (note however that the converse is not always true).
is a positive semidefinite matrix. An unbiased estimator which saturates this inequality for all is an efficient estimator, which means it has the minimum variance among all unbiased estimators (note however that the converse is not always true).
Efficient estimators do not exist for arbitrary coordinates . Rather, a necessary and sufficient condition for a model  to have an efficient estimator is that be an exponential family, for which is m-affine (Theorem 3.12).
to have an efficient estimator is that be an exponential family, for which is m-affine (Theorem 3.12).
To illustrate this, let us now regard  as an estimator for the parameter
as an estimator for the parameter 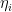 , which we shall henceforth denote
, which we shall henceforth denote 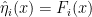 to make contact with the notation just introduced. Then the condition (0.36) implies that
to make contact with the notation just introduced. Then the condition (0.36) implies that  is in fact an unbiased estimator for . Furthermore, since the Fisher information matrix can be expressed in terms of
is in fact an unbiased estimator for . Furthermore, since the Fisher information matrix can be expressed in terms of  and as
and as
![\displaystyle g_{ij}(\theta)=E_\theta[(F_i-\eta_i)(F_j-\eta_j)]~, \ \ \ \ \ (45)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7Bij%7D%28%5Ctheta%29%3DE_%5Ctheta%5B%28F_i-%5Ceta_i%29%28F_j-%5Ceta_j%29%5D%7E%2C+%5C+%5C+%5C+%5C+%5C+%2845%29&bg=ffffff&fg=000000&s=0&c=20201002)
it follows that ![{V_\eta[\hat\eta]=G=[g_{ij}]}](https://s0.wp.com/latex.php?latex=%7BV_%5Ceta%5B%5Chat%5Ceta%5D%3DG%3D%5Bg_%7Bij%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and hence is an efficient estimator for the (m-affine) coordinate system .
, and hence is an efficient estimator for the (m-affine) coordinate system .
The above is of course only a superficial hint of the deeper connections between information geometry and statistics (which was, after all, the prime impetus for the former’s development), but already suggests interesting mathematical utility for such problems as maximum likelihood estimation (MLE), and machine learning in general. Alas, that’s a topic for another post.
As a final comment: everything I’ve said so far is for classical probability distributions, but much of this machinery can be extended to quantum mechanics as well (insofar as the latter can be viewed as an extension of probability theory). Quantum information geometry is briefly introduced in chapter 7, and I hope to return to it in part 3 of this series soon.


These three posts are a wonderful review of information geometry! Thanks so much!
A quick note, in equation (30), I think the RHS of the left expression should have a psi instead of a phi.
LikeLike
Thanks JG, I’m delighted you found them helpful!
Whoops, indeed that’s a typo; fixed now. Thanks for the catch!
LikeLike